उत्पादन के माहौल में होने वाली सभी संभावित समस्याओं से बचने के लिए कोई सही सिस्टम, हार्डवेयर या टोपोलॉजी नहीं है। इन चुनौतियों पर काबू पाने के लिए एक प्रभावी डीआरपी (आपदा वसूली योजना) की आवश्यकता होती है, जिसे आपके आवेदन, बुनियादी ढांचे और व्यावसायिक आवश्यकताओं के अनुसार कॉन्फ़िगर किया गया हो। इस प्रकार की स्थितियों में सफलता की कुंजी हमेशा यह होती है कि हम समस्या को कितनी तेजी से ठीक कर सकते हैं या उससे उबर सकते हैं।
इस ब्लॉग में हम सबसे आम PostgreSQL विफलता परिदृश्यों पर एक नज़र डालेंगे और आपको दिखाएंगे कि आप समस्याओं को कैसे हल कर सकते हैं या उनका सामना कैसे कर सकते हैं। हम यह भी देखेंगे कि कैसे ClusterControl ऑनलाइन वापस आने में हमारी मदद कर सकता है
सामान्य PostgreSQL टोपोलॉजी
सामान्य विफलता परिदृश्यों को समझने के लिए, आपको पहले एक सामान्य PostgreSQL टोपोलॉजी के साथ शुरुआत करनी होगी। यह पोस्टग्रेएसक्यूएल प्राइमरी नोड से जुड़ा कोई भी एप्लिकेशन हो सकता है जिसमें इसकी एक प्रतिकृति जुड़ी हो।
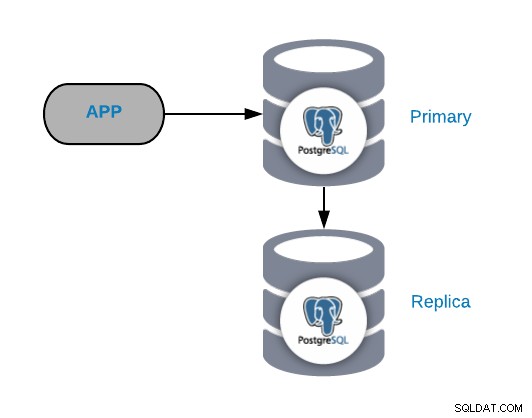
आप अधिक नोड्स या लोड बैलेंसर्स जोड़कर इस टोपोलॉजी में हमेशा सुधार या विस्तार कर सकते हैं , लेकिन यह मूल टोपोलॉजी है जिसके साथ हम काम करना शुरू करेंगे।
प्राथमिक PostgreSQL नोड विफलता
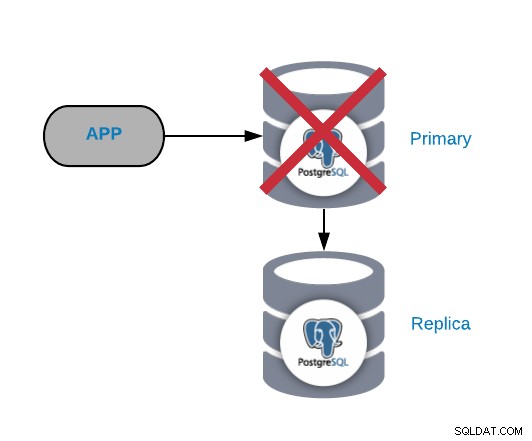
यह सबसे महत्वपूर्ण विफलताओं में से एक है क्योंकि हमें इसे जल्द से जल्द ठीक करना चाहिए यदि हम अपने सिस्टम को ऑनलाइन रखना चाहते हैं। इस प्रकार की विफलता के लिए किसी प्रकार की स्वचालित विफलता तंत्र का होना महत्वपूर्ण है। विफलता के बाद, आप मुद्दों के कारणों पर गौर कर सकते हैं। विफलता प्रक्रिया के बाद, हम सुनिश्चित करते हैं कि विफल प्राथमिक नोड अभी भी यह नहीं सोचता कि यह प्राथमिक नोड है। यह लिखते समय डेटा असंगति से बचने के लिए है।
इस प्रकार की समस्या के सबसे सामान्य कारण ऑपरेटिंग सिस्टम की विफलता, हार्डवेयर विफलता या डिस्क विफलता हैं। किसी भी मामले में, हमें इसका कारण जानने के लिए डेटाबेस और ऑपरेटिंग सिस्टम लॉग की जांच करनी चाहिए।
इस समस्या का सबसे तेज़ समाधान डाउनटाइम को कम करने के लिए एक विफलता कार्य करना है एक प्रतिकृति को बढ़ावा देने के लिए हम दास डेटाबेस नोड पर pg_ctl प्रचार कमांड का उपयोग कर सकते हैं, और फिर, हमें से ट्रैफ़िक भेजना होगा नए प्राथमिक नोड के लिए आवेदन। इस अंतिम कार्य के लिए, हम विफलता के मामले में एप्लिकेशन पक्ष से किसी भी बदलाव से बचने के लिए, हमारे एप्लिकेशन और डेटाबेस नोड्स के बीच लोड बैलेंसर लागू कर सकते हैं। हम नोड की विफलता का पता लगाने के लिए लोड बैलेंसर को भी कॉन्फ़िगर कर सकते हैं और उसे ट्रैफ़िक भेजने के बजाय, नए प्राथमिक नोड पर ट्रैफ़िक भेज सकते हैं।
विफलता प्रक्रिया के बाद और सुनिश्चित करें कि सिस्टम फिर से काम कर रहा है, हम इस मुद्दे पर गौर कर सकते हैं, और हम कम से कम एक स्लेव नोड को हमेशा काम करते रहने की सलाह देते हैं, इसलिए एक नई प्राथमिक विफलता के मामले में, हम फ़ेलओवर कार्य फिर से कर सकते हैं।
PostgreSQL रेप्लिका नोड विफलता
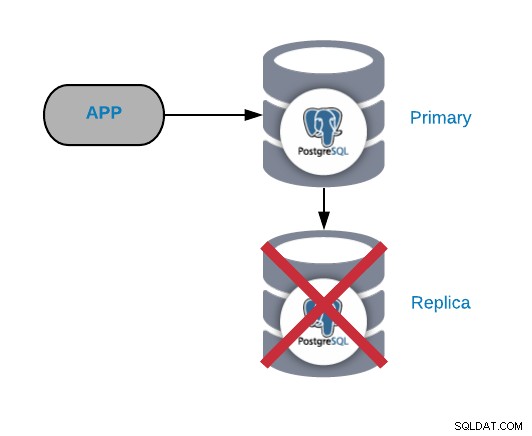
यह सामान्य रूप से एक गंभीर समस्या नहीं है (जब तक आपके पास इससे अधिक है एक प्रतिकृति और रीड प्रोडक्शन ट्रैफिक भेजने के लिए इसका उपयोग नहीं कर रहे हैं)। यदि आप प्राथमिक नोड पर समस्याओं का सामना कर रहे हैं, और आपकी प्रतिकृति अप-टू-डेट नहीं है, तो आपके पास एक वास्तविक गंभीर समस्या होगी। यदि आप रिपोर्टिंग या बड़े डेटा उद्देश्यों के लिए हमारी प्रतिकृति का उपयोग कर रहे हैं, तो आप शायद इसे जल्दी से ठीक करना चाहेंगे।
इस तरह की समस्या के सबसे सामान्य कारण वही हैं जो हमने प्राथमिक नोड, एक ऑपरेटिंग सिस्टम विफलता, हार्डवेयर विफलता, या डिस्क विफलता के लिए देखे थे। आपको डेटाबेस और ऑपरेटिंग सिस्टम लॉग की जांच करनी चाहिए। कारण खोजने के लिए।
सिस्टम को बिना किसी प्रतिकृति के काम करने की अनुशंसा नहीं की जाती है, क्योंकि विफलता के मामले में, आपके पास ऑनलाइन वापस आने का कोई तेज़ तरीका नहीं है। यदि आपके पास केवल एक दास है, तो आपको समस्या को यथाशीघ्र हल करना चाहिए; खरोंच से एक नई प्रतिकृति बनाकर सबसे तेज़ तरीका है। इसके लिए आपको लगातार बैकअप लेना होगा और इसे स्लेव नोड में पुनर्स्थापित करना होगा, फिर इस स्लेव नोड और प्राथमिक नोड के बीच प्रतिकृति को कॉन्फ़िगर करना होगा।
यदि आप विफलता का कारण जानना चाहते हैं, तो आपको नई प्रतिकृति बनाने के लिए किसी अन्य सर्वर का उपयोग करना चाहिए, और फिर इसे खोजने के लिए पुराने सर्वर को देखना चाहिए। जब आप इस कार्य को पूरा कर लेते हैं, तो आप पुरानी प्रतिकृति को फिर से कॉन्फ़िगर भी कर सकते हैं और दोनों को भविष्य के फ़ेलओवर विकल्प के रूप में काम करते हुए रख सकते हैं।
यदि आप रिपोर्टिंग के लिए या बड़े डेटा उद्देश्यों के लिए प्रतिकृति का उपयोग कर रहे हैं, तो नए से कनेक्ट करने के लिए आपको IP पता बदलना होगा। पिछले मामले की तरह, इस परिवर्तन से बचने का एक तरीका लोड बैलेंसर का उपयोग करना है जो प्रत्येक सर्वर की स्थिति को जानेगा, जिससे आप अपनी इच्छानुसार प्रतिकृतियां जोड़/निकाल सकते हैं।
PostgreSQL प्रतिकृति विफलता
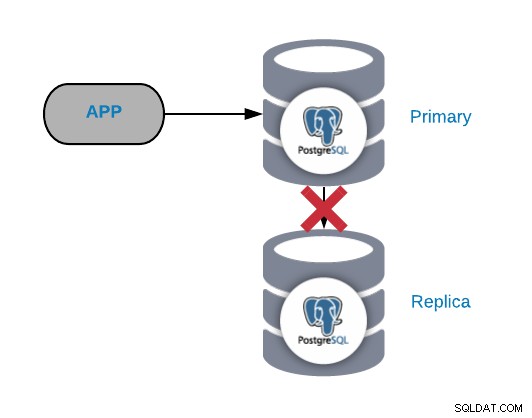
सामान्य तौर पर, इस तरह की समस्या किसी नेटवर्क या कॉन्फ़िगरेशन के कारण उत्पन्न होती है मुद्दा। यह प्राथमिक नोड में WAL (राइट-अहेड लॉगिंग) के नुकसान से संबंधित है और PostgreSQL जिस तरह से प्रतिकृति का प्रबंधन करता है।
यदि आपके पास महत्वपूर्ण ट्रैफ़िक है, तो आप बहुत बार चेकपॉइंट कर रहे हैं, या आप केवल कुछ मिनटों के लिए WALS संग्रहीत कर रहे हैं; यदि आपके पास नेटवर्क समस्या है तो आपके पास इसे हल करने के लिए बहुत कम समय होगा। आपके द्वारा प्रतिकृति पर भेजने और लागू करने से पहले आपके WAL को हटा दिया जाएगा।
यदि प्रतिकृति को काम करना जारी रखने के लिए आवश्यक WAL को हटा दिया गया था, तो आपको इसे फिर से बनाने की आवश्यकता है, इसलिए इस कार्य से बचने के लिए, हमें wal_keep_segments (WALS की मात्रा में रखने के लिए) को बढ़ाने के लिए हमारे डेटाबेस कॉन्फ़िगरेशन की जांच करनी चाहिए। pg_xlog निर्देशिका) या max_wal_senders (एक साथ चलने वाली WAL प्रेषक प्रक्रियाओं की अधिकतम संख्या) पैरामीटर।
एक अन्य अनुशंसित विकल्प है कि आर्काइव_मोड को कॉन्फ़िगर करें और वाल फाइलों को पैरामीटर आर्काइव_कमांड के साथ दूसरे पथ पर भेजें। इस तरह, यदि PostgreSQL सीमा तक पहुँच जाता है और WAL फ़ाइल को हटा देता है, तो हम इसे किसी अन्य पथ में वैसे भी प्राप्त करेंगे।
PostgreSQL डेटा भ्रष्टाचार / डेटा असंगति / आकस्मिक विलोपन

यह किसी भी डीबीए के लिए एक बुरा सपना है और संभवत:सबसे जटिल समस्या है। समस्या कितनी व्यापक है, इस पर निर्भर करता है।
जब आपका डेटा इनमें से कुछ समस्याओं से प्रभावित होता है, तो इसे ठीक करने का सबसे सामान्य तरीका (और शायद केवल एक ही) बैकअप पुनर्स्थापित करना है। यही कारण है कि बैकअप किसी भी आपदा वसूली योजना का मूल रूप है और यह अनुशंसा की जाती है कि आपके पास विभिन्न भौतिक स्थानों में कम से कम तीन बैकअप संग्रहीत हों। सर्वोत्तम अभ्यास यह निर्धारित करता है कि बैकअप फ़ाइलों में से एक को स्थानीय रूप से डेटाबेस सर्वर (तेजी से पुनर्प्राप्ति के लिए) पर संग्रहीत किया जाना चाहिए, दूसरा एक केंद्रीकृत बैकअप सर्वर में, और अंतिम एक क्लाउड पर होना चाहिए।
हम अपने पुनर्प्राप्ति बिंदु उद्देश्य को कम करने के लिए पूर्ण/वृद्धिशील/अंतर PITR संगत बैकअप का मिश्रण भी बना सकते हैं।
ClusterControl के साथ PostgreSQL विफलता को प्रबंधित करना
अब जब हमने इन सामान्य PostgreSQL विफलता परिदृश्यों को देख लिया है तो आइए देखें कि यदि हम आपके PostgreSQL डेटाबेस को एक केंद्रीकृत डेटाबेस प्रबंधन प्रणाली से प्रबंधित कर रहे हैं तो क्या होगा। एक समस्या को ठीक करने के लिए एक तेज़ और आसान तरीका तक पहुँचने के मामले में बहुत अच्छा है, विफलता के मामले में ASAP।
ClusterControl ऊपर वर्णित अधिकांश PostgreSQL कार्यों के लिए स्वचालन प्रदान करता है; सभी एक केंद्रीकृत और उपयोगकर्ता के अनुकूल तरीके से। इस प्रणाली के साथ आप उन चीजों को आसानी से कॉन्फ़िगर करने में सक्षम होंगे, जिनमें मैन्युअल रूप से समय और प्रयास लगेगा। अब हम PostgreSQL विफलता परिदृश्यों से संबंधित इसकी कुछ मुख्य विशेषताओं की समीक्षा करेंगे।
एक PostgreSQL क्लस्टर परिनियोजित/आयात करें
एक बार जब हम ClusterControl इंटरफ़ेस में प्रवेश कर जाते हैं, तो सबसे पहले एक नया क्लस्टर परिनियोजित करना या किसी मौजूदा को आयात करना होता है। एक परिनियोजन करने के लिए, बस विकल्प चुनें डेटाबेस क्लस्टर परिनियोजित करें और दिखाई देने वाले निर्देशों का पालन करें।
अपने PostgreSQL क्लस्टर को स्केल करना
यदि आप क्लस्टर क्रियाओं पर जाते हैं और प्रतिकृति स्लेव जोड़ें का चयन करते हैं, तो आप या तो खरोंच से एक नई प्रतिकृति बना सकते हैं या एक मौजूदा PostgreSQL डेटाबेस को प्रतिकृति के रूप में जोड़ सकते हैं। इस तरह, आप कुछ ही मिनटों में अपनी नई प्रतिकृति चला सकते हैं और हम जितनी चाहें उतनी प्रतिकृतियां जोड़ सकते हैं; लोड बैलेंसर (जिसे हम ClusterControl के साथ भी लागू कर सकते हैं) का उपयोग करके उनके बीच पठन यातायात फैलाना।
PostgreSQL स्वचालित विफलता
ClusterControl आपके प्रतिकृति सेटअप पर विफलता का प्रबंधन करता है। यह मास्टर विफलताओं का पता लगाता है और नए मास्टर के रूप में सबसे वर्तमान डेटा वाले दास को बढ़ावा देता है। यह स्वचालित रूप से विफल हो जाता है-बाकी दासों पर नए स्वामी से दोहराने के लिए। क्लाइंट कनेक्शन के लिए, यह कार्य के लिए दो टूल का लाभ उठाता है:HAProxy और Keepalived।
HAProxy एक लोड बैलेंसर है जो एक मूल से एक या अधिक गंतव्यों तक ट्रैफ़िक वितरित करता है और कार्य के लिए विशिष्ट नियमों और/या प्रोटोकॉल को परिभाषित कर सकता है। यदि कोई भी गंतव्य प्रत्युत्तर देना बंद कर देता है, तो उसे ऑफ़लाइन के रूप में चिह्नित कर दिया जाता है, और ट्रैफ़िक उपलब्ध गंतव्यों में से किसी एक पर भेज दिया जाता है। यह ट्रैफ़िक को एक दुर्गम गंतव्य पर भेजने से रोकता है और इस जानकारी को एक वैध गंतव्य पर निर्देशित करके खो देता है।
Kepalived आपको सर्वर के एक सक्रिय/निष्क्रिय समूह के भीतर एक वर्चुअल आईपी कॉन्फ़िगर करने की अनुमति देता है। यह वर्चुअल आईपी एक सक्रिय "मुख्य" सर्वर को सौंपा गया है। यदि यह सर्वर विफल हो जाता है, तो आईपी स्वचालित रूप से "सेकेंडरी" सर्वर में माइग्रेट हो जाता है जो निष्क्रिय पाया गया था, जिससे यह हमारे सिस्टम के लिए पारदर्शी तरीके से उसी आईपी के साथ काम करना जारी रखता है।
एक PostgreSQL लोड बैलेंसर जोड़ना
यदि आप क्लस्टर क्रियाओं में जाते हैं और लोड बैलेंसर जोड़ें का चयन करते हैं (या क्लस्टर व्यू से - मैनेज -> लोड बैलेंसर पर जाएं) तो आप हमारे डेटाबेस टोपोलॉजी में लोड बैलेंसर जोड़ सकते हैं।
आपका नया लोड बैलेंसर बनाने के लिए आवश्यक कॉन्फ़िगरेशन काफी सरल है। आपको केवल IP/होस्टनाम, पोर्ट, नीति और उन नोड्स को जोड़ने की आवश्यकता है जिनका हम उपयोग करने जा रहे हैं। आप उनके बीच Keepalived के साथ दो लोड बैलेंसर जोड़ सकते हैं, जो हमें विफलता के मामले में हमारे लोड बैलेंसर की स्वचालित विफलता की अनुमति देता है। Keepalived एक वर्चुअल IP पते का उपयोग करता है, और विफलता की स्थिति में इसे एक लोड बैलेंसर से दूसरे में माइग्रेट करता है, ताकि हमारा सेटअप सामान्य रूप से कार्य करना जारी रख सके।
पोस्टग्रेएसक्यूएल बैकअप
हम पहले ही बैकअप रखने के महत्व पर चर्चा कर चुके हैं। ClusterControl तत्काल बैकअप या शेड्यूल एक उत्पन्न करने के लिए कार्यक्षमता प्रदान करता है।
आप तीन अलग-अलग बैकअप विधियों में से चुन सकते हैं, pgdump, pg_basebackup, या pgBackRest। आप यह भी निर्दिष्ट कर सकते हैं कि बैकअप कहाँ संग्रहीत करना है (डेटाबेस सर्वर पर, ClusterControl सर्वर पर, या क्लाउड में), संपीड़न स्तर, एन्क्रिप्शन आवश्यक, और अवधारण अवधि।
PostgreSQL मॉनिटरिंग और अलर्टिंग
कार्रवाई करने में सक्षम होने से पहले आपको यह जानना होगा कि क्या हो रहा है, इसलिए आपको अपने डेटाबेस क्लस्टर की निगरानी करने की आवश्यकता होगी। ClusterControl आपको वास्तविक समय में हमारे सर्वर की निगरानी करने की अनुमति देता है। सीपीयू, नेटवर्क, डिस्क, रैम, आईओपीएस जैसे बुनियादी डेटा के साथ-साथ पोस्टग्रेएसक्यूएल इंस्टेंस से एकत्र किए गए डेटाबेस-विशिष्ट मेट्रिक्स के साथ ग्राफ हैं। डेटाबेस क्वेरीज़ को क्वेरी मॉनिटर से भी देखा जा सकता है।
जिस प्रकार आप ClusterControl से मॉनिटरिंग को सक्षम करते हैं, उसी तरह आप अलर्ट भी सेट कर सकते हैं जो आपको आपके क्लस्टर में होने वाली घटनाओं की सूचना देता है। ये अलर्ट कॉन्फ़िगर करने योग्य हैं, और आवश्यकतानुसार इन्हें वैयक्तिकृत किया जा सकता है।
निष्कर्ष
अंततः सभी को PostgreSQL मुद्दों और विफलताओं का सामना करना पड़ेगा। और चूंकि आप इस समस्या से बच नहीं सकते हैं, इसलिए आपको इसे यथाशीघ्र ठीक करने और सिस्टम को चालू रखने में सक्षम होने की आवश्यकता है। हमने यह भी देखा कि कैसे ClusterControl का उपयोग इन मुद्दों में मदद कर सकता है; सभी एक एकल और उपयोगकर्ता के अनुकूल मंच से।
ये वही हैं जो हमने सोचा था कि PostgreSQL के लिए सबसे आम विफलता परिदृश्यों में से कुछ थे। हमें आपके अपने अनुभवों के बारे में सुनना अच्छा लगेगा और आपने इसे कैसे ठीक किया।