अपने पिछले ब्लॉग में, हमने एक ही टेबल से डेटा को चुनने या स्कैन करने के विभिन्न तरीकों पर चर्चा की थी। लेकिन व्यावहारिक रूप से, एक ही टेबल से डेटा प्राप्त करना पर्याप्त नहीं है। इसके लिए कई तालिकाओं से डेटा का चयन करना और फिर उनके बीच सहसंबंध बनाना आवश्यक है। तालिकाओं के बीच इस डेटा के सहसंबंध को तालिकाओं में शामिल होना कहा जाता है और इसे विभिन्न तरीकों से किया जा सकता है। चूंकि तालिकाओं में शामिल होने के लिए इनपुट डेटा की आवश्यकता होती है (उदाहरण के लिए टेबल स्कैन से), यह कभी भी उत्पन्न योजना में एक लीफ नोड नहीं हो सकता है।
उदा. एक साधारण क्वेरी उदाहरण के रूप में चुनें * TBL1, TBL2 से चुनें जहां TBL1.ID> TBL2.ID; और मान लीजिए कि तैयार की गई योजना इस प्रकार है:
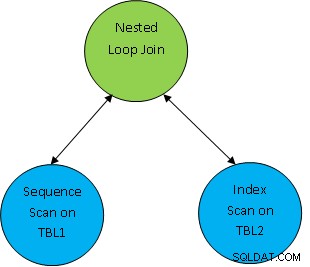
इसलिए यहां पहले दोनों तालिकाओं को स्कैन किया जाता है और फिर उन्हें एक साथ जोड़ दिया जाता है जैसे TBL.ID> TBL2.ID
. के रूप में सहसंबंध की स्थिति के अनुसारजॉइन मेथड के अलावा, जॉइन ऑर्डर भी बहुत महत्वपूर्ण है। नीचे दिए गए उदाहरण पर विचार करें:
TBL1, TBL2, TBL3 से चुनें * जहां TBL1.ID=TBL2.ID और TBL2.ID=TBL3.ID;
विचार करें कि TBL1, TBL2 और TBL3 में क्रमशः 10, 100 और 1000 रिकॉर्ड हैं।
स्थिति TBL1.ID=TBL2.ID केवल 5 रिकॉर्ड लौटाती है, जबकि TBL2.ID=TBL3.ID 100 रिकॉर्ड लौटाती है, तो पहले TBL1 और TBL2 में शामिल होना बेहतर है ताकि कम संख्या में रिकॉर्ड मिलें TBL3 के साथ जुड़ गया। योजना नीचे दिखाए अनुसार होगी:
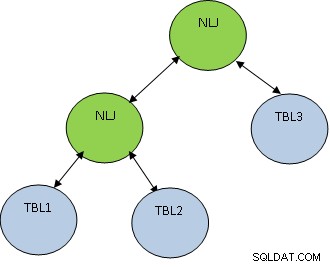
PostgreSQL निम्न प्रकार के जॉइन का समर्थन करता है:
- नेस्टेड लूप जॉइन करें
- हैश जॉइन करें
- शामिल हों
इनमें से प्रत्येक शामिल होने के तरीके क्वेरी और अन्य मापदंडों के आधार पर समान रूप से उपयोगी हैं उदा। क्वेरी, टेबल डेटा, जॉइन क्लॉज, सेलेक्टिविटी, मेमोरी आदि। ये जुड़ने के तरीके अधिकांश रिलेशनल डेटाबेस द्वारा कार्यान्वित किए जाते हैं।
आइए कुछ पूर्व-सेटअप तालिका बनाते हैं और कुछ डेटा से भरते हैं, जिसका उपयोग इन स्कैन विधियों को बेहतर ढंग से समझाने के लिए अक्सर किया जाएगा।
postgres=# create table blogtable1(id1 int, id2 int);
CREATE TABLE
postgres=# create table blogtable2(id1 int, id2 int);
CREATE TABLE
postgres=# insert into blogtable1 values(generate_series(1,10000),3);
INSERT 0 10000
postgres=# insert into blogtable2 values(generate_series(1,1000),3);
INSERT 0 1000
postgres=# analyze;
ANALYZEहमारे बाद के सभी उदाहरणों में, हम डिफ़ॉल्ट कॉन्फ़िगरेशन पैरामीटर पर विचार करते हैं जब तक कि अन्यथा विशेष रूप से निर्दिष्ट न किया गया हो।
नेस्टेड लूप जॉइन
नेस्टेड लूप जॉइन (एनएलजे) सबसे सरल जॉइन एल्गोरिथम है जिसमें बाहरी संबंध के प्रत्येक रिकॉर्ड का आंतरिक संबंध के प्रत्येक रिकॉर्ड से मिलान किया जाता है। शर्त A.ID नेस्टेड लूप जॉइन (एनएलजे) सबसे आम जॉइनिंग मेथड है और इसका उपयोग लगभग किसी भी डेटासेट पर किसी भी प्रकार के जॉइन क्लॉज के साथ किया जा सकता है। चूंकि यह एल्गोरिथम आंतरिक और बाहरी संबंध के सभी टुपल्स को स्कैन करता है, इसलिए इसे सबसे महंगा जॉइन ऑपरेशन माना जाता है। उपरोक्त तालिका और डेटा के अनुसार, निम्न क्वेरी के परिणामस्वरूप नेस्टेड लूप जॉइन होगा जैसा कि नीचे दिखाया गया है: चूंकि जॉइन क्लॉज "<" है, इसलिए यहां शामिल होने का एकमात्र संभावित तरीका नेस्टेड लूप जॉइन है। यहाँ एक नए प्रकार के नोड पर ध्यान दें जैसे कि अमल में लाना; यह नोड इंटरमीडिएट परिणाम कैश के रूप में कार्य करता है यानी एक संबंध के सभी टुपल्स को कई बार लाने के बजाय, पहली बार प्राप्त परिणाम स्मृति में संग्रहीत किया जाता है और अगले अनुरोध पर टपल प्राप्त करने के लिए फिर से संबंध पृष्ठों से लाने के बजाय स्मृति से परोसा जाएगा . यदि सभी टुपल्स मेमोरी में फिट नहीं हो सकते हैं, तो स्पिल-ओवर टुपल्स एक अस्थायी फ़ाइल में जाते हैं। यह नेस्टेड लूप जॉइन के मामले में और कुछ हद तक मर्ज जॉइन के मामले में उपयोगी है क्योंकि वे आंतरिक संबंध के पुन:स्कैन पर भरोसा करते हैं। मैटेरियलाइज़ नोड केवल रिलेशन के कैशिंग परिणाम तक ही सीमित नहीं है बल्कि यह प्लान ट्री में नीचे किसी भी नोड के परिणामों को कैश कर सकता है। टिप:यदि जॉइन क्लॉज "=" है और नेस्टेड लूप जॉइन को एक रिलेशन के बीच चुना जाता है, तो यह जांचना वास्तव में महत्वपूर्ण है कि क्या हैश या मर्ज जॉइन जैसी अधिक कुशल जॉइन विधि को चुना जा सकता है ट्यूनिंग कॉन्फ़िगरेशन (उदाहरण के लिए work_mem लेकिन इन्हीं तक सीमित नहीं) या एक इंडेक्स आदि जोड़कर। कुछ प्रश्नों में जॉइन क्लॉज नहीं हो सकता है, उस स्थिति में भी शामिल होने का एकमात्र विकल्प नेस्टेड लूप जॉइन है। उदा. पूर्व-सेटअप डेटा के अनुसार नीचे दिए गए प्रश्नों पर विचार करें: उपरोक्त उदाहरण में शामिल होना दोनों तालिकाओं का कार्टेशियन उत्पाद है। यह एल्गोरिथम दो चरणों में काम करता है: शर्त A.ID =B.ID के साथ संबंध A और B के बीच जुड़ाव को नीचे दर्शाया जा सकता है: उपरोक्त पूर्व-सेटअप तालिका और डेटा के अनुसार, निम्न क्वेरी के परिणामस्वरूप हैश जॉइन होगा जैसा कि नीचे दिखाया गया है: यहां हैश टेबल ब्लॉगटेबल2 टेबल पर बनाई गई है क्योंकि यह छोटी टेबल है इसलिए हैश टेबल और पूरी हैश टेबल के लिए जरूरी न्यूनतम मेमोरी मेमोरी में फिट हो सकती है। मर्ज जॉइन एक एल्गोरिथम है जिसमें बाहरी संबंध के प्रत्येक रिकॉर्ड को आंतरिक संबंध के प्रत्येक रिकॉर्ड के साथ तब तक मिलान किया जाता है जब तक कि क्लॉज मिलान में शामिल होने की संभावना न हो। यह जॉइन एल्गोरिथम केवल तभी उपयोग किया जाता है जब दोनों संबंधों को क्रमबद्ध किया जाता है और क्लॉज ऑपरेटर "=" में शामिल होता है। शर्त A.ID =B.ID के साथ संबंध A और B के बीच जुड़ाव को नीचे दर्शाया जा सकता है: उदाहरण क्वेरी जिसके परिणामस्वरूप हैश जॉइन हुआ, जैसा कि ऊपर दिखाया गया है, यदि इंडेक्स दोनों टेबलों पर बन जाता है तो मर्ज जॉइन हो सकता है। ऐसा इसलिए है क्योंकि तालिका डेटा को इंडेक्स के कारण क्रमबद्ध क्रम में पुनर्प्राप्त किया जा सकता है, जो कि मर्ज जॉइन विधि के प्रमुख मानदंडों में से एक है: इसलिए, जैसा कि हम देखते हैं, दोनों टेबल अनुक्रमिक स्कैन के बजाय इंडेक्स स्कैन का उपयोग कर रहे हैं, जिसके कारण दोनों टेबल सॉर्ट किए गए रिकॉर्ड का उत्सर्जन करेंगे। PostgreSQL विभिन्न प्लानर संबंधित कॉन्फ़िगरेशन का समर्थन करता है, जिसका उपयोग क्वेरी ऑप्टिमाइज़र को संकेत देने के लिए किया जा सकता है कि कुछ विशेष प्रकार के जुड़ने के तरीकों का चयन न करें। यदि ऑप्टिमाइज़र द्वारा चुनी गई जॉइन विधि इष्टतम नहीं है, तो इन कॉन्फ़िगरेशन पैरामीटर को क्वेरी ऑप्टिमाइज़र को अलग-अलग प्रकार की जॉइन विधियों को चुनने के लिए बाध्य करने के लिए स्विच-ऑफ किया जा सकता है। ये सभी कॉन्फ़िगरेशन पैरामीटर डिफ़ॉल्ट रूप से "चालू" हैं। शामिल होने के तरीकों के लिए विशिष्ट प्लानर कॉन्फ़िगरेशन पैरामीटर नीचे दिए गए हैं। विभिन्न उद्देश्यों के लिए उपयोग किए जाने वाले कई योजना संबंधी कॉन्फ़िगरेशन पैरामीटर हैं। इस ब्लॉग में, इसे केवल जुड़ने के तरीकों तक ही सीमित रखा गया है। इन मापदंडों को किसी विशेष सत्र से संशोधित किया जा सकता है। इसलिए यदि हम किसी विशेष सत्र से योजना के साथ प्रयोग करना चाहते हैं, तो इन कॉन्फ़िगरेशन मापदंडों में हेरफेर किया जा सकता है और अन्य सत्र अभी भी वैसे ही काम करते रहेंगे। अब, मर्ज जॉइन और हैश जॉइन के उपरोक्त उदाहरणों पर विचार करें। इंडेक्स के बिना, क्वेरी ऑप्टिमाइज़र ने नीचे दी गई क्वेरी के लिए हैश जॉइन का चयन किया, जैसा कि नीचे दिखाया गया है, लेकिन कॉन्फ़िगरेशन का उपयोग करने के बाद, यह इंडेक्स के बिना भी मर्ज में शामिल हो जाता है: शुरुआत में हैश जॉइन को चुना जाता है क्योंकि टेबल से डेटा सॉर्ट नहीं किया जाता है। मर्ज जॉइन प्लान को चुनने के लिए, इसे पहले दोनों टेबलों से प्राप्त सभी रिकॉर्ड्स को सॉर्ट करना होगा और फिर मर्ज जॉइन को लागू करना होगा। तो, छँटाई की लागत अतिरिक्त होगी और इसलिए कुल लागत में वृद्धि होगी। तो संभवतः, इस मामले में, कुल (बढ़ी हुई सहित) लागत हैश जॉइन की कुल लागत से अधिक है, इसलिए हैश जॉइन को चुना जाता है। एक बार कॉन्फ़िगरेशन पैरामीटर enable_hashjoin को "ऑफ" में बदल दिया जाता है, इसका मतलब है कि क्वेरी ऑप्टिमाइज़र सीधे हैश जॉइन के लिए डिसेबल कॉस्ट (=1.0e10 यानी 10000000000.00) के रूप में एक लागत असाइन करता है। किसी भी संभावित जॉइन की कीमत इससे कम होगी। इसलिए, सक्षम_हैशजॉइन को "ऑफ" में बदलने के बाद मर्ज जॉइन में एक ही क्वेरी परिणाम सॉर्टिंग लागत सहित, मर्ज जॉइन की कुल लागत अक्षम लागत से कम है। अब नीचे दिए गए उदाहरण पर विचार करें: जैसा कि हम ऊपर देख सकते हैं, भले ही नेस्टेड लूप जॉइन संबंधित कॉन्फ़िगरेशन पैरामीटर को "ऑफ" में बदल दिया गया हो, फिर भी यह नेस्टेड लूप जॉइन को चुनता है क्योंकि प्राप्त करने के लिए किसी अन्य प्रकार की जॉइन विधि की कोई वैकल्पिक संभावना नहीं है। चुन लिया। सरल शब्दों में, चूंकि नेस्टेड लूप जॉइन ही एकमात्र संभव जॉइन है, तो जो भी कीमत हो वह हमेशा विजेता होगा (उसी तरह जैसे मैं 100 मीटर दौड़ में विजेता हुआ करता था अगर मैं अकेला दौड़ता था… :-))। साथ ही, पहली और दूसरी योजना में लागत में अंतर पर ध्यान दें। पहली योजना नेस्टेड लूप जॉइन की वास्तविक लागत दिखाती है लेकिन दूसरी योजना उसी की अक्षम लागत दिखाती है। सभी प्रकार के पोस्टग्रेएसक्यूएल जॉइन मेथड उपयोगी होते हैं और क्वेरी, डेटा, जॉइन क्लॉज आदि की प्रकृति के आधार पर चुने जाते हैं। यदि क्वेरी अपेक्षित रूप से प्रदर्शन नहीं कर रही है, यानी जुड़ने के तरीके नहीं हैं उम्मीद के मुताबिक चुने जाने पर, उपयोगकर्ता उपलब्ध विभिन्न योजना कॉन्फ़िगरेशन पैरामीटर के साथ खेल सकता है और देख सकता है कि कुछ गुम है या नहीं।For each tuple r in A
For each tuple s in B
If (r.ID < s.ID)
Emit output tuple (r,s)postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 < bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (bt1.id1 < bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# explain select * from blogtable1, blogtable2;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..125162.50 rows=10000000 width=16)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(4 rows)हैश जॉइन करें
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (bt1.id1 = bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows) मर्ज करें
For each tuple r in A
For each tuple s in B
If (r.ID = s.ID)
Emit output tuple (r,s)
Break;
If (r.ID > s.ID)
Continue;
Else
Break;postgres=# create index idx1 on blogtable1(id1);
CREATE INDEX
postgres=# create index idx2 on blogtable2(id1);
CREATE INDEX
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
---------------------------------------------------------------------------------------
Merge Join (cost=0.56..90.36 rows=1000 width=16)
Merge Cond: (bt1.id1 = bt2.id1)
-> Index Scan using idx1 on blogtable1 bt1 (cost=0.29..318.29 rows=10000 width=8)
-> Index Scan using idx2 on blogtable2 bt2 (cost=0.28..43.27 rows=1000 width=8)
(4 rows)कॉन्फ़िगरेशन
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (blogtable1.id1 = blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_hashjoin to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
----------------------------------------------------------------------------
Merge Join (cost=874.21..894.21 rows=1000 width=16)
Merge Cond: (blogtable1.id1 = blogtable2.id1)
-> Sort (cost=809.39..834.39 rows=10000 width=8)
Sort Key: blogtable1.id1
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: blogtable2.id1
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(8 rows)postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_nestloop to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=10000000000.00..10000150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)निष्कर्ष



