दो गंभीर सुरक्षा भेद्यताएं (कोड नाम मेल्टडाउन और स्पेक्टर) कुछ हफ़्ते पहले सामने आई थीं। प्रारंभिक परीक्षणों ने सुझाव दिया कि सिस्कल दर के आधार पर, कुछ कार्यभार के लिए शमन (कर्नेल में जोड़ा गया) का प्रदर्शन प्रभाव ~ 30% तक हो सकता है।
उन शुरुआती अनुमानों को जल्दी से किया जाना था, और इसलिए सीमित मात्रा में परीक्षण पर आधारित थे। इसके अलावा, इन-कर्नेल सुधार समय के साथ विकसित और बेहतर हुए, और अब हमें retpoline भी मिल गया है जिसे स्पेक्टर v2. यह पोस्ट अधिक गहन परीक्षणों से डेटा प्रस्तुत करता है, उम्मीद है कि विशिष्ट पोस्टग्रेएसक्यूएल वर्कलोड के लिए अधिक विश्वसनीय अनुमान प्रदान करता है।
मेल्टडाउन फिक्स के शुरुआती आकलन की तुलना में, जिसे साइमन ने 10 जनवरी को वापस पोस्ट किया था, इस पोस्ट में प्रस्तुत डेटा अधिक विस्तृत है लेकिन उस पोस्ट में प्रस्तुत सामान्य मिलान निष्कर्षों में है।
यह पोस्ट पोस्टग्रेएसक्यूएल वर्कलोड पर केंद्रित है, और जबकि यह उच्च सिस्कल/संदर्भ स्विच दरों वाले अन्य सिस्टम के लिए उपयोगी हो सकता है, यह निश्चित रूप से सार्वभौमिक रूप से लागू नहीं है। यदि आप कमजोरियों और प्रभाव मूल्यांकन की अधिक सामान्य व्याख्या में रुचि रखते हैं, तो ब्रेंडन ग्रेग ने कुछ दिन पहले एक उत्कृष्ट KPTI/KAISER मेल्टडाउन प्रारंभिक प्रदर्शन प्रतिगमन लेख प्रकाशित किया था। वास्तव में, पहले इसे पढ़ना और फिर इस पोस्ट को जारी रखना उपयोगी हो सकता है।
नोट: यह पोस्ट आपको सुधारों को स्थापित करने से हतोत्साहित करने के लिए नहीं है, बल्कि आपको कुछ विचार देने के लिए है कि प्रदर्शन प्रभाव क्या हो सकता है। आपको सभी सुधारों को स्थापित करना चाहिए ताकि आपका पर्यावरण सुरक्षित रहे, और इस पोस्ट का उपयोग यह तय करने के लिए करें कि क्या आपको हार्डवेयर आदि को अपग्रेड करने की आवश्यकता हो सकती है।
हम कौन से परीक्षण करेंगे?
हम दो सामान्य बुनियादी कार्यभार प्रकारों को देखेंगे - OLTP (छोटे साधारण लेनदेन) और OLAP (बड़ी मात्रा में डेटा संसाधित करने वाले जटिल प्रश्न)। अधिकांश PostgreSQL सिस्टम को इन दो कार्यभार प्रकारों के मिश्रण के रूप में तैयार किया जा सकता है।
OLTP के लिए हमने pgbench का उपयोग किया, जो कि PostgreSQL के साथ प्रदान किया जाने वाला एक प्रसिद्ध बेंचमार्किंग टूल है। हमने रीड ओनली (-S . दोनों में परीक्षण किया है ) और पढ़ना-लिखना (-N ) मोड, तीन अलग-अलग पैमानों के साथ - शेयर्ड_बफ़र्स में फ़िट होना, रैम में और रैम से बड़ा।
OLAP मामले के लिए, हमने dbt-3 बेंचमार्क का उपयोग किया, जो TPC-H के काफी करीब है, दो अलग-अलग डेटा आकारों के साथ - 10GB जो RAM में फिट बैठता है, और 50GB जो RAM से बड़ा है (इंडेक्स आदि पर विचार करते हुए)।
सभी प्रस्तुत नंबर 2x Xeon E5-2620v4, 64GB RAM और Intel SSD 750 (400GB) वाले सर्वर से आते हैं। सिस्टम GCC 7.3 के साथ संकलित कर्नेल 4.15.3 के साथ Gentoo चला रहा था (पूर्ण retpoline को सक्षम करने के लिए आवश्यक है) हल करना)। वही परीक्षण पुराने/छोटे सिस्टम पर i5-2500k CPU, 8GB RAM और 6x Intel S3700 SSD (RAID-0 में) के साथ भी किए गए थे। लेकिन व्यवहार और निष्कर्ष काफी हद तक समान हैं, इसलिए हम यहां डेटा प्रस्तुत नहीं करने जा रहे हैं।
हमेशा की तरह, दोनों प्रणालियों के लिए पूरी स्क्रिप्ट/परिणाम जीथब पर उपलब्ध हैं।
यह पोस्ट शमन के प्रदर्शन प्रभाव के बारे में है, तो आइए पूर्ण संख्याओं पर ध्यान केंद्रित न करें और इसके बजाय अप्रकाशित सिस्टम (कर्नेल शमन के बिना) के सापेक्ष प्रदर्शन को देखें। OLTP अनुभाग में सभी चार्ट प्रदर्शित होते हैं
(throughput with patches) / (throughput without patches)
हम 0% और 100% के बीच की संख्या की अपेक्षा करते हैं, जिसमें उच्च मान बेहतर होते हैं (शमन का कम प्रभाव), 100% का अर्थ है "कोई प्रभाव नहीं।"
नोट: अंतर को और अधिक दृश्यमान बनाने के लिए y-अक्ष 75% से शुरू होता है।
OLTP / केवल पढ़ने के लिए
सबसे पहले, इस कमांड द्वारा निष्पादित केवल-पढ़ने के लिए pgbench के परिणाम देखें
pgbench -n -c 16 -j 16 -S -T 1800 test
और निम्नलिखित चार्ट द्वारा सचित्र:
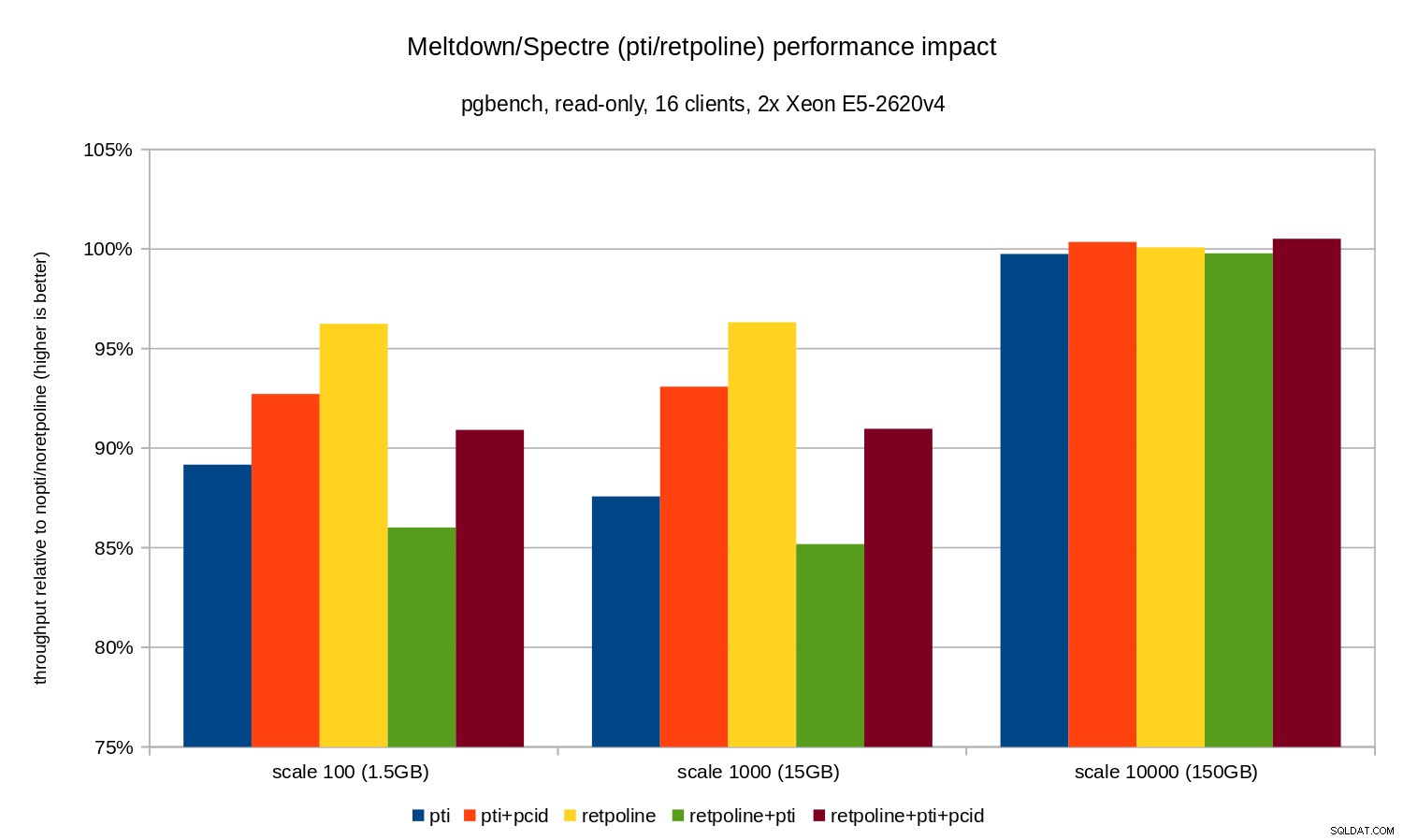
जैसा कि आप देख सकते हैं, pti . का प्रदर्शन प्रभाव स्मृति में फिट होने वाले तराजू के लिए लगभग 10-12% और लगभग गैर-मापनीय होता है जब कार्यभार I/O बाध्य हो जाता है। इसके अलावा, pcid . होने पर प्रतिगमन काफी कम हो जाता है (या पूरी तरह से गायब हो जाता है) सक्षम किया गया है। यह इस दावे के अनुरूप है कि PCID अब x86 पर एक महत्वपूर्ण प्रदर्शन/सुरक्षा सुविधा है। retpoline . का प्रभाव बहुत छोटा है - सबसे खराब स्थिति में 4% से कम, जो आसानी से शोर के कारण हो सकता है।
OLTP / पठन-लेखन
पढ़ने-लिखने के परीक्षण pgbench . द्वारा किए गए थे इस के समान आदेश:
pgbench -n -c 16 -j 16 -N -T 3600 test
कई चौकियों को कवर करने के लिए अवधि काफी लंबी थी, और -N (छोटी) शाखा तालिका में पंक्तियों पर ताला विवाद को खत्म करने के लिए इस्तेमाल किया गया था। सापेक्ष प्रदर्शन इस चार्ट द्वारा दिखाया गया है:
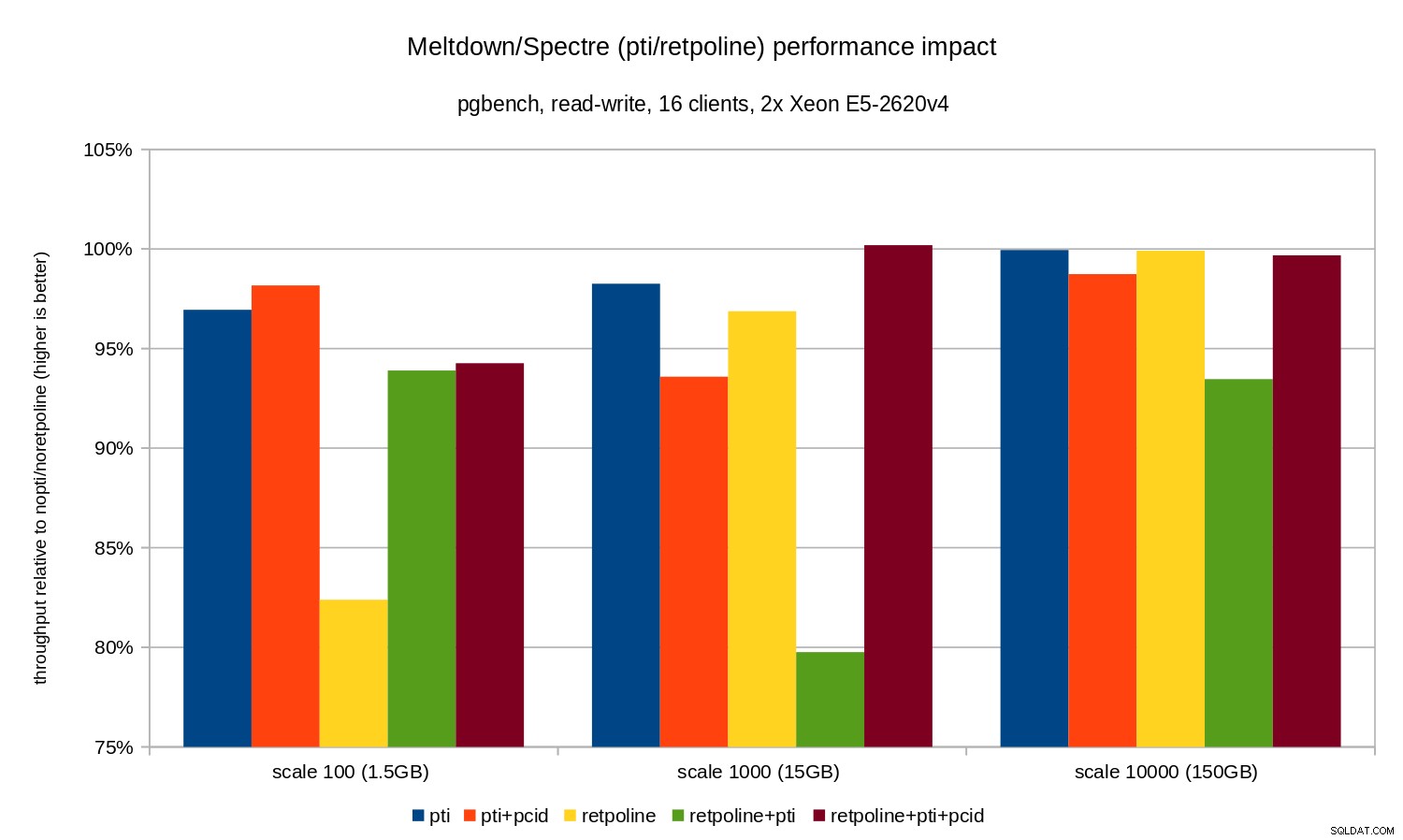
रिग्रेशन केवल-पढ़ने के मामले की तुलना में थोड़ा छोटा है - बिना pcid के 8% से कम और 3% से कम pcid . के साथ सक्षम। यह WAL को डेटा लिखते समय I/O करने में अधिक समय व्यतीत करने, चेकपॉइंट के दौरान संशोधित बफ़र्स को फ्लश करने आदि का एक स्वाभाविक परिणाम है।
हालांकि, दो अजीब बिट्स हैं। सबसे पहले, retpoline . का प्रभाव स्केल 100 के लिए अप्रत्याशित रूप से बड़ा (20% के करीब) है, और retpoline+pti के लिए भी यही हुआ। 1000 के पैमाने पर। कारण बिल्कुल स्पष्ट नहीं हैं और इसके लिए अतिरिक्त जांच की आवश्यकता होगी।
OLAP
विश्लेषण कार्यभार डीबीटी-3 बेंचमार्क द्वारा तैयार किया गया था। सबसे पहले, आइए स्केल 10GB परिणामों को देखें, जो पूरी तरह से RAM में फिट बैठता है (सभी इंडेक्स आदि सहित)। इसी तरह OLTP की तरह हम वास्तव में निरपेक्ष संख्याओं में रुचि नहीं रखते हैं, जो इस मामले में व्यक्तिगत प्रश्नों के लिए अवधि होगी। इसके बजाय हम nopti/noretpoline . की तुलना में मंदी को देखेंगे , वह है:
(duration without patches) / (duration with patches)
यह मानते हुए कि शमन परिणाम में मंदी है, हम 0% और 100% के बीच मान प्राप्त करेंगे जहाँ 100% का अर्थ है "कोई प्रभाव नहीं"। परिणाम इस तरह दिखते हैं:
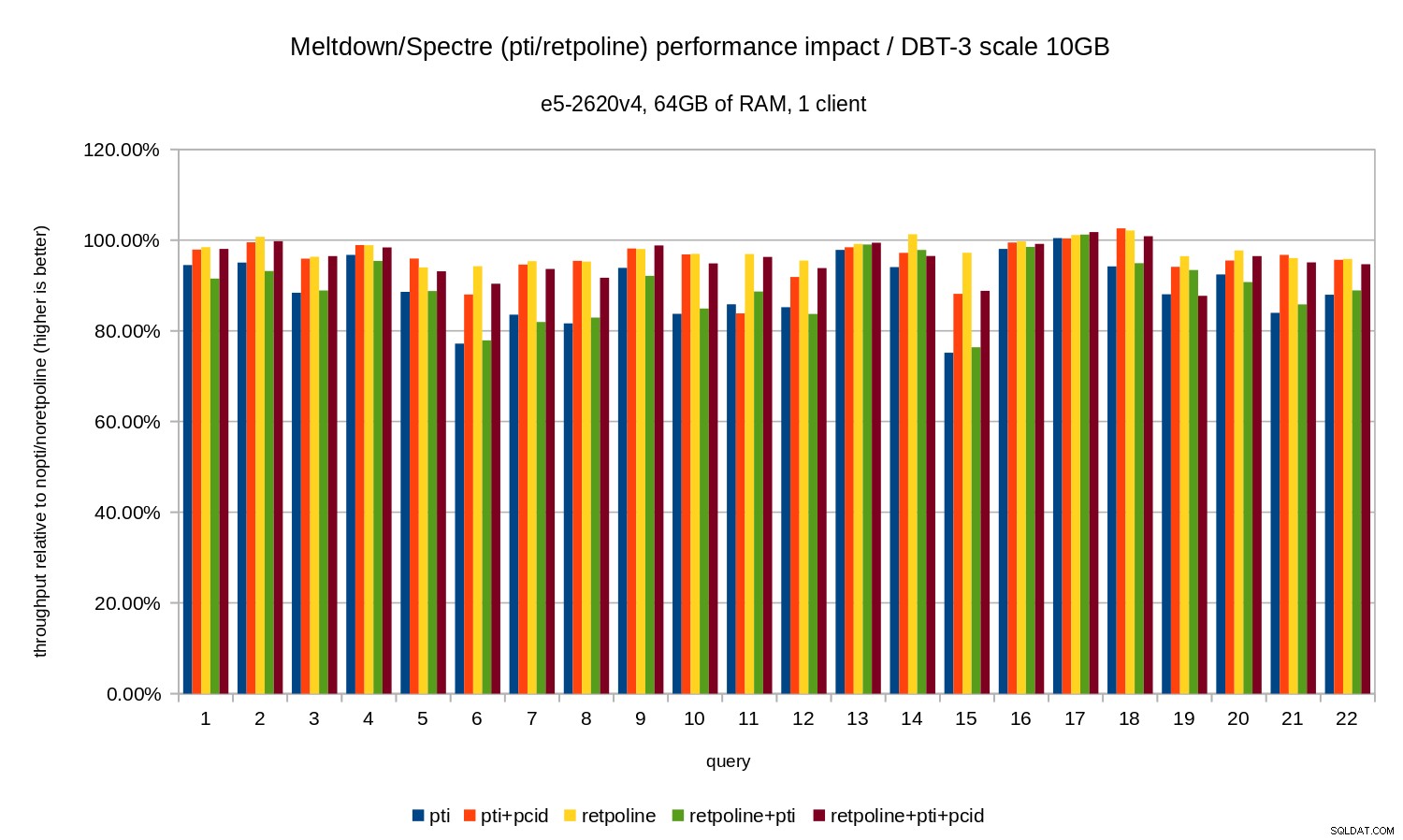
यानी बिना pcid . के रिग्रेशन आम तौर पर क्वेरी के आधार पर 10-20% रेंज में होता है। और pcid . के साथ प्रतिगमन 5% से कम (और आम तौर पर 0% के करीब) तक गिर जाता है। एक बार फिर, यह pcid . के महत्व की पुष्टि करता है सुविधा।
50GB डेटा सेट (जो सभी इंडेक्स आदि के साथ लगभग 120GB है) के लिए प्रभाव इस तरह दिखता है:
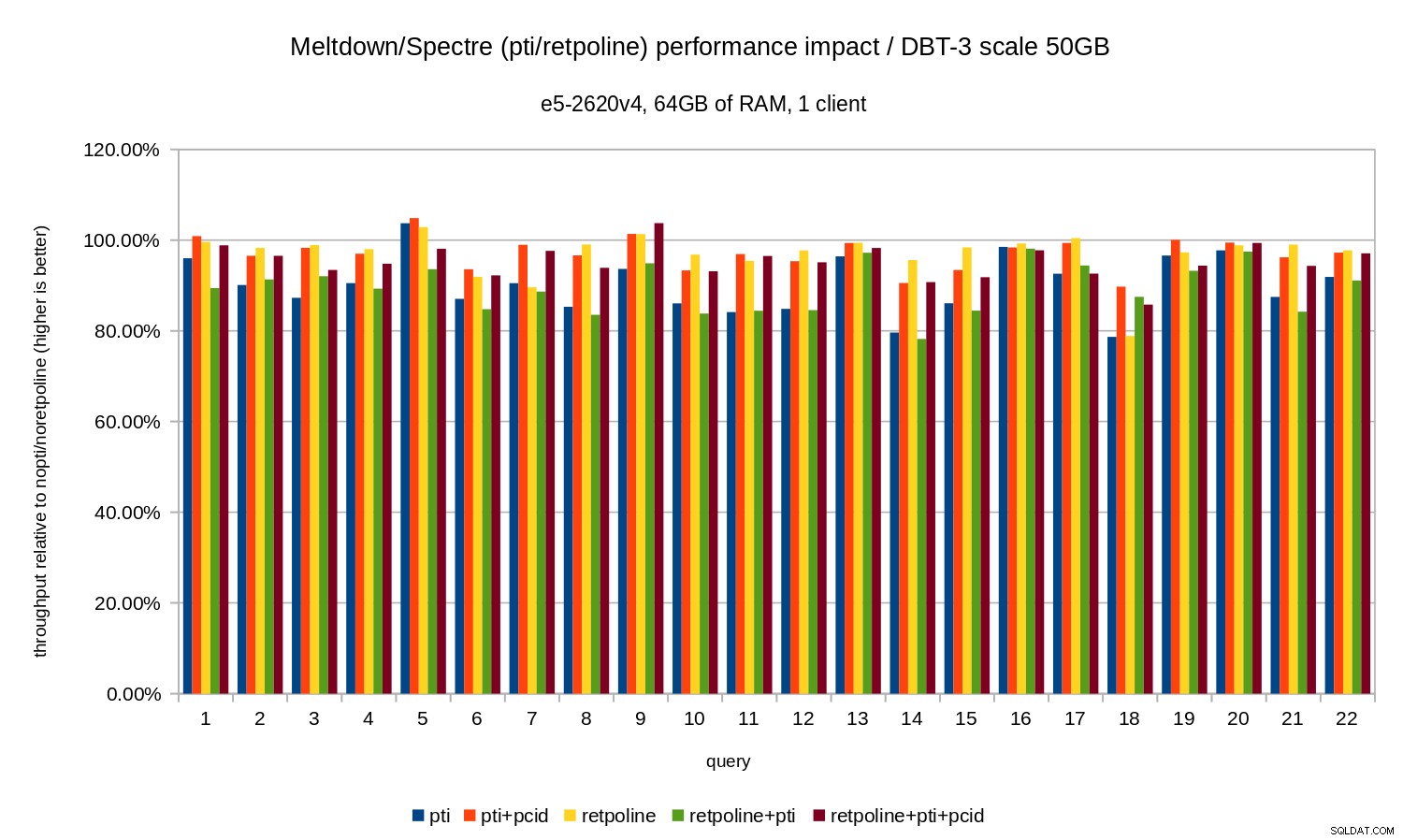
तो जैसे 10जीबी के मामले में, प्रतिगमन 20% से कम है और pcid उन्हें काफी कम कर देता है - ज्यादातर मामलों में 0% के करीब।
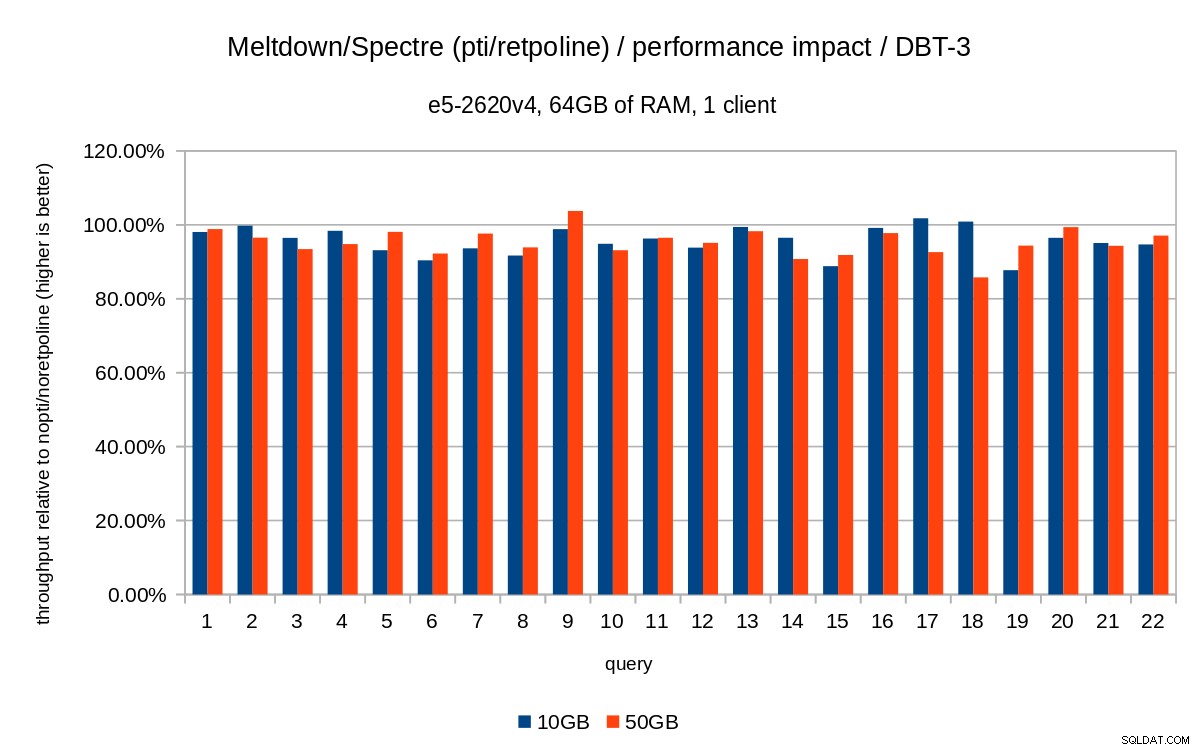
पिछले चार्ट थोड़े अव्यवस्थित हैं - 22 प्रश्न और 5 डेटा श्रृंखलाएं हैं, जो एक चार्ट के लिए बहुत अधिक है। तो यहाँ एक चार्ट है जो केवल तीनों विशेषताओं के लिए प्रभाव दिखा रहा है (pti , pcid और retpoline ), दोनों डेटा सेट आकारों के लिए।
निष्कर्ष
परिणामों को संक्षेप में सारांशित करने के लिए:
retpolineबहुत कम प्रदर्शन प्रभाव पड़ता है- OLTP -
pcid. के बिना प्रतिगमन लगभग 10-15% है , और लगभग 1-5%pcid. के साथ । - OLAP -
pcid. के बिना प्रतिगमन 20% तक है , और लगभग 1-5%pcid. के साथ । - I/O बाध्य कार्यभार (उदाहरण के लिए सबसे बड़े डेटासेट के साथ OLTP) के लिए, मेल्टडाउन का नगण्य प्रभाव पड़ता है।
कम से कम परीक्षण किए गए कार्यभार के लिए प्रारंभिक अनुमानों (30%) की तुलना में प्रभाव बहुत कम प्रतीत होता है। कई सिस्टम पीक आवर्स में 70-80% CPU पर काम कर रहे हैं, और 30% CPU क्षमता को पूरी तरह से संतृप्त कर देंगे। लेकिन व्यवहार में यह प्रभाव 5% से कम प्रतीत होता है, कम से कम जब pcid विकल्प का उपयोग किया जाता है।
मुझे गलत मत समझो, 5% की गिरावट अभी भी एक गंभीर प्रतिगमन है। यह निश्चित रूप से कुछ ऐसा है जिसे हम PostgreSQL विकास के दौरान ध्यान रखेंगे, उदा। प्रस्तावित पैच के प्रभाव का मूल्यांकन करते समय। लेकिन यह कुछ ऐसा है जिसे मौजूदा सिस्टम को ठीक से संभालना चाहिए - यदि CPU उपयोग में 5% की वृद्धि आपके सिस्टम को उदाहरण के लिए ले जाती है, तो आपके पास मेल्टडाउन / स्पेक्टर के बिना भी समस्याएँ हैं।
जाहिर है, यह मेल्टडाउन/स्पेक्टर फिक्स का अंत नहीं है। कर्नेल डेवलपर्स अभी भी सुरक्षा में सुधार और नए जोड़ने पर काम कर रहे हैं, और इंटेल और अन्य सीपीयू निर्माता माइक्रोकोड अपडेट पर काम कर रहे हैं। और ऐसा नहीं है कि हम कमजोरियों के सभी संभावित रूपों के बारे में जानते हैं, क्योंकि शोधकर्ता हमलों के नए रूपों को खोजने में कामयाब रहे।
इसलिए अभी बहुत कुछ होना बाकी है और यह देखना दिलचस्प होगा कि प्रदर्शन पर क्या प्रभाव पड़ेगा।