PostgreSQL बल्कि लंबवत रूप से स्केल कर सकता है। आप अपने PostgreSQL सर्वर को जितने अधिक संसाधन (CPU, मेमोरी, डिस्क) उपलब्ध करा सकते हैं, वह उतना ही बेहतर प्रदर्शन कर सकता है। हालाँकि, पोस्टग्रेज़ के कुछ हिस्से स्वचालित रूप से बढ़े हुए संसाधनों का उपयोग कर सकते हैं, अन्य भागों को सुधारों पर ध्यान देने से पहले कॉन्फ़िगरेशन परिवर्तन की आवश्यकता होती है।
इस बारे में अधिक जानने के लिए पढ़ें कि कैसे सुनिश्चित किया जाए कि PostgreSQL उस सिस्टम का पूरा उपयोग करे जिस पर आप इसे चला रहे हैं।
CPU
क्या स्केल अपने आप होता है
PostgreSQL में एक पारंपरिक प्रक्रिया वास्तुकला है, जिसमें एक मास्टरप्रोसेस (पोस्टमास्टर . कहा जाता है) शामिल है ) जो एक नई प्रक्रिया को जन्म देता है (जिसे बैकएंड . कहा जाता है) ) प्रत्येक नए क्लाइंट कनेक्शन के लिए। इसका मतलब यह है कि यदि अधिक सीपीयू कोर उपलब्ध हैं, तो अधिक प्रक्रियाएं एक साथ चल सकती हैं, और इसलिए बैकएंड को सीपीयू उपलब्धता के लिए ज्यादा संघर्ष नहीं करना पड़ता है। सीपीयू से जुड़ी क्वेरी तेज़ी से पूरी होंगी.
आप सिस्टम-व्यापी, प्रति-डेटाबेस या प्रति-उपयोगकर्ता स्तर पर अधिकतम अनुमत एक साथ कनेक्शन को समायोजित करना चाह सकते हैं:
-- system level
ALTER SYSTEM SET max_connections = 200;
-- database level
ALTER DATABASE dbname CONNECTION LIMIT 200;
-- user level
ALTER ROLE username CONNECTION LIMIT 20;ताकि दुष्ट ऐप्स बहुत अधिक कनेक्शनों को बंद न कर सकें।
ट्वीकिंग की क्या आवश्यकता है
PostgreSQL सर्वर हाउसकीपिंग कार्यों, जैसे वैक्यूमिंग, प्रतिकृति, सदस्यता (तार्किक प्रतिकृति के लिए) आदि की देखभाल करने के लिए प्रक्रिया को जन्म दे सकता है। ऐसे श्रमिकों की संख्या गतिशील रूप से निर्धारित नहीं की जाती है, लेकिन केवल कॉन्फ़िगरेशन के माध्यम से सेट की जाती है, और डिफ़ॉल्ट रूप से 8.
कार्यकर्ता प्रक्रिया की संख्या के लिए शीर्ष-स्तरीय कॉन्फ़िगरेशन सेटिंग है:
# typically specified in postgresql.conf
max_worker_processes = 16इस मान को बढ़ाना कर सकते हैं रखरखाव कार्य, समानांतर क्वेरी और अनुक्रमणिका निर्माण की गति में परिणाम।
समानांतर क्वेरी
संस्करण 9.6 से शुरू होकर, यदि क्वेरी प्लानर तय करता है कि यह मदद करेगा, तो पोस्टग्रेज समानांतर रूप से प्रश्नों को निष्पादित कर सकता है। समानांतर पूछताछ में श्रमिकों को पैदा करना, उनके बीच काम बांटना और फिर परिणाम एकत्रित करना (इकट्ठा करना) शामिल है। max_worker_processes की समग्र सीमा के अधीन पहले सेट किया गया था, Postgres यह निर्धारित करेगा कि दो कॉन्फ़िगरेशन सेटिंग्स के मान के आधार पर समानांतर क्वेरी के लिए कितने श्रमिकों को उत्पन्न किया जा सकता है:
# the maximum number of workers that the system can
# support for parallel operations
max_parallel_workers = 8
# the maximum number of workers that can be started
# by a single Gather or Gather Merge node
max_parallel_workers_per_gather = 8यदि आपके पास निष्क्रिय CPU और समानांतर क्वेरी हैं, तो इन मानों को बढ़ाने से ऐसी क्वेरी को गति मिल सकती है।
समानांतर अनुक्रमणिका निर्माण
पोस्टग्रेज 11 में, बी-ट्री इंडेक्स के समानांतर निर्माण के लिए समर्थन जोड़ा गया था। यदि आप नियमित रूप से बी-ट्री इंडेक्स बनाते हैं या उन्हें रीइंडेक्स करते हैं, तो इस मान को बढ़ाने से मदद मिल सकती है:
# the maximum number of parallel workers that can be
# started by a single utility command
max_parallel_maintenance_workers = 8
यह पोस्टग्रेज़ को इन कई श्रमिकों को पैदा करने की अनुमति देगा (max_worker_processes की समग्र सीमा के अधीन) ) बी-ट्री इंडेक्स के निर्माण में तेजी लाने के लिए।
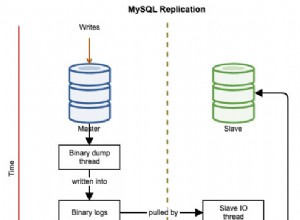
तार्किक प्रतिकृति
तार्किक प्रतिकृति (पोस्टग्रेज 10 और इसके बाद के संस्करण में उपलब्ध), प्रकाशक से परिवर्तन लाने के लिए सदस्यता पक्ष में कार्यकर्ता प्रक्रियाओं पर निर्भर करती है। अधिक तार्किक प्रतिकृति श्रमिकों को उत्पन्न करने के लिए पोस्टग्रेज को बायस्किंग करके, परिवर्तनों को समानांतर में लागू किया जा सकता है, खासकर यदि अधिक टेबल हैं। यह कॉन्फ़िगरेशन सेटिंग प्रतिकृति कार्यकर्ताओं की कुल संख्या को बढ़ाती है:
# maximum number of logical replication workers
max_logical_replication_workers = 8स्ट्रीमिंग प्रतिकृति में, आप एक बेस बैकअप के साथ एक सिंक शुरू कर सकते हैं। फोरलॉजिकल प्रतिकृति हालांकि, नेटवर्क पर प्रतिकृति प्रोटोकॉल के माध्यम से परिवर्तनों को खींचना पड़ता है। यह समय लेने वाला हो सकता है। समन्वयन चरण के दौरान अधिक कार्यकर्ताओं को अनुमति देने से यह प्रक्रिया तेज हो सकती है:
# basically the number of tables that are synced in
# parallel during initialization of subscription
max_sync_workers_per_subscription = 8ऑटोवैक्यूम
समय-समय पर, कॉन्फ़िगरेशन सेटिंग्स के एक समूह के आधार पर, पोस्टग्रेज़ उन श्रमिकों के समूह को फैलाएगा जो डेटाबेस तालिकाओं को खाली कर देंगे। यह निश्चित रूप से, ऑटोवैक्यूम कहलाता है, और ऑटोवैक्यूम लॉन्चर द्वारा हर बार उत्पन्न होने वाले श्रमिकों की संख्या को कॉन्फ़िगरेशन सेटिंग के माध्यम से सेट किया जा सकता है:
# the maximum number of autovacuum processes
autovacuum_max_workers = 8WAL संपीड़न
यदि आपके पास अतिरिक्त CPU है, तो आप WAL फ़ाइलों में लिखे गए पृष्ठों को संपीड़ित करके डिस्क बैंडविड्थ के लिए CPU का व्यापार कर सकते हैं। यह डेटा की मात्रा को कम करता है जिसे डेटा को संपीड़ित करने के लिए अधिक CPU चक्रों की कीमत पर डिस्क पर लिखने की आवश्यकता होती है। यह डेटा के आकार को भी कम करता है जिसे स्ट्रीमिंग प्रतिकृति के लिए पूरे तार पर भेजने की आवश्यकता होती है।
व्यावहारिक रूप से, वाल संपीड़न के लाभ बहुत ही उचित उपरि के लायक हैं। इसे चालू करने के लिए, उपयोग करें:
# compresses full page images written to WAL
wal_compression = onस्मृति
क्या स्केल अपने आप होता है
ओएस स्वचालित रूप से मेमोरी का प्रबंधन और उपयोग करता है जो हाल ही में डिस्क से पढ़े और लिखे गए डेटा को कैशिंग करने के लिए किसी भी एप्लिकेशन द्वारा उपयोग नहीं किया जाता है। यह डिस्क-गहन अनुप्रयोगों और निश्चित रूप से PostgreSQL को बहुत गति देता है।
लिनक्स में, पोस्टग्रेज के लिए सबसे लोकप्रिय होस्ट, ओएस डिस्क कैश का आकार उपयोगकर्ता द्वारा निर्धारित नहीं किया जा सकता है। इसका प्रबंधन Linux के लिए आंतरिक है। मेमोरीप्रेशर के तहत, यह एप्लिकेशन को डिस्क कैश मेमोरी देगा।
ट्वीकिंग की क्या आवश्यकता है
क्वेरी प्लानर
क्वेरी प्लानर को ओएस द्वारा प्रदान किए गए डिस्क कैश की मात्रा को इसके अनुमानों में एक कारक के रूप में शामिल करना होगा। यदि आप OS डिस्क कैश को महत्वपूर्ण रूप से (उपलब्ध मेमोरी को बढ़ाकर) बढ़ाने में कामयाब रहे हैं, तो इस कॉन्फ़िगरेशन सेटिंग को बढ़ाने से योजनाकार के अनुमानों को बेहतर बनाने में मदद मिल सकती है:
# the planner's assumption about the effective size
# of the disk cache that is available to a single query.
effective_cache_size = 64GBसाझा मेमोरी
PostgreSQL बफ़र्स के एक सेट का उपयोग करता है जो सभी श्रमिकों और बैकएंडप्रोसेस के बीच साझा किया जाता है। इन्हें साझा बफ़र्स . कहा जाता है , और साझा बफ़र्स के लिए आवंटित मेमोरी की मात्रा कॉन्फ़िगरेशन सेटिंग का उपयोग करके सेट की जाती है:
shared_buffers = 32GBअस्थायी बफ़र
जब अस्थायी तालिकाओं को किसी क्वेरी द्वारा एक्सेस किया जाता है, तो बफ़र्स को पढ़ने वाली सामग्री को कैश करने के लिए आवंटित किया जाता है। इस बफ़र का आकार कॉन्फ़िगरेशन सेटिंग का उपयोग करके सेट किया जाता है:
# the maximum number of temporary buffers used
# by each database session
temp_buffers = 100MBयदि आपके पास अतिरिक्त मेमोरी है और ऐसे प्रश्न हैं जो अस्थायी तालिकाओं का अत्यधिक उपयोग करते हैं, तो इस मान को बढ़ाने से ऐसे प्रश्नों को गति मिल सकती है।
वर्किंग मेमोरी
वर्किंग मेमोरी को बैकएंड द्वारा स्थानीय और निजी तौर पर आवंटित किया जाता है। इसका उपयोग अस्थायी टेबल बनाने के बिना सॉर्ट और जॉइन को पूरा करने के लिए किया जाता है। इसे 4 एमबी के डिफ़ॉल्ट से बढ़ाकर अस्थायी टेबल निर्माण के दौरान प्रश्नों को तेजी से पूरा किया जा सकता है:
# the amount of memory to be used by internal sort
# operations and hash tables before writing to temporary disk files
work_mem = 16MBरखरखाव संचालन
VACUUM द्वारा उपयोग की जाने वाली मेमोरी, इंडेक्स निर्माण और ऐसे अन्य रखरखाव कमांड को कॉन्फ़िगरेशन सेटिंग maintenance_work_mem द्वारा नियंत्रित किया जाता है . इस राशि को बढ़ाने से इन कार्यों में तेजी आ सकती है, विशेष रूप से अनुक्रमणिका या तालिकाओं पर जिन्हें फिर से बनाने की आवश्यकता होती है।
ऑटोवैक्यूम वर्कर्स द्वारा उपयोग की जाने वाली मेमोरी को मेंटेनेंस वर्कमेमोरी से लिया जा सकता है (autovacuum_work_mem = -1 सेट करके) ) या स्वतंत्र रूप से कॉन्फ़िगर किया गया।
# the maximum amount of memory to be used by
# maintenance operations
maintenance_work_mem = 128MB
# maximum amount of memory to be used by each
# autovacuum worker process
autovacuum_work_mem = -1डिस्क
क्या स्केल अपने आप होता है
डिस्क को बड़ा, तेज या अधिक समवर्ती बनाया जा सकता है। डिस्क का आकार केवल एक चीज है जिसके बारे में PostgreSQL को निर्देश देने की आवश्यकता नहीं है। डिफ़ॉल्ट रूप से, PostgreSQL किसी भी उपलब्ध डिस्क स्थान का उपयोग करने से स्वयं को बाधित नहीं करेगा। यह आमतौर पर ठीक है।
हालांकि, आप बनाई गई अस्थायी फ़ाइलों के कुल आकार पर एक सीमा लगा सकते हैं, कुछ अरबों और इस तरह की क्वेरी को सॉर्ट करने का प्रयास करने वाले प्रश्नों के विरुद्ध कुछ सुरक्षा प्रदान करें:
# the maximum amount of disk space that a process
# can use for temporary files
temp_file_limit = 500GBट्वीकिंग की क्या आवश्यकता है
Concurrency
RAID-ed डिस्क और फ़ाइल सिस्टम जैसे ZFS को अधिक समवर्ती समर्थन के लिए सेटअप किया जा सकता है। इसका मतलब यह है कि, आप कुछ डिस्क रीड/राइट को ऐसे फाइल सिस्टम द्वारा समवर्ती रूप से सेवित किया जा सकता है क्योंकि जिस तरह से डेटा को आंतरिक रूप से स्टोर या हैंडल किया जाता है।
आप इस कॉन्फ़िगरेशन सेटिंग का उपयोग करके Postgres को एकाधिक समवर्ती डिस्क I/O जारी करने दे सकते हैं:
# the number of concurrent disk I/O operations that
# PostgreSQL expects can be executed simultaneously
effective_io_concurrency = 4यह वर्तमान में केवल बिटमैप हीप स्कैन द्वारा उपयोग किया जाता है।
यादृच्छिक पृष्ठ लागत
पोस्टग्रेज क्वेरी प्लानर मानता है कि अनुक्रमिक रीड रैंडमरीड्स की तुलना में तेज़ हैं। वास्तव में कितना तेज़ एक मूल्य है जिसे आप ट्विक कर सकते हैं। डिफ़ॉल्ट रूप से, यह मान लिया जाता है कि यादृच्छिक पठन 4 गुना महंगा है।
आपके डिस्क सेटअप, वर्कलोड और बेंचमार्किंग के आधार पर, यदि आप सुनिश्चित हैं कि रैंडम रीड्स कह रहे हैं, अनुक्रमिक रीड्स से केवल दोगुना महंगा है, तो आप पोस्टग्रेज को बता सकते हैं:
# the planner's estimate of the cost of a disk page
# fetch that is part of a series of sequential fetches
seq_page_cost = 1
# the planner's estimate of the cost of a
# non-sequentially-fetched disk page
random_page_cost = 2टेबलस्पेस
कई डिस्क का लाभ उठाने के लिए जो एक बड़े सिंगल फाइल सिस्टम के रूप में माउंट नहीं हैं, आप टेबलस्पेस का उपयोग कर सकते हैं। टेबलस्पेस के साथ, आप टेबल या इंडेक्स को अलग फाइल सिस्टम रख सकते हैं। यह संगामिति में सुधार कर सकता है और तालिका वृद्धि को संभालने का एक आसान तरीका प्रदान करता है।
CREATE TABLESPACE disk2 LOCATION '/mnt/disk2/postgres';यहां टेबलस्पेस के बारे में और पढ़ें।
नेटवर्क
नेटवर्क आमतौर पर PostgreSQL सर्वर पर सबसे कम उपयोग किया जाने वाला संसाधन है, और शायद ही कभी संतृप्त होता है। यदि आपको स्केल करने की आवश्यकता है, तो प्रत्येक अपने स्वयं के आईपी के साथ अधिक नेटवर्क इंटरफेस जोड़ना काफी आसान है और पोस्ट्रेएसक्यूएल उन सभी को सुनें:
listen_addresses = '10.1.0.10,10.1.0.11'क्लाइंट को उन सभी IP में संतुलित लोड करना होगा, जिन पर Postgreslists सुनता है।
अन्य
कुछ अन्य कॉन्फ़िगरेशन सेटिंग्स हैं जिन्हें संशोधित किया जा सकता है, जिनमें से अधिकांश अधिक CPU का उपयोग करते हैं और स्मृति।
विभाजनवार संचालन
Postgres 10 ने तालिका विभाजन की शुरुआत की, जिसे Postgres 11 में सुधार किया गया था। विभाजन पर कुछ क्वेरी अनुकूलन डिफ़ॉल्ट रूप से चालू नहीं होते हैं, क्योंकि उनके परिणामस्वरूप उच्च CPU और मेमोरी खपत हो सकती है। ये हैं:
# allow a join between partitioned tables to be
# performed by joining the matching partitions
enable_partitionwise_join = on
# allow grouping or aggregation on a partitioned
# tables performed separately for each partition
enable_partitionwise_aggregate = on