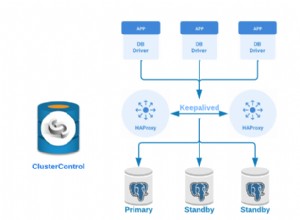
जैसा कि हमने हाल ही में घोषणा की थी, ClusterControl 1.7.4 में क्लस्टर-टू-क्लस्टर प्रतिकृति नामक एक नई सुविधा है। यह आपको दो स्वायत्त समूहों के बीच प्रतिकृति चलाने की अनुमति देता है। अधिक विस्तृत जानकारी के लिए कृपया उपर्युक्त घोषणा देखें।
हम इस पर एक नज़र डालेंगे कि मौजूदा PostgreSQL क्लस्टर के लिए इस नई सुविधा का उपयोग कैसे करें। इस कार्य के लिए, हम मान लेंगे कि आपके पास ClusterControl स्थापित है और इसका उपयोग करके मास्टर क्लस्टर परिनियोजित किया गया था।
मास्टर क्लस्टर के लिए आवश्यकताएँ
मास्टर क्लस्टर को काम करने के लिए कुछ आवश्यकताएं हैं:
- PostgreSQL 9.6 या बाद का संस्करण।
- ClusterControl भूमिका 'मास्टर' के साथ एक PostgreSQL सर्वर होना चाहिए।
- स्लेव क्लस्टर सेट करते समय व्यवस्थापक क्रेडेंशियल मास्टर क्लस्टर के समान होने चाहिए।
मास्टर क्लस्टर तैयार करना
मास्टर क्लस्टर को उपर्युक्त आवश्यकताओं को पूरा करने की आवश्यकता है।
पहली आवश्यकता के बारे में, सुनिश्चित करें कि आप मास्टर क्लस्टर में सही PostgreSQL संस्करण का उपयोग कर रहे हैं और स्लेव क्लस्टर के लिए इसे चुना है।
$ psql
postgres=# select version();
PostgreSQL 11.5 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bitयदि आपको किसी विशिष्ट नोड को मास्टर भूमिका सौंपने की आवश्यकता है, तो आप इसे ClusterControl UI से कर सकते हैं। ClusterControl पर जाएँ -> मास्टर क्लस्टर चुनें -> नोड्स -> नोड चुनें -> नोड क्रियाएँ -> स्लेव को बढ़ावा दें।
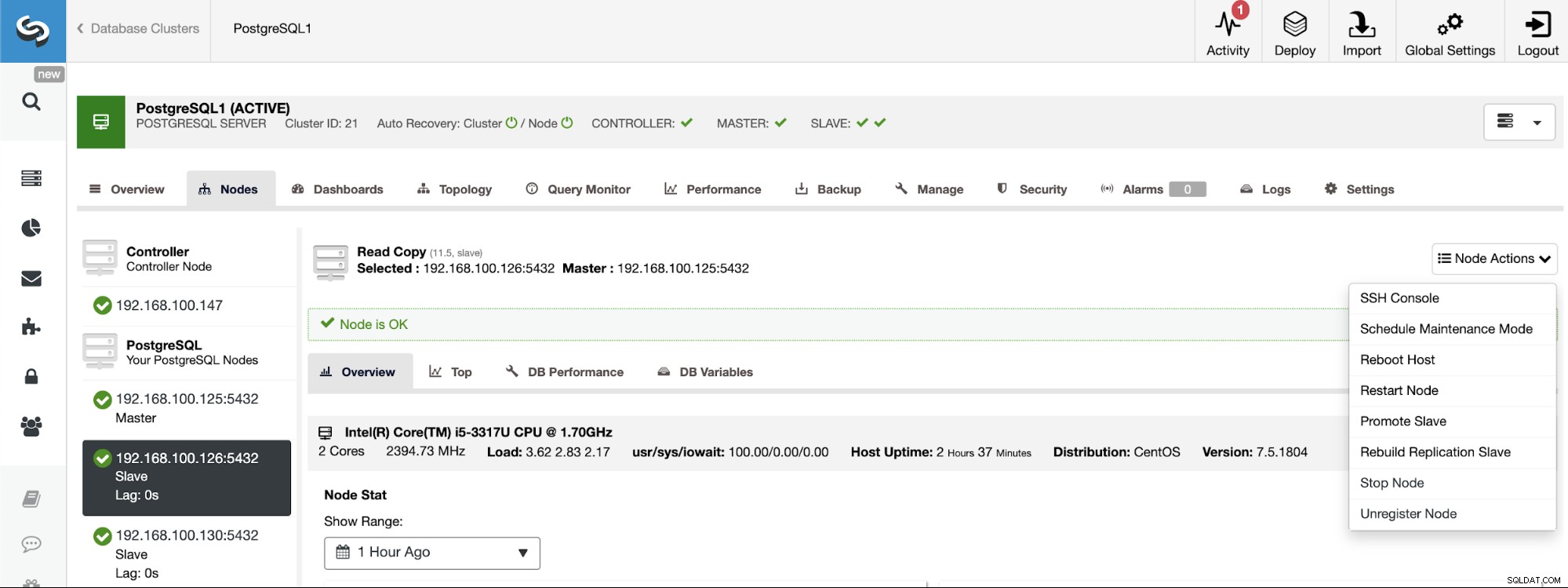
और अंत में, स्लेव क्लस्टर निर्माण के दौरान, आपको उसी व्यवस्थापक का उपयोग करना चाहिए क्रेडेंशियल जो आप वर्तमान में मास्टर क्लस्टर में उपयोग कर रहे हैं। आप देखेंगे कि इसे निम्नलिखित अनुभाग में कहाँ जोड़ना है।
ClusterControl UI से स्लेव क्लस्टर बनाना
नया स्लेव क्लस्टर बनाने के लिए, ClusterControl पर जाएं -> क्लस्टर चुनें -> क्लस्टर क्रियाएँ -> स्लेव क्लस्टर बनाएं।
स्लेव क्लस्टर मौजूदा मास्टर क्लस्टर से डेटा स्ट्रीम करके बनाया जाएगा।
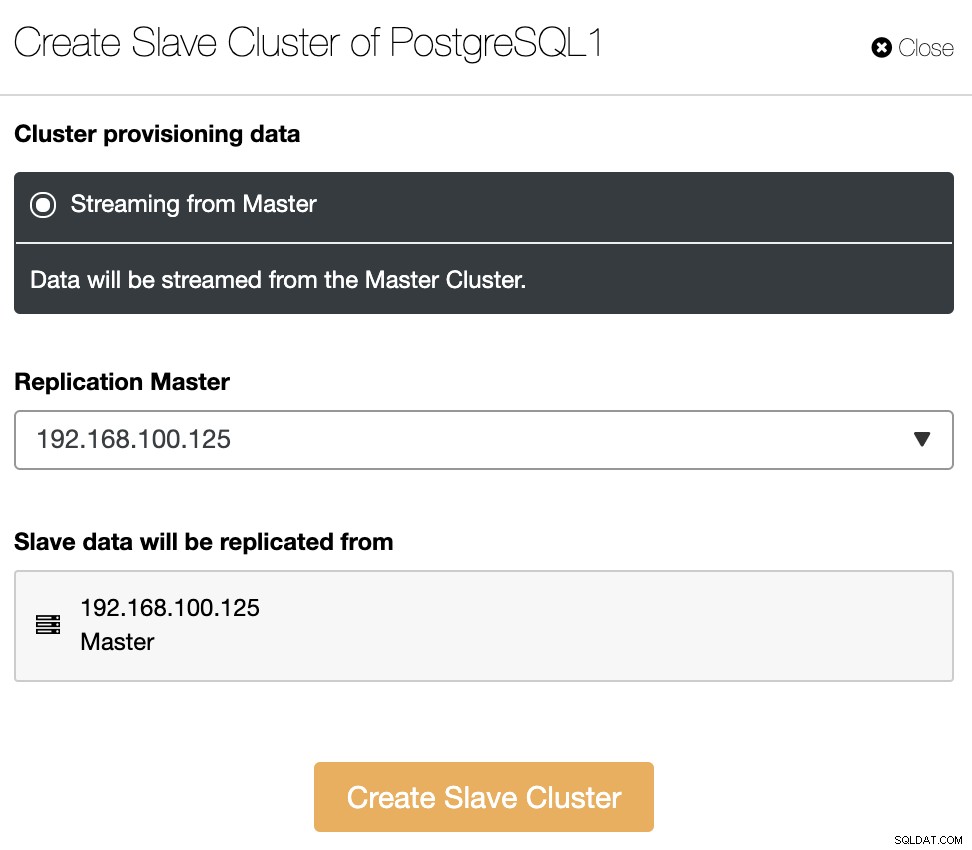
इस अनुभाग में, आपको वर्तमान क्लस्टर का मास्टर नोड भी चुनना होगा जिससे डेटा दोहराया जाएगा।
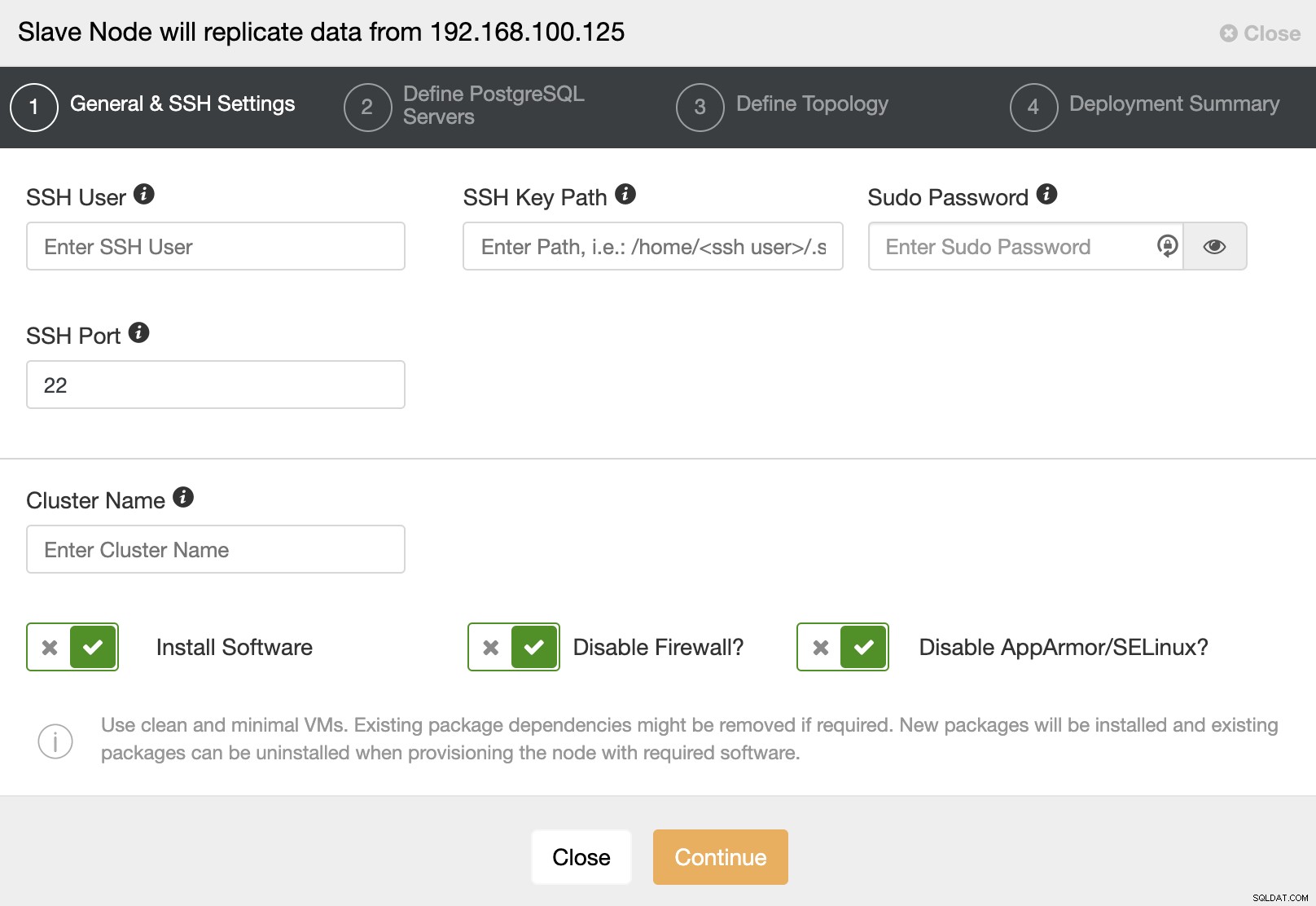
जब आप अगले चरण पर जाते हैं, तो आपको उपयोगकर्ता, कुंजी या निर्दिष्ट करना होगा एसएसएच द्वारा आपके सर्वर से कनेक्ट करने के लिए पासवर्ड और पोर्ट। आपको अपने स्लेव क्लस्टर के लिए एक नाम की भी आवश्यकता है और यदि आप चाहते हैं कि ClusterControl आपके लिए संबंधित सॉफ़्टवेयर और कॉन्फ़िगरेशन स्थापित करे।
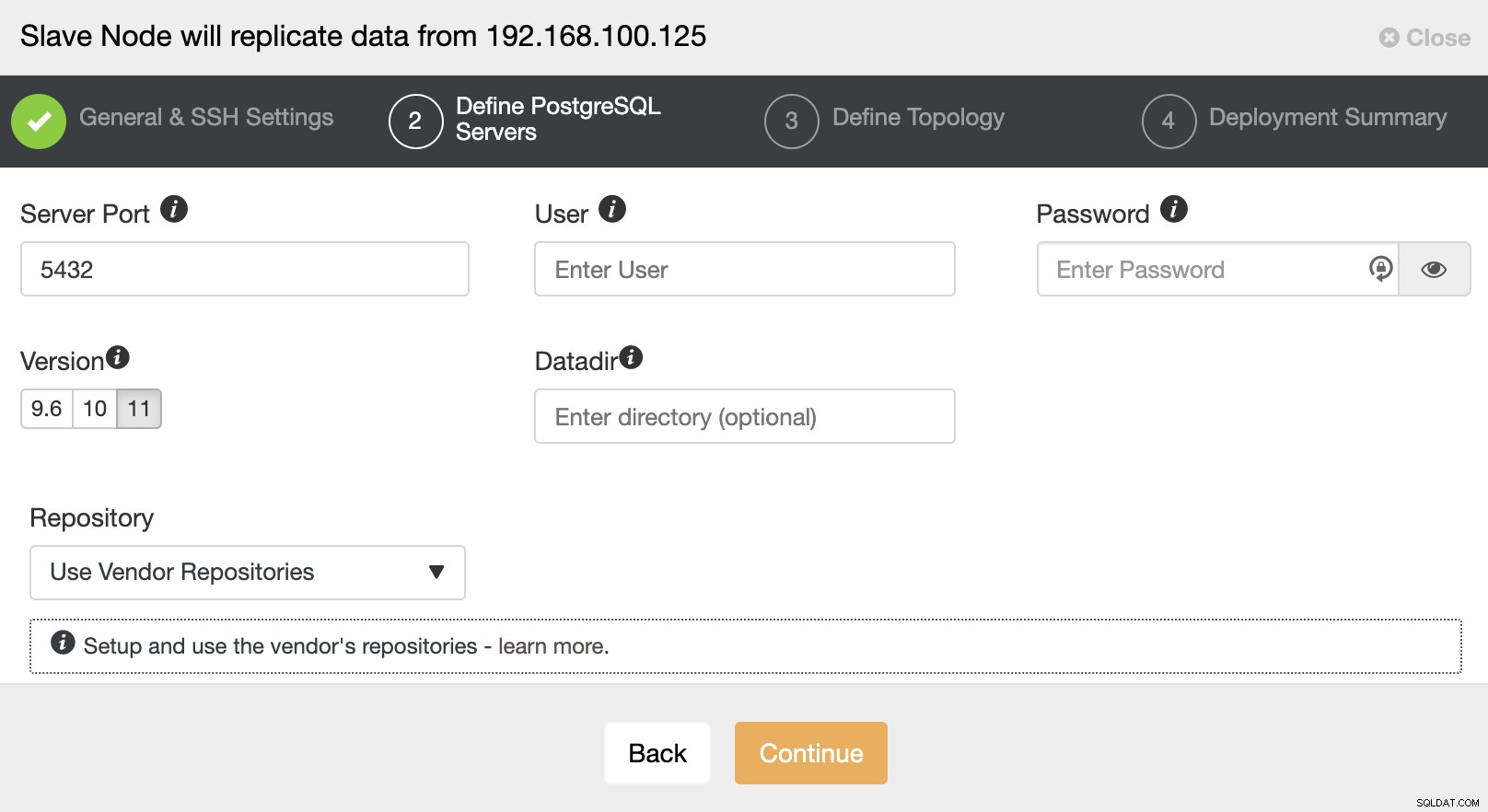
SSH एक्सेस जानकारी सेट करने के बाद, आपको डेटाबेस संस्करण को परिभाषित करना होगा, डेटादिर, पोर्ट, और व्यवस्थापक क्रेडेंशियल। चूंकि यह स्ट्रीमिंग प्रतिकृति का उपयोग करेगा, सुनिश्चित करें कि आप उसी डेटाबेस संस्करण का उपयोग करते हैं, और जैसा कि हमने पहले उल्लेख किया है, क्रेडेंशियल मास्टर क्लस्टर द्वारा उपयोग किए जाने वाले समान होने चाहिए। आप यह भी निर्दिष्ट कर सकते हैं कि किस भंडार का उपयोग करना है।
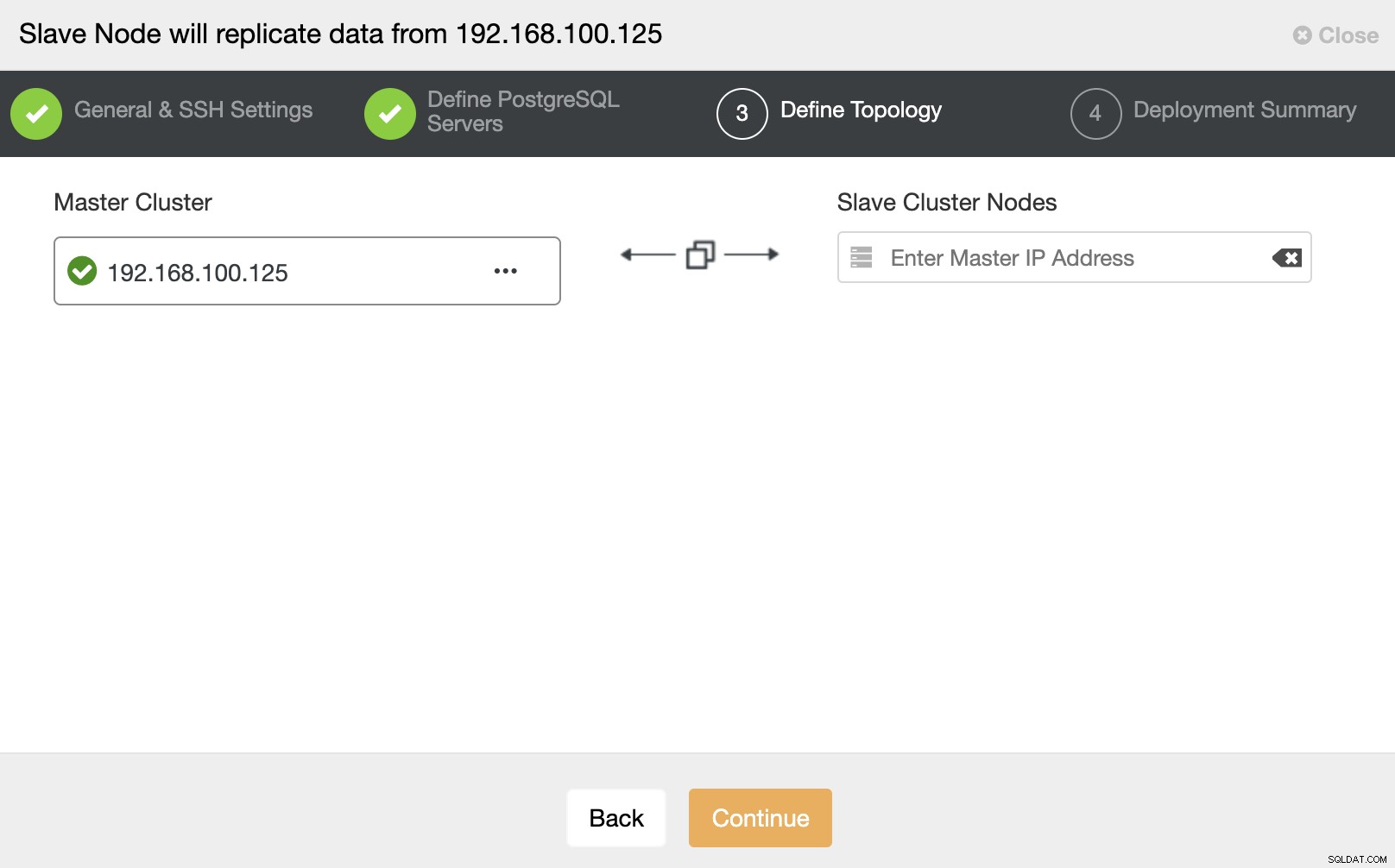
इस चरण में, आपको सर्वर को नए स्लेव क्लस्टर में जोड़ना होगा . इस कार्य के लिए, आप डेटाबेस नोड का IP पता या होस्टनाम दोनों दर्ज कर सकते हैं।
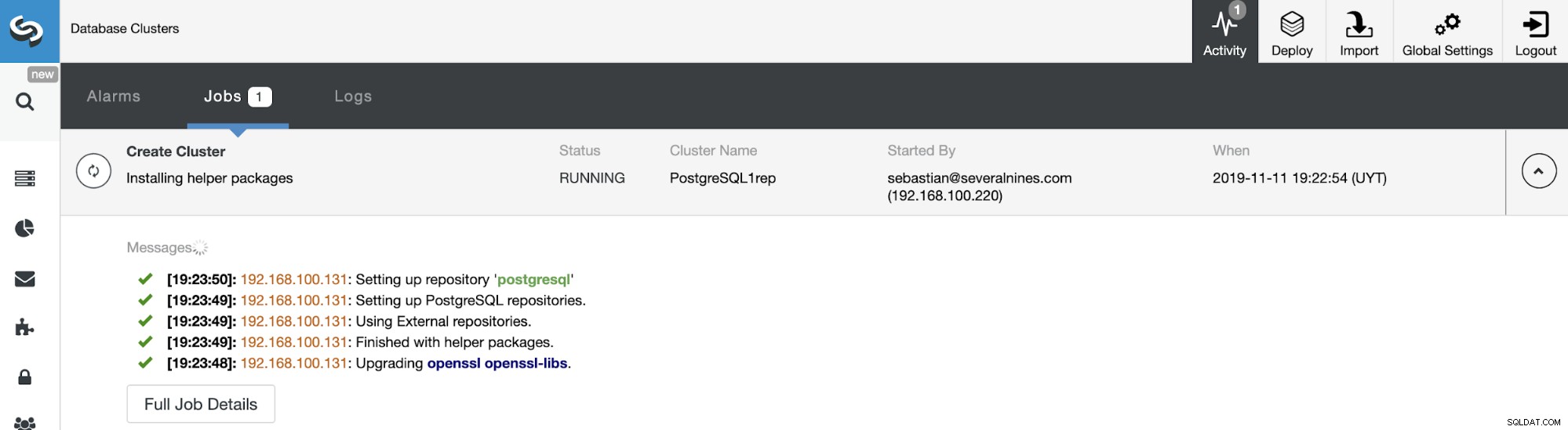
आप अपने नए स्लेव क्लस्टर के निर्माण की स्थिति की निगरानी यहां से कर सकते हैं ClusterControl गतिविधि मॉनिटर। कार्य समाप्त होने के बाद, आप क्लस्टर को मुख्य क्लस्टर नियंत्रण स्क्रीन में देख सकते हैं।
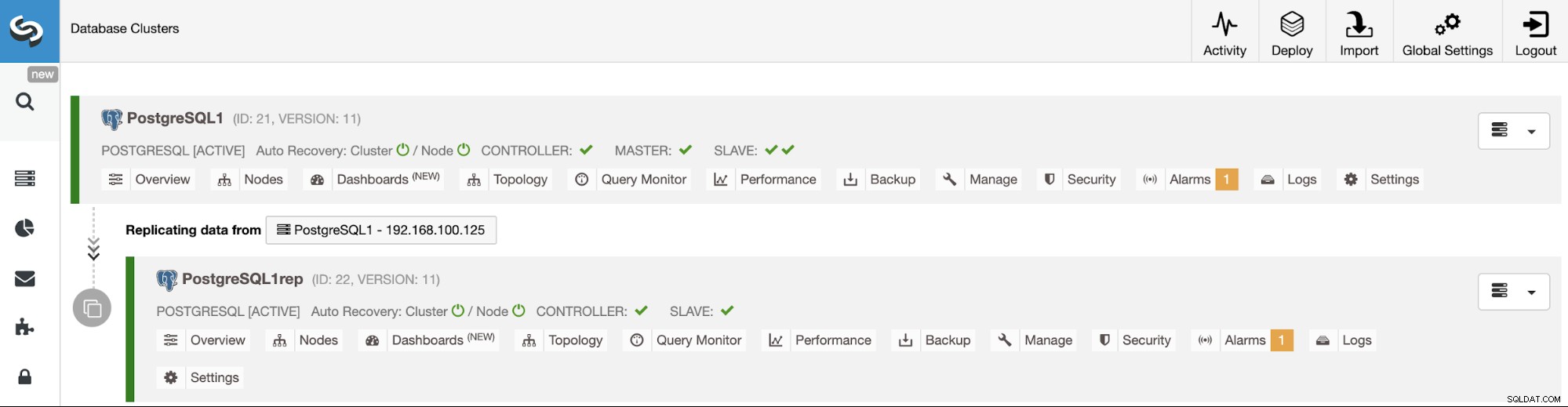
ClusterControl UI का उपयोग करके क्लस्टर-टू-क्लस्टर प्रतिकृति प्रबंधित करना
अब आपके पास आपका क्लस्टर-टू-क्लस्टर प्रतिकृति तैयार है और चल रहा है, क्लस्टरकंट्रोल का उपयोग करके इस टोपोलॉजी पर प्रदर्शन करने के लिए विभिन्न क्रियाएं हैं।
एक गुलाम समूह का पुनर्निर्माण
एक स्लेव क्लस्टर के पुनर्निर्माण के लिए, ClusterControl पर जाएं -> स्लेव क्लस्टर चुनें -> नोड्स -> मास्टर क्लस्टर से जुड़ा नोड चुनें -> नोड क्रियाएँ -> प्रतिकृति स्लेव का पुनर्निर्माण करें।
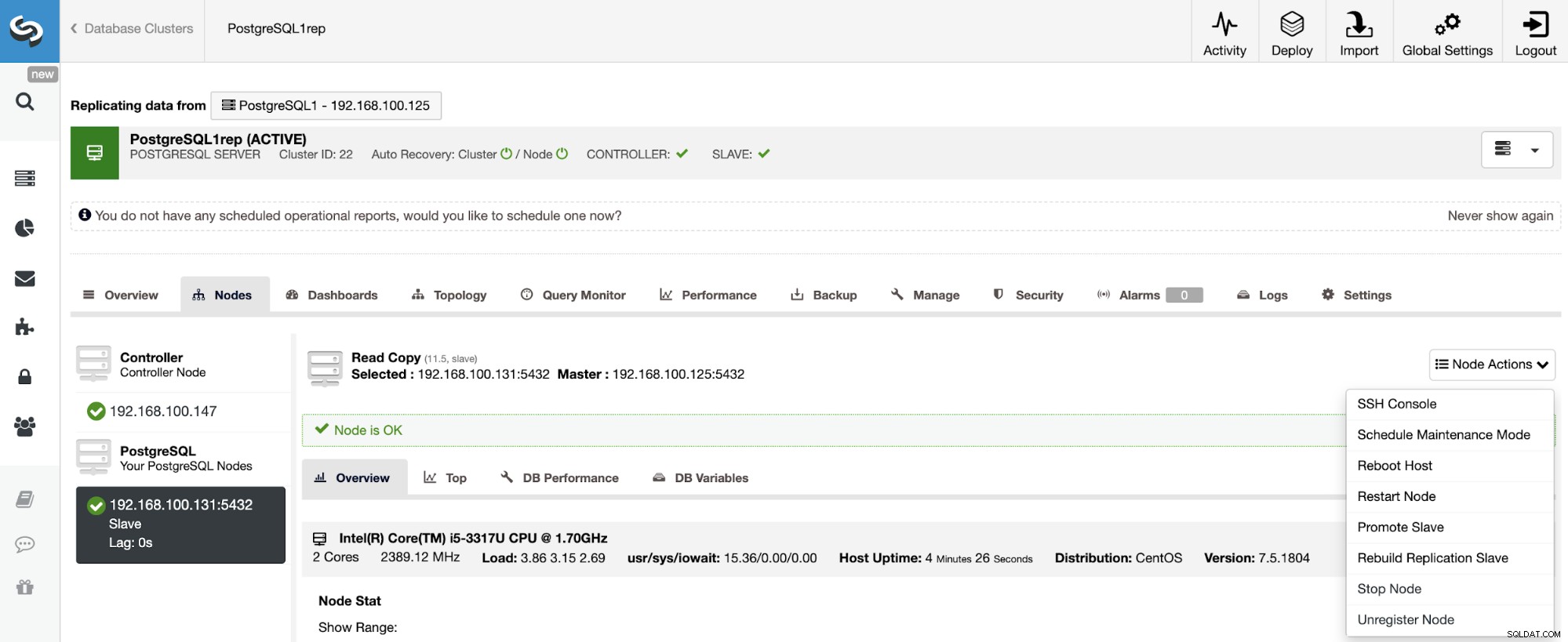
ClusterControl निम्न चरणों का पालन करेगा:
- PostgreSQL सर्वर बंद करें
- सामग्री को उसके डेटादिर से निकालें
- pg_basebackup का उपयोग करके मास्टर से स्लेव में बैकअप स्ट्रीम करें
- गुलाम शुरू करें
प्रतिकृति दास को रोकें/शुरू करें
पोस्टग्रेएसक्यूएल में स्टॉप एंड स्टार्ट प्रतिकृति का अर्थ है इसे रोकना और फिर से शुरू करना, लेकिन हम इन शर्तों का उपयोग उन अन्य डेटाबेस तकनीकों के अनुरूप होने के लिए करते हैं जिनका हम समर्थन करते हैं।
यह फ़ंक्शन जल्द ही ClusterControl UI से उपयोग के लिए उपलब्ध होगा। यह क्रिया इस कार्य को करने के लिए pg_wal_replay_pause और pg_wal_replay_resume PostgreSQL फ़ंक्शन का उपयोग करेगी।
इस बीच, आप क्लस्टरकंट्रोल का उपयोग करके डेटाबेस नोड को रोकने और डेटाबेस नोड को आसान तरीके से शुरू करने को रोकने और शुरू करने के लिए वर्कअराउंड का उपयोग कर सकते हैं।
ClusterControl पर जाएं -> स्लेव क्लस्टर चुनें -> नोड्स -> चुनें नोड -> नोड क्रियाएँ -> नोड रोकें/नोड प्रारंभ करें। यह क्रिया सीधे डेटाबेस सेवा को रोक/शुरू करेगी।
ClusterControl CLI का उपयोग करके क्लस्टर-टू-क्लस्टर प्रतिकृति को प्रबंधित करना
पिछले अनुभाग में, आप यह देखने में सक्षम थे कि क्लस्टर-टू-क्लस्टर प्रतिकृति को ClusterControl UI का उपयोग करके कैसे प्रबंधित किया जाए। अब, देखते हैं कि कमांड लाइन का उपयोग करके इसे कैसे करें।
ध्यान दें:जैसा कि हमने इस ब्लॉग की शुरुआत में उल्लेख किया है, हम मान लेंगे कि आपने ClusterControl स्थापित कर लिया है और इसका उपयोग करके मास्टर क्लस्टर को परिनियोजित किया गया है।
दास समूह बनाएं
सबसे पहले, आइए ClusterControl CLI का उपयोग करके स्लेव क्लस्टर बनाने के लिए एक उदाहरण कमांड देखते हैं:
$ s9s cluster --create --cluster-name=PostgreSQL1rep --cluster-type=postgresql --provider-version=11 --nodes="192.168.100.133" --os-user=root --os-key-file=/root/.ssh/id_rsa --db-admin=admin --db-admin-passwd=********* --vendor=postgres --remote-cluster-id=21 --logअब आपकी क्रिएट स्लेव प्रक्रिया चल रही है, आइए प्रत्येक उपयोग किए गए पैरामीटर को देखें:
- क्लस्टर:क्लस्टर्स को सूचीबद्ध करने और उनमें हेरफेर करने के लिए।
- बनाएं:एक नया क्लस्टर बनाएं और इंस्टॉल करें।
- क्लस्टर-नाम:नए स्लेव क्लस्टर का नाम।
- क्लस्टर-प्रकार:स्थापित करने के लिए क्लस्टर का प्रकार।
- प्रदाता-संस्करण:सॉफ़्टवेयर संस्करण।
- नोड्स:स्लेव क्लस्टर में नए नोड्स की सूची।
- Os-user:SSH कमांड के लिए यूजर नेम।
- Os-key-file:SSH कनेक्शन के लिए उपयोग की जाने वाली कुंजी फ़ाइल।
- Db-admin:डेटाबेस एडमिन यूजर नेम।
- Db-admin-passwd:डेटाबेस एडमिन के लिए पासवर्ड।
- रिमोट-क्लस्टर-आईडी:क्लस्टर-टू-क्लस्टर प्रतिकृति के लिए मास्टर क्लस्टर आईडी।
- लॉग:प्रतीक्षा करें और जॉब संदेशों की निगरानी करें।
--log ध्वज का उपयोग करके, आप वास्तविक समय में लॉग देख पाएंगे:
Verifying job parameters.
192.168.100.133: Checking ssh/sudo.
192.168.100.133: Checking if host already exists in another cluster.
Checking job arguments.
Found top level master node: 192.168.100.133
Verifying nodes.
Checking nodes that those aren't in another cluster.
Checking SSH connectivity and sudo.
192.168.100.133: Checking ssh/sudo.
Checking OS system tools.
Installing software.
Detected centos (core 7.5.1804).
Data directory was not specified. Using directory '/var/lib/pgsql/11/data'.
192.168.100.133:5432: Configuring host and installing packages if neccessary.
...
Cluster 26 is running.
Generated & set RPC authentication token.एक गुलाम समूह का पुनर्निर्माण
आप निम्न आदेश का उपयोग करके एक स्लेव क्लस्टर का पुनर्निर्माण कर सकते हैं:
$ s9s replication --stage --master="192.168.100.125" --slave="192.168.100.133" --cluster-id=26 --remote-cluster-id=21 --logपैरामीटर हैं:
- प्रतिकृति:डेटा प्रतिकृति की निगरानी और नियंत्रण के लिए।
- चरण:एक प्रतिकृति दास का चरण/पुनर्निर्माण।
- मास्टर:मास्टर क्लस्टर में प्रतिकृति मास्टर।
- दास:दास समूह में प्रतिकृति दास।
- क्लस्टर-आईडी:स्लेव क्लस्टर आईडी.
- रिमोट-क्लस्टर-आईडी:मास्टर क्लस्टर आईडी।
- लॉग:प्रतीक्षा करें और जॉब संदेशों की निगरानी करें।
जॉब लॉग इस के समान होना चाहिए:
Rebuild replication slave 192.168.100.133:5432 from master 192.168.100.125:5432.
Remote cluster id = 21
192.168.100.125: Checking size of '/var/lib/pgsql/11/data'.
192.168.100.125: /var/lib/pgsql/11/data size is 201.13 MiB.
192.168.100.133: Checking free space in '/var/lib/pgsql/11/data'.
192.168.100.133: /var/lib/pgsql/11/data has 28.78 GiB free space.
192.168.100.125:5432(master): Verifying PostgreSQL version.
192.168.100.125: Verifying the timescaledb-postgresql-11 installation.
192.168.100.125: Package timescaledb-postgresql-11 is not installed.
Setting up replication 192.168.100.125:5432->192.168.100.133:5432
Collecting server variables.
192.168.100.125:5432: Using the pg_hba.conf contents for the slave.
192.168.100.125:5432: Will copy the postmaster.opts to the slave.
192.168.100.133:5432: Updating slave configuration.
Writing file '192.168.100.133:/var/lib/pgsql/11/data/postgresql.conf'.
192.168.100.133:5432: GRANT new node on members to do pg_basebackup.
192.168.100.125:5432: granting 192.168.100.133:5432.
192.168.100.133:5432: Stopping slave.
192.168.100.133:5432: Stopping PostgreSQL node.
192.168.100.133: waiting for server to shut down.... done
server stopped
…
192.168.100.133: waiting for server to start....2019-11-12 15:51:11.767 UTC [8005] LOG: listening on IPv4 address "0.0.0.0", port 5432
2019-11-12 15:51:11.767 UTC [8005] LOG: listening on IPv6 address "::", port 5432
2019-11-12 15:51:11.769 UTC [8005] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
2019-11-12 15:51:11.774 UTC [8005] LOG: listening on Unix socket "/tmp/.s.PGSQL.5432"
2019-11-12 15:51:11.798 UTC [8005] LOG: redirecting log output to logging collector process
2019-11-12 15:51:11.798 UTC [8005] HINT: Future log output will appear in directory "log".
done
server started
192.168.100.133:5432: Grant cluster members on the new node (for failover).
Grant connect access for new host in cluster.
Adding grant on 192.168.100.125:5432.
192.168.100.133:5432: Waiting until the service is started.
Replication slave job finished.प्रतिकृति दास को रोकें/शुरू करें
जैसा कि हमने UI अनुभाग में उल्लेख किया है, PostgreSQL में स्टॉप एंड स्टार्ट प्रतिकृति का अर्थ है इसे रोकना और फिर से शुरू करना, लेकिन हम इन शर्तों का उपयोग अन्य तकनीकों के साथ समानता बनाए रखने के लिए करते हैं।
आप इस तरह से मास्टर क्लस्टर से डेटा को दोहराने के लिए रुक सकते हैं:
$ s9s replication --stop --slave="192.168.100.133" --cluster-id=26 --logआप इसे देखेंगे:
192.168.100.133:5432: Pausing recovery of the slave.
192.168.100.133:5432: Successfully paused recovery on the slave using select pg_wal_replay_pause().और अब, आप इसे फिर से शुरू कर सकते हैं:
$ s9s replication --start --slave="192.168.100.133" --cluster-id=26 --logतो, आप देखेंगे:
192.168.100.133:5432: Resuming recovery on the slave.
192.168.100.133:5432: Collecting replication statistics.
192.168.100.133:5432: Slave resumed recovery successfully using select pg_wal_replay_resume().अब, उपयोग किए गए मापदंडों की जांच करते हैं।
- प्रतिकृति:डेटा प्रतिकृति की निगरानी और नियंत्रण के लिए।
- रोकें/शुरू करें:दास को रोकने/प्रतिकृति शुरू करने के लिए।
- दास:प्रतिकृति दास नोड।
- क्लस्टर-आईडी:उस क्लस्टर की आईडी जिसमें स्लेव नोड है।
- लॉग:प्रतीक्षा करें और जॉब संदेशों की निगरानी करें।
निष्कर्ष
यह नया क्लस्टरकंट्रोल फीचर आपको विभिन्न पोस्टग्रेएसक्यूएल क्लस्टर्स के बीच तेजी से प्रतिकृति स्थापित करने और एक आसान और मैत्रीपूर्ण तरीके से सेटअप का प्रबंधन करने की अनुमति देगा। सीवेरिनाइन्स देव टीम इस सुविधा को बढ़ाने पर काम कर रही है, इसलिए किसी भी विचार या सुझाव का स्वागत किया जाएगा।