जबकि आपके PostgreSQL डेटाबेस को पुनर्प्राप्त करने के कई तरीके हैं, तार्किक बैकअप से आपके डेटा को पुनर्स्थापित करने के लिए सबसे सुविधाजनक तरीकों में से एक है। लॉजिकल बैकअप डिजास्टर एंड रिकवरी प्लानिंग (डीआरपी) के लिए महत्वपूर्ण भूमिका निभाते हैं। तार्किक बैकअप लिया गया बैकअप है, उदाहरण के लिए pg_dump या pg_dumpall का उपयोग करना, जो बाइनरी फ़ाइल में लिखे गए सभी तालिका डेटा को प्राप्त करने के लिए SQL कथन उत्पन्न करता है।
आपके भौतिक बैकअप के विफल होने या अनुपलब्ध होने की स्थिति में आवधिक तार्किक बैकअप चलाने की भी सिफारिश की जाती है। PostgreSQL के लिए, यदि आप सुनिश्चित नहीं हैं कि कौन से टूल का उपयोग करना है, तो पुनर्स्थापित करना समस्याग्रस्त हो सकता है। बैकअप टूल pg_dump को आमतौर पर रिस्टोरेशन टूल pg_restore के साथ पेयर किया जाता है।
pg_dump और pg_restore एक साथ काम करते हैं यदि आपदा आती है और आपको अपना डेटा पुनर्प्राप्त करने की आवश्यकता होती है। जबकि वे डंप और पुनर्स्थापना के प्राथमिक उद्देश्य की पूर्ति करते हैं, इसके लिए आपको कुछ अतिरिक्त कार्य करने की आवश्यकता होती है जब आपको अपने क्लस्टर को पुनर्प्राप्त करने और एक विफलता करने की आवश्यकता होती है (यदि आपका सक्रिय प्राथमिक या मास्टर हार्डवेयर विफलता या वीएम सिस्टम भ्रष्टाचार के कारण मर जाता है)। आप तीसरे पक्ष के टूल ढूंढ़ने और उनका उपयोग करने लगेंगे जो फ़ेलओवर या स्वचालित क्लस्टर पुनर्प्राप्ति को संभाल सकते हैं।
इस ब्लॉग में, हम देखेंगे कि pg_restore कैसे काम करता है और इसकी तुलना ClusterControl के बैकअप को संभालने और आपदा होने पर आपके डेटा को पुनर्स्थापित करने के तरीके से करेंगे।
pg_restore के तंत्र
pg_restore निम्न कार्यों को प्राप्त करते समय उपयोगी होता है:
- डेटा, एक्सेस भूमिकाओं, डेटाबेस और तालिका परिभाषाओं वाली SQL जेनरेट की गई फ़ाइलों को उत्पन्न करने के लिए pg_dump के साथ जोड़ा गया
- एक गैर-सादा-पाठ प्रारूप में pg_dump द्वारा बनाए गए संग्रह से PostgreSQL डेटाबेस को पुनर्स्थापित करें।
- यह डेटाबेस को उस स्थिति में फिर से संगठित करने के लिए आवश्यक आदेश जारी करेगा, जिस समय इसे सहेजा गया था।
- इसमें संग्रह फ़ाइल के आधार पर चुनिंदा होने या यहां तक कि आइटम को पुनर्स्थापित करने से पहले पुन:व्यवस्थित करने की क्षमता है
- संग्रह फ़ाइलें सभी आर्किटेक्चर में पोर्टेबल होने के लिए डिज़ाइन की गई हैं।
- pg_restore दो मोड में काम कर सकता है।
- यदि डेटाबेस नाम निर्दिष्ट है, तो pg_restore उस डेटाबेस से जुड़ता है और संग्रह सामग्री को सीधे डेटाबेस में पुनर्स्थापित करता है।
- या, डेटाबेस के पुनर्निर्माण के लिए आवश्यक SQL कमांड वाली एक स्क्रिप्ट बनाई जाती है और एक फ़ाइल या मानक आउटपुट पर लिखी जाती है। इसका स्क्रिप्ट आउटपुट pg_dump द्वारा उत्पन्न प्रारूप के समतुल्य है
- आउटपुट को नियंत्रित करने वाले कुछ विकल्प इसलिए pg_dump विकल्पों के अनुरूप होते हैं।
एक बार जब आप डेटा को पुनर्स्थापित कर लेते हैं, तो प्रत्येक पुनर्स्थापित तालिका पर ANALYZE चलाना सबसे अच्छा और उचित होता है ताकि अनुकूलक के पास उपयोगी आंकड़े हों। हालांकि यह रीड लॉक प्राप्त करता है, आपको इसे कम ट्रैफ़िक के दौरान या अपनी रखरखाव अवधि के दौरान चलाना पड़ सकता है।
pg_restore के लाभ
pg_dump और pg_restore इन टेंडेम में ऐसी क्षमताएं हैं जो एक DBA के उपयोग के लिए सुविधाजनक हैं।
- pg_dump और pg_restore में -j विकल्प निर्दिष्ट करके समानांतर में चलने की क्षमता है। -j/--jobs
का उपयोग करके आप यह निर्दिष्ट कर सकते हैं कि समानांतर में कितने चल रहे कार्य विशेष रूप से डेटा लोड करने, अनुक्रमणिका बनाने, या एकाधिक समवर्ती नौकरियों का उपयोग करके बाधा उत्पन्न करने के लिए चल सकते हैं। - इसका उपयोग करना आसान है, आप विशिष्ट डेटाबेस या तालिकाओं को चुनिंदा रूप से डंप या लोड कर सकते हैं
- यह उपयोगकर्ता को उस विशेष डेटाबेस, स्कीमा, या सूची के आधार पर निष्पादित की जाने वाली प्रक्रियाओं को पुन:व्यवस्थित करने की अनुमति देता है और लचीलापन प्रदान करता है। आप एसक्यूएल के अनुक्रम को शिथिल रूप से उत्पन्न और लोड भी कर सकते हैं जैसे कि आपकी आवश्यकताओं के अनुसार एसीएल या विशेषाधिकार को रोकें। आपकी आवश्यकताओं के अनुरूप बहुत सारे विकल्प हैं।
- यह आपको किसी संग्रह से pg_dump की तरह ही SQL फ़ाइलें जेनरेट करने की क्षमता प्रदान करता है। यह बहुत सुविधाजनक है यदि आप एक अलग वातावरण का प्रावधान करने के लिए किसी अन्य डेटाबेस या होस्ट पर लोड करना चाहते हैं।
- एसक्यूएल प्रक्रियाओं के उत्पन्न अनुक्रम के आधार पर इसे समझना आसान है।
- प्रतिकृति वातावरण में डेटा लोड करने का यह एक सुविधाजनक तरीका है। आपको अपनी प्रतिकृति को पुन:व्यवस्थित करने की आवश्यकता नहीं है क्योंकि कथन SQL हैं जिन्हें स्टैंडबाय और पुनर्प्राप्ति नोड्स में दोहराया गया था।
pg_restore की सीमाएं
तार्किक बैकअप के लिए, pg_restore की स्पष्ट सीमाएं pg_dump के साथ टूल का उपयोग करते समय प्रदर्शन और गति है। जब आप एक परीक्षण या विकास डेटाबेस वातावरण का प्रावधान करना चाहते हैं और अपना डेटा लोड करना चाहते हैं, तो यह आसान हो सकता है, लेकिन यह तब लागू नहीं होता जब आपका डेटा सेट बहुत बड़ा हो। PostgreSQL को आपके डेटा को एक-एक करके डंप करना होगा या डेटाबेस इंजन द्वारा आपके डेटा को क्रमिक रूप से निष्पादित और लागू करना होगा। यद्यपि आप अपने डेटाबेस पर प्रभाव से बचने के लिए -j निर्दिष्ट करने या --single-transaction का उपयोग करने की तरह इसे शिथिल रूप से लचीला बना सकते हैं, फिर भी SQL का उपयोग करके लोड करना इंजन द्वारा पार्स किया जाना है।
इसके अतिरिक्त, PostgreSQL प्रलेखन निम्नलिखित सीमाओं को बताता है, हमारे परिवर्धन के साथ जैसा कि हमने इन उपकरणों को देखा (pg_dump और pg_restore):
- पहले से मौजूद तालिका में डेटा को पुनर्स्थापित करते समय और विकल्प --disable-triggers का उपयोग किया जाता है, pg_restore डेटा डालने से पहले उपयोगकर्ता तालिकाओं पर ट्रिगर्स को अक्षम करने के लिए कमांड का उत्सर्जन करता है, फिर उन्हें फिर से सक्षम करने के लिए कमांड का उत्सर्जन करता है डेटा डालने के बाद। यदि पुनर्स्थापना बीच में रोक दी जाती है, तो सिस्टम कैटलॉग गलत स्थिति में रह सकते हैं।
- pg_restore बड़ी वस्तुओं को चुनिंदा रूप से पुनर्स्थापित नहीं कर सकता; उदाहरण के लिए, केवल एक विशिष्ट तालिका के लिए। अगर किसी संग्रह में बड़ी वस्तुएं हैं, तो सभी बड़ी वस्तुओं को पुनर्स्थापित किया जाएगा, या उनमें से कोई भी नहीं अगर उन्हें -L, -t, या अन्य विकल्पों के माध्यम से बाहर रखा गया है।
- दोनों टूल से विशेष रूप से एक विशाल डेटाबेस के लिए बड़ी मात्रा में आकार (फ़ाइलें, निर्देशिका, या टार संग्रह) उत्पन्न करने की उम्मीद है।
- pg_dump के लिए, जब किसी एक टेबल को या प्लेन टेक्स्ट के रूप में डंप किया जाता है, तो pg_dump बड़ी वस्तुओं को हैंडल नहीं करता है। गैर-पाठ संग्रह प्रारूपों में से किसी एक का उपयोग करके बड़ी वस्तुओं को पूरे डेटाबेस के साथ डंप किया जाना चाहिए।
- यदि आपके पास इन उपकरणों द्वारा उत्पन्न टार संग्रह हैं, तो ध्यान दें कि टार संग्रह 8 जीबी से कम आकार तक सीमित हैं। यह टैर फ़ाइल स्वरूप की एक अंतर्निहित सीमा है। इसलिए इस प्रारूप का उपयोग नहीं किया जा सकता है यदि किसी तालिका का पाठ्य प्रतिनिधित्व उस आकार से अधिक हो। टार आर्काइव का कुल आकार और अन्य आउटपुट स्वरूपों में से कोई भी सीमित नहीं है, सिवाय संभवतः ऑपरेटिंग सिस्टम द्वारा।
pg_restore का उपयोग करना
pg_restore का उपयोग करना काफी आसान और उपयोग में आसान है। चूंकि इसे pg_dump के साथ जोड़ा गया है, इसलिए ये दोनों उपकरण पर्याप्त रूप से तब तक काम करते हैं जब तक लक्ष्य आउटपुट दूसरे के अनुकूल है। उदाहरण के लिए, निम्न pg_dump pg_restore के लिए उपयोगी नहीं होगा,
[example@sqldat.com ~]# pg_dump --format=p --create -U dbapgadmin -W -d paultest -f plain.sql
Password: यह परिणाम एक psql संगत होगा जो इस प्रकार दिखता है:
[example@sqldat.com ~]# less plain.sql
--
-- PostgreSQL database dump
--
-- Dumped from database version 12.2
-- Dumped by pg_dump version 12.2
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SELECT pg_catalog.set_config('search_path', '', false);
SET check_function_bodies = false;
SET xmloption = content;
SET client_min_messages = warning;
SET row_security = off;
--
-- Name: paultest; Type: DATABASE; Schema: -; Owner: postgres
--
CREATE DATABASE paultest WITH TEMPLATE = template0 ENCODING = 'UTF8' LC_COLLATE = 'en_US.UTF-8' LC_CTYPE = 'en_US.UTF-8';
ALTER DATABASE paultest OWNER TO postgres;लेकिन यह pg_restore के लिए विफल हो जाएगा क्योंकि पालन करने के लिए कोई सादा प्रारूप नहीं है:
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=p -C -W -d postgres plain.sql
pg_restore: error: unrecognized archive format "p"; please specify "c", "d", or "t"
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=c -C -W -d postgres plain.sql
pg_restore: error: did not find magic string in file headerअब, pg_restore के लिए और अधिक उपयोगी शब्दों पर चलते हैं।
pg_restore:ड्रॉप करें और पुनर्स्थापित करें
pg_restore के एक सरल उपयोग पर विचार करें जिसे आपने डेटाबेस छोड़ दिया है, उदा.
postgres=# drop database maxtest;
DROP DATABASE
postgres=# \l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
-----------+----------+----------+-------------+-------------+-----------------------+---------+------------+--------------------------------------------
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 83 MB | pg_default |
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8209 kB | pg_default | default administrative connection database
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +| 8049 kB | pg_default | unmodifiable empty database
| | | | | postgres=CTc/postgres | | |
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | postgres=CTc/postgres+| 8193 kB | pg_default | default template for new databases
| | | | | =c/postgres | | |
(4 rows)pg_restore इसे बहुत ही सरल तरीके से पुनर्स्थापित करना,
[example@sqldat.com ~]# sudo -iu postgres pg_restore -C -d postgres /opt/pg-files/dump/f.dump -C/--create यहां बताता है कि हेडर में एक बार डेटाबेस का सामना करने के बाद इसे बनाते हैं। -d पोस्टग्रेज डेटाबेस को पोस्टग्रेज करता है लेकिन इसका मतलब यह नहीं है कि यह डेटाबेस को पोस्टग्रेज करने के लिए टेबल बनाएगा। यह आवश्यक है कि डेटाबेस मौजूद होना चाहिए। यदि -C निर्दिष्ट नहीं है, तो तालिका और रिकॉर्ड -d तर्क के साथ संदर्भित उस डेटाबेस में संग्रहीत किए जाएंगे।
तालिका द्वारा चुनिंदा रूप से पुनर्स्थापित करना
pg_restore के साथ तालिका को पुनर्स्थापित करना आसान और सरल है। उदाहरण के लिए, आपके पास "बी" और "डी" टेबल नामक दो टेबल हैं। मान लें कि आप नीचे दिए गए pg_dump कमांड को चलाते हैं,
[example@sqldat.com ~]# pg_dump --format=d --create -U dbapgadmin -W -d paultest -f pgdump_inserts
Password:जहां इस निर्देशिका की सामग्री इस प्रकार दिखाई देगी,
[example@sqldat.com ~]# ls -alth pgdump_inserts/
total 16M
-rw-r--r--. 1 root root 14M May 15 20:27 3696.dat.gz
drwx------. 2 root root 59 May 15 20:27 .
-rw-r--r--. 1 root root 2.5M May 15 20:27 3694.dat.gz
-rw-r--r--. 1 root root 4.0K May 15 20:27 toc.dat
dr-xr-x---. 5 root root 275 May 15 20:27 ..यदि आप किसी तालिका को पुनर्स्थापित करना चाहते हैं (अर्थात् इस उदाहरण में "d"),
[example@sqldat.com ~]# pg_restore -U postgres -Fd -d paultest -t d pgdump_inserts/होगा,
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)pg_restore:डेटाबेस तालिकाओं को किसी भिन्न डेटाबेस में कॉपी करना
आप अपने मौजूदा डेटाबेस की सामग्री को कॉपी भी कर सकते हैं और इसे अपने लक्षित डेटाबेस पर रख सकते हैं। उदाहरण के लिए, मेरे पास निम्नलिखित डेटाबेस हैं,
paultest=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+---------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 84 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8273 kB | pg_default |
(2 rows)पोल्टेस्ट डेटाबेस एक खाली डेटाबेस है, जबकि हम मैक्सटेस्ट डेटाबेस के अंदर क्या है, इसकी प्रतिलिपि बनाने जा रहे हैं,
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)इसे कॉपी करने के लिए, हमें मैक्सटेस्ट डेटाबेस से डेटा को निम्नानुसार डंप करना होगा,
[example@sqldat.com ~]# pg_dump --format=t --create -U dbapgadmin -W -d maxtest -f pgdump_data.tar
Password: फिर इसे निम्नानुसार लोड या पुनर्स्थापित करें,
अब, हमें पाल्टेस्ट डेटाबेस पर डेटा मिला है और तालिकाओं को तदनुसार संग्रहीत किया गया है।
postgres=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+--------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 153 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 154 MB | pg_default |
(2 rows)
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)पुन:क्रम से एक SQL फ़ाइल जनरेट करें
मैंने pg_restore के साथ बहुत अधिक उपयोग देखा है लेकिन ऐसा लगता है कि यह सुविधा आमतौर पर प्रदर्शित नहीं होती है। मुझे यह तरीका बहुत दिलचस्प लगा क्योंकि यह आपको उस क्रम के आधार पर ऑर्डर करने की अनुमति देता है जिसे आप शामिल नहीं करना चाहते हैं और फिर जिस क्रम में आप आगे बढ़ना चाहते हैं उससे एक SQL फ़ाइल जेनरेट करें।
उदाहरण के लिए, हम पहले बनाए गए नमूने pgdump_data.tar का उपयोग करेंगे और एक सूची बनाएंगे। ऐसा करने के लिए, निम्न आदेश चलाएँ:
[example@sqldat.com ~]# pg_restore -l pgdump_data.tar > my.listयह एक फ़ाइल उत्पन्न करेगा जैसा कि नीचे दिखाया गया है:
[example@sqldat.com ~]# cat my.list
;
; Archive created at 2020-05-15 20:48:24 UTC
; dbname: maxtest
; TOC Entries: 13
; Compression: 0
; Dump Version: 1.14-0
; Format: TAR
; Integer: 4 bytes
; Offset: 8 bytes
; Dumped from database version: 12.2
; Dumped by pg_dump version: 12.2
;
;
; Selected TOC Entries:
;
204; 1259 24811 TABLE public b postgres
202; 1259 24757 TABLE public d postgres
203; 1259 24760 SEQUENCE public d_id_seq postgres
3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
3560; 2604 24762 DEFAULT public d id postgres
3691; 0 24811 TABLE DATA public b postgres
3689; 0 24757 TABLE DATA public d postgres
3699; 0 0 SEQUENCE SET public d_id_seq postgres
3562; 2606 24764 CONSTRAINT public d d_pkey postgresअब, चलिए इसे फिर से ऑर्डर करते हैं या हम कहेंगे कि मैंने SEQUENCE के निर्माण और बाधा के निर्माण को भी हटा दिया है। यह इस प्रकार दिखेगा,
TL;DR
...
;203; 1259 24760 SEQUENCE public d_id_seq postgres
;3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
TL;DR
….
;3562; 2606 24764 CONSTRAINT public d d_pkey postgresएसक्यूएल फ़ॉर्मेट में फ़ाइल जेनरेट करने के लिए, बस निम्न कार्य करें:
[example@sqldat.com ~]# pg_restore -L my.list --file /tmp/selective_data.out pgdump_data.tar अब, फ़ाइल /tmp/selective_data.out एक SQL जेनरेट की गई फ़ाइल होगी और यदि आप psql का उपयोग करते हैं, लेकिन pg_restore नहीं तो यह पढ़ने योग्य है। इसके बारे में बढ़िया बात यह है कि आप अपने टेम्पलेट के अनुसार एक SQL फ़ाइल उत्पन्न कर सकते हैं जिस पर डेटा केवल मौजूदा संग्रह से पुनर्स्थापित किया जा सकता है या pg_dump का उपयोग करके pg_restore की सहायता से बैकअप लिया जा सकता है।
PostgreSQL ClusterControl के साथ पुनर्स्थापित करें
ClusterControl अपने फीचरसेट के हिस्से के रूप में pg_restore या pg_dump का उपयोग नहीं करता है। हम तार्किक बैकअप उत्पन्न करने के लिए pg_dumpall का उपयोग करते हैं और दुर्भाग्य से, आउटपुट pg_restore के साथ संगत नहीं है।
नीचे दिखाए गए अनुसार PostgreSQL में बैकअप बनाने के कई अन्य तरीके हैं।
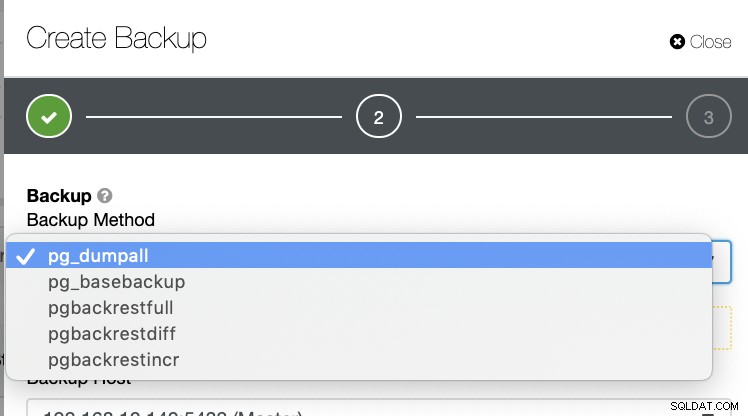
ऐसा कोई तंत्र नहीं है जहां आप चुनिंदा रूप से एक टेबल, एक डेटाबेस स्टोर कर सकें, या एक डेटाबेस से दूसरे डेटाबेस में कॉपी करें।
ClusterControl पॉइंट-इन-टाइम रिकवरी (PITR) का समर्थन करता है, लेकिन यह आपको डेटा पुनर्स्थापना को pg_restore की तरह लचीले ढंग से प्रबंधित करने की अनुमति नहीं देता है। बैकअप विधियों की सभी सूची के लिए, केवल pg_basebackup और pgbackrest ही PITR सक्षम हैं।
ClusterControl कैसे पुनर्स्थापित करता है यह है कि इसमें एक विफल क्लस्टर को पुनर्प्राप्त करने की क्षमता है जब तक कि ऑटो रिकवरी सक्षम है जैसा कि नीचे दिखाया गया है।

एक बार जब मास्टर विफल हो जाता है, तो स्लेव क्लस्टर को स्वचालित रूप से पुनर्प्राप्त कर सकता है क्योंकि ClusterControl प्रदर्शन करता है विफलता (जो स्वचालित रूप से किया जाता है)। डेटा पुनर्प्राप्ति भाग के लिए, आपका एकमात्र विकल्प क्लस्टर-व्यापी पुनर्प्राप्ति है जिसका अर्थ है कि यह पूर्ण बैकअप से आ रहा है। लक्ष्य डेटाबेस या तालिका पर चुनिंदा रूप से पुनर्स्थापित करने की कोई क्षमता नहीं है जिसे आप केवल पुनर्स्थापित करना चाहते थे। यदि आप ऐसा करना चाहते हैं, तो पूर्ण बैकअप पुनर्स्थापित करें, ClusterControl के साथ ऐसा करना आसान है। जैसा कि नीचे दिखाया गया है, आप बैकअप टैब पर जा सकते हैं,
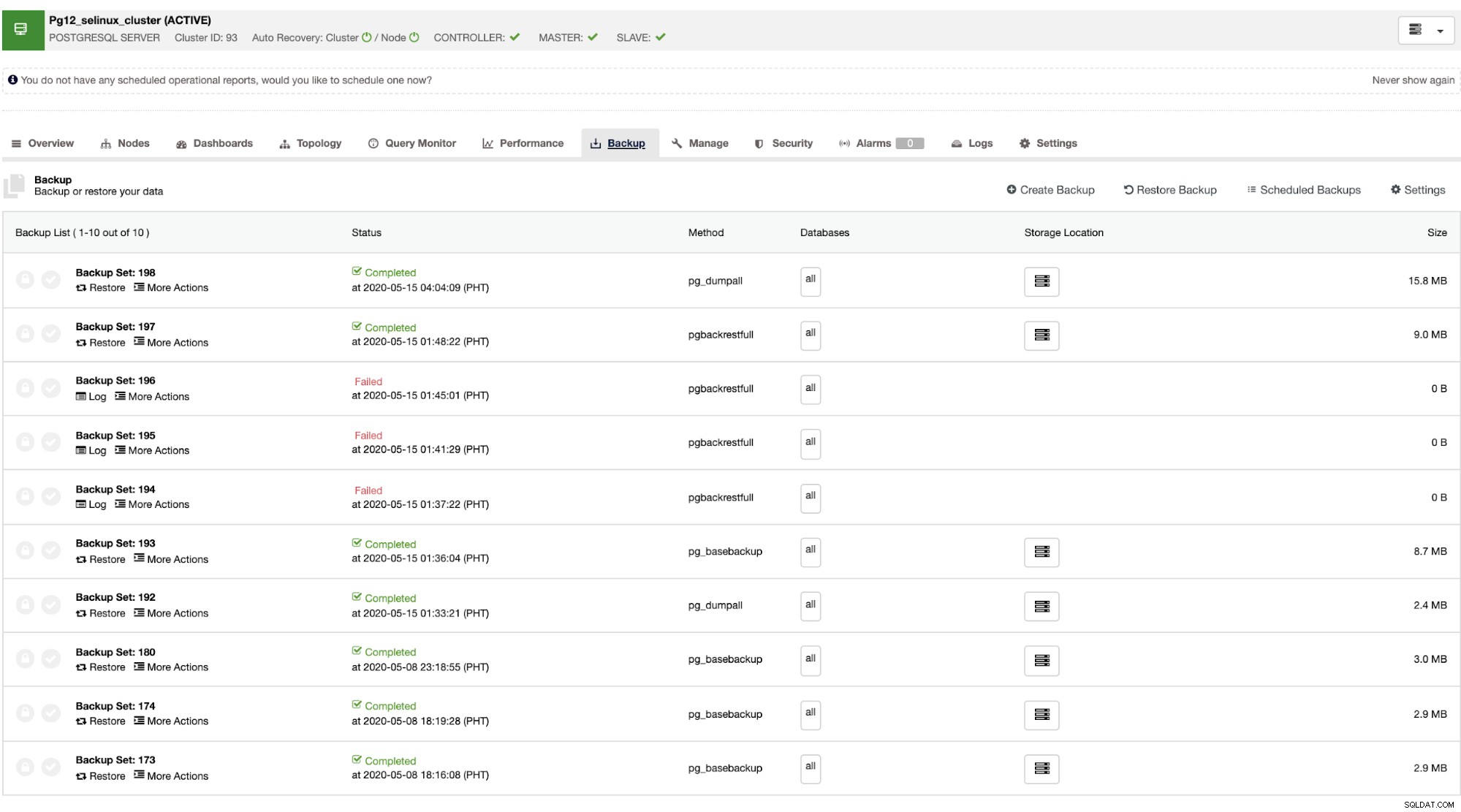
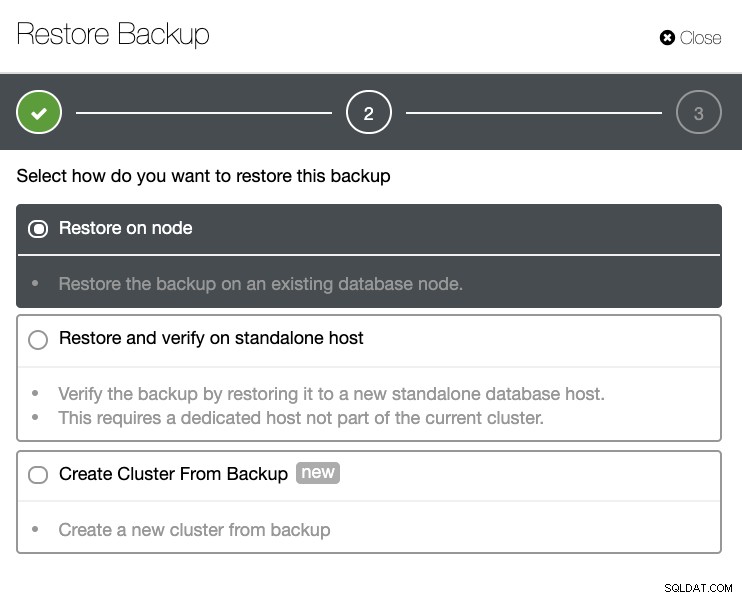
आपके पास सफल और असफल बैकअप की पूरी सूची होगी। फिर इसे पुनर्स्थापित करना लक्ष्य बैकअप चुनकर और "पुनर्स्थापना" बटन पर क्लिक करके किया जा सकता है। यह आपको ClusterControl के भीतर पंजीकृत मौजूदा नोड पर पुनर्स्थापित करने, या एक स्टैंड अलोन नोड पर सत्यापित करने, या बैकअप से एक क्लस्टर बनाने की अनुमति देगा।
निष्कर्ष
pg_dump और pg_restore का उपयोग करना बैकअप/डंप और पुनर्स्थापना दृष्टिकोण को सरल करता है। हालाँकि, बड़े पैमाने पर डेटाबेस वातावरण के लिए, यह आपदा पुनर्प्राप्ति के लिए एक आदर्श घटक नहीं हो सकता है। न्यूनतम चयन और पुनर्स्थापना प्रक्रिया के लिए, pg_dump और pg_restore के संयोजन का उपयोग करके आप अपनी आवश्यकताओं के अनुसार अपने डेटा को डंप और लोड करने की शक्ति प्रदान करते हैं।
उत्पादन परिवेशों के लिए (विशेषकर एंटरप्राइज़ आर्किटेक्चर के लिए) आप एक बैकअप बनाने और स्वचालित पुनर्प्राप्ति के साथ पुनर्स्थापित करने के लिए ClusterControl दृष्टिकोण का उपयोग कर सकते हैं।
दृष्टिकोणों का संयोजन भी एक अच्छा दृष्टिकोण है। यह आपको अपने आरटीओ और आरपीओ को कम करने में मदद करता है और साथ ही जरूरत पड़ने पर अपने डेटा को पुनर्स्थापित करने के लिए सबसे लचीले तरीके से लाभ उठाता है।