हमारे पास लगभग 30k पंक्तियों वाली एक तालिका थी (एक विशिष्ट असंबंधित वास्तुशिल्प कारण के लिए) यूयूआईडी को टेक्स्ट फ़ील्ड में संग्रहीत और अनुक्रमित किया गया था। मैंने देखा कि क्वेरी परफ़ मेरी अपेक्षा से धीमी थी। मैंने एक नया यूयूआईडी कॉलम बनाया है, जिसे यूयूआईडी प्राथमिक कुंजी टेक्स्ट में कॉपी किया गया है और नीचे तुलना की गई है। 2.652ms बनाम 0.029ms। काफी अंतर!
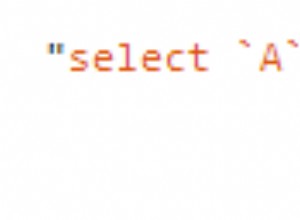
-- With text index
QUERY PLAN
Index Scan using tmptable_pkey on tmptable (cost=0.41..1024.34 rows=1 width=1797) (actual time=0.183..2.632 rows=1 loops=1)
Index Cond: (primarykey = '755ad490-9a34-4c9f-8027-45fa37632b04'::text)
Planning time: 0.121 ms
Execution time: 2.652 ms
-- With a uuid index
QUERY PLAN
Index Scan using idx_tmptable on tmptable (cost=0.29..2.51 rows=1 width=1797) (actual time=0.012..0.013 rows=1 loops=1)
Index Cond: (uuidkey = '755ad490-9a34-4c9f-8027-45fa37632b04'::uuid)
Planning time: 0.109 ms
Execution time: 0.029 ms