यहाँ हम हैं। 21वीं सदी में लगभग दो दशक और अधिक कंप्यूटिंग शक्ति की आवश्यकता अभी भी एक मुद्दा है। इस बड़ी समस्या से निपटने के लिए प्रौद्योगिकी कंपनियां फुटपाथ को तेज़ कर रही हैं। हार्डवेयर इंजीनियरों ने कंप्यूटर की सेंट्रल प्रोसेसिंग यूनिट (सीपीयू) के डिजाइन और निर्माण के तरीके में बदलाव करके एक समाधान खोजा है। उनमें अब कई कोर होते हैं, जो समवर्ती होने की अनुमति देता है। बदले में, सॉफ़्टवेयर डेवलपर्स ने हार्डवेयर में इस परिवर्तन के अनुकूल होने के लिए प्रोग्राम लिखने के तरीके को समायोजित किया है।
क्वेरी प्रदर्शन को बेहतर बनाने के लिए PostgreSQL समुदाय ने इन मल्टी-कोर CPU का पूरा लाभ उठाया है। केवल 9.6 या उच्चतर संस्करणों में अपडेट करके, आप विभिन्न कार्यों को करने के लिए क्वेरी समानांतरवाद नामक सुविधा का उपयोग कर सकते हैं। यह कार्यों को छोटे भागों में तोड़ता है और प्रत्येक कार्य को कई CPU कोर में फैलाता है। प्रत्येक कोर एक ही समय में कार्यों को संसाधित कर सकता है। हार्डवेयर सीमाओं के कारण, जैसे-जैसे हम भविष्य में आगे बढ़ रहे हैं, कंप्यूटर के प्रदर्शन को बेहतर बनाने का यही एकमात्र तरीका है।
PostgreSQL डेटाबेस में समांतरता सुविधा का उपयोग करने से पहले, यह पहचानना आवश्यक है कि यह क्वेरी को समानांतर कैसे बनाता है। आप किसी भी समस्या को डीबग करने और हल करने में सक्षम होंगे।
क्वेरी समानांतरवाद कैसे काम करता है?
समानांतरवाद को कैसे क्रियान्वित किया जाता है, इसकी बेहतर समझ के लिए, ग्राहक स्तर पर शुरू करना एक अच्छा विचार है। PostgreSQL तक पहुँचने के लिए, क्लाइंट को पोस्टमास्टर नामक डेटाबेस सर्वर को एक कनेक्शन अनुरोध भेजना होगा। पोस्टमास्टर प्रमाणीकरण पूरा करेगा और फिर प्रत्येक कनेक्शन के लिए एक नई सर्वर प्रक्रिया बनाने के लिए फोर्क करेगा। यह साझा मेमोरी का एक क्षेत्र बनाने के लिए भी जिम्मेदार है जिसमें एक बफर पूल होता है। बफर पूल साझा मेमोरी और स्टोरेज के बीच डेटा के हस्तांतरण की देखरेख करता है। इसलिए, जिस क्षण एक कनेक्शन स्थापित हो जाता है, बफर पूल डेटा स्थानांतरित कर देगा और क्वेरी समानांतरता की अनुमति दे सकता है।
सभी प्रश्नों का समानांतर होना आवश्यक नहीं है। ऐसे उदाहरण हैं जहां केवल थोड़ी मात्रा में डेटा की आवश्यकता होती है, और इसे केवल एक कोर द्वारा जल्दी से संसाधित किया जा सकता है। इस सुविधा का उपयोग केवल तभी किया जाता है जब किसी क्वेरी को पूरा होने में पर्याप्त समय लगेगा। डेटाबेस ऑप्टिमाइज़र यह निर्धारित करता है कि क्या समानांतरवाद को निष्पादित किया जाना चाहिए। यदि यह आवश्यक है, तो डेटाबेस मेमोरी के एक अतिरिक्त हिस्से का उपयोग करेगा जिसे डायनेमिक साझा मेमोरी (DSM) कहा जाता है। यह लीडर प्रक्रिया और समानांतर जागरूक कार्यकर्ता प्रक्रियाओं को क्वेरी को कई कोर में विभाजित करने और प्रासंगिक डेटा एकत्र करने की अनुमति देता है।
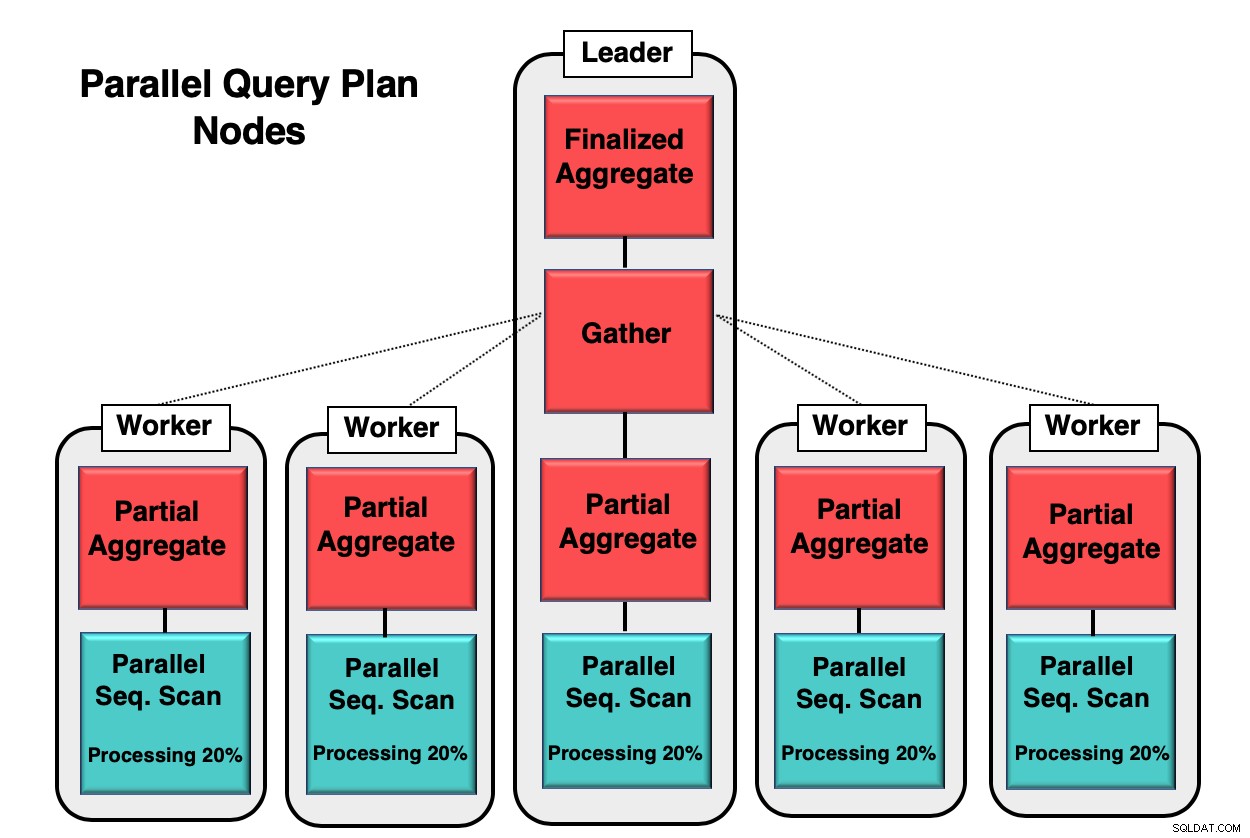
चित्र 1 आपको एक उदाहरण देता है कि डेटाबेस के अंदर समानता कैसे होती है। नेता प्रक्रिया प्रारंभिक क्वेरी चलाती है, जबकि व्यक्तिगत कार्यकर्ता प्रक्रिया उसी प्रक्रिया की एक प्रति शुरू कर रही है। आंशिक समग्र नोड, या सीपीयू कोर, डेटाबेस तालिका के समानांतर अनुक्रमिक स्कैन को लागू करने के लिए जिम्मेदार है।
इस मामले में, प्रत्येक अनुक्रमिक स्कैन नोड 8kb ब्लॉक में 20% डेटा संसाधित कर रहा है। ये समान नोड्स समानांतर जागरूकता नामक तकनीक का उपयोग करके अपनी गतिविधि का समन्वय कर सकते हैं। प्रत्येक नोड को इस बात की पूरी जानकारी है कि कौन सा डेटा पहले ही संसाधित किया जा चुका है, और क्वेरी को पूरा करने के लिए तालिका में किस डेटा को स्कैन करने की आवश्यकता है। एक बार टुपल्स पूरी तरह से एकत्र हो जाने के बाद, इसे संकलित और अंतिम रूप देने के लिए इकट्ठा नोड में भेजा जाता है।
समानांतर संचालन
परिणाम-सेट तैयार करने के लिए डेटाबेस से डेटा प्राप्त करने के लिए विभिन्न प्रकार के प्रश्नों का उपयोग किया जा सकता है। यहां विशिष्ट ऑपरेशन दिए गए हैं जो आपको कई कोर के उपयोग का प्रभावी ढंग से लाभ उठाने की क्षमता प्रदान करते हैं।
अनुक्रमिक स्कैन
यह ऑपरेशन डेटा इकट्ठा करने के लिए शुरुआत से अंत तक एक तालिका में डेटा पढ़ता है। यह समान रूप से क्वेरी प्रोसेसिंग गति को बढ़ाने के लिए कई कोर के बीच कार्यभार वितरित करता है। यह प्रत्येक कोर गतिविधि से अवगत है, जिससे यह निर्धारित करना आसान हो जाता है कि पूरी क्वेरी पूरी हो गई है या नहीं। इकट्ठा नोड तब क्वेरी के आधार पर निकाले गए डेटा को प्राप्त करता है।
एकत्रीकरण
एक मानक ऑपरेशन, जो बड़ी मात्रा में डेटा लेता है और इसे कम संख्या में पंक्तियों में संघनित करता है। यह समानांतर प्रसंस्करण के दौरान केवल एक तालिका या अनुक्रमणिका से निकालने के द्वारा होता है, क्वेरी के आधार पर उपयुक्त जानकारी। विशिष्ट डेटा का औसत प्रदर्शन करना एकत्रीकरण का एक उत्कृष्ट उदाहरण है।
हैश जॉइन
एक तकनीक जिसका उपयोग दो तालिकाओं के बीच डेटा को जोड़ने के लिए किया जाता है। यह सबसे तेज़ जॉइन एल्गोरिथम है, जिसे आम तौर पर एक छोटी तालिका और एक बड़ी तालिका के साथ किया जाता है। आप पहले एक हैश टेबल बनाएं और एक टेबल से सभी डेटा को वहां लोड करें। फिर आप समानांतर अनुक्रमिक स्कैन का उपयोग करके हैश और दूसरी तालिका से सभी डेटा स्कैन कर सकते हैं। स्कैन से निकाले गए प्रत्येक टपल की तुलना हैश तालिका से की जाती है ताकि यह देखा जा सके कि कोई मिलान है या नहीं। यदि एक मैच की पहचान की जाती है, तो डेटा एक साथ जुड़ जाता है। PostgreSQL 11 की रिलीज़ के साथ, हैश जॉइन को पूरा करने के लिए समानांतरवाद का उपयोग करने में इसके पिछले प्रसंस्करण समय का लगभग एक-तिहाई समय लगता है।
मर्ज करें
यदि ऑप्टिमाइज़र यह निर्धारित करता है कि हैश जॉइन मेमोरी क्षमता से अधिक होने वाला है, तो यह इसके बजाय मर्ज जॉइन करेगा। प्रक्रिया में एक ही समय में दो क्रमबद्ध सूचियों के माध्यम से स्कैनिंग शामिल है और एक ही तत्वों को एक साथ जोड़ता है। यदि आइटम समान नहीं हैं, तो डेटा को एक साथ नहीं जोड़ा जाएगा।
नेस्टेड लूप जॉइन
इस ऑपरेशन का उपयोग तब किया जाता है जब आपको विभिन्न प्रोग्रामिंग भाषाओं वाली दो तालिकाओं में शामिल होना पड़ता है, जैसे कि क्विक बेसिक, पायथन, आदि। प्रत्येक तालिका को कई कोर का उपयोग करके स्कैन और संसाधित किया जाता है। यदि डेटा मेल खाता है, तो इसे शामिल होने के लिए एकत्रित नोड में भेजा जाता है। इंडेक्स को भी स्कैन किया जाता है, यही वजह है कि इस प्रक्रिया में डेटा को पुनः प्राप्त करने के लिए कई लूप होते हैं। औसतन, समानांतर प्रक्रिया का उपयोग करके शामिल होने को पूरा करने में केवल एक तिहाई समय लगेगा।
बी-ट्री इंडेक्स स्कैन
यह ऑपरेशन विशिष्ट जानकारी का पता लगाने के लिए सॉर्ट किए गए डेटा के पेड़ के माध्यम से स्कैन करता है। इस प्रक्रिया में सामान्य अनुक्रमिक स्कैन की तुलना में अधिक समय लगता है क्योंकि रिकॉर्ड की तलाश में बहुत अधिक प्रतीक्षा करनी पड़ती है। हालांकि, उपयुक्त डेटा के लिए स्कैनिंग का कार्य कई प्रोसेसर के बीच विभाजित है।
बिटमैप हीप स्कैन
आप इस ऑपरेशन का उपयोग करके कई इंडेक्स को मर्ज कर सकते हैं। आप पहले बिटमैप्स के बराबर संख्या बनाना चाहते हैं, क्योंकि आपके पास इंडेक्स हैं। उदाहरण के लिए, यदि आपके पास तीन इंडेक्स हैं, तो आपको पहले तीन बिटमैप्स बनाने होंगे। प्रत्येक बिटमैप क्वेरी के आधार पर टुपल्स को लाएगा और संकलित करेगा।
आज श्वेतपत्र डाउनलोड करें क्लस्टरकंट्रोल के साथ पोस्टग्रेएसक्यूएल प्रबंधन और स्वचालन इस बारे में जानें कि पोस्टग्रेएसक्यूएल को तैनात करने, मॉनिटर करने, प्रबंधित करने और स्केल करने के लिए आपको क्या जानना चाहिए। श्वेतपत्र डाउनलोड करेंविभाजन समानांतरवाद
समानांतरवाद का एक और रूप है जो PostgreSQL डेटाबेस के भीतर हो सकता है। हालाँकि, यह तालिकाओं को स्कैन करने और कार्यों को तोड़ने से नहीं आता है। आप डेटा को विशिष्ट मानों से विभाजित या विभाजित कर सकते हैं। उदाहरण के लिए, आप मूल्य खरीदारों को ले सकते हैं, और केवल उस मूल्य के भीतर डेटा को एक सिंगल कोर प्रोसेस कर सकते हैं। इस तरह, आप ठीक-ठीक जानते हैं कि प्रत्येक कोर किसी भी समय क्या संसाधित कर रहा है।
हैश विभाजन
इस ऑपरेशन का उपयोग तालिका पंक्तियों को उप-तालिकाओं में फैलाकर किया जाता है। फिर से, आम तौर पर एक तालिका से एक अलग मूल्य या मूल्य सूची द्वारा निर्धारित किया जाता है। यह उपयोग करने का एक उत्कृष्ट तरीका है यदि आपके पास अपने सभी उपकरणों में कुशल भंडारण प्रबंधन तकनीक नहीं है। आप I/O बाधाओं को रोकने के लिए डेटा को बेतरतीब ढंग से वितरित करने के लिए विभाजन का उपयोग करना चाहेंगे।
विभाजन-वार शामिल हों
एक तकनीक का उपयोग विभाजन द्वारा तालिकाओं को तोड़ने और समान विभाजनों को एक साथ जोड़कर उन्हें जोड़ने के लिए किया जाता है। उदाहरण के लिए, आपके पास संयुक्त राज्य भर से खरीदारों की एक बड़ी तालिका हो सकती है। आप पहले अलग-अलग शहरों द्वारा तालिका को तोड़ सकते हैं और फिर प्रत्येक राज्य में क्षेत्र के आधार पर कुछ शहरों को एक साथ जोड़ सकते हैं। विभाजन-वार जुड़ाव आपके डेटा को सरल बनाता है और तालिकाओं में हेरफेर करने की अनुमति देता है।
समानांतर असुरक्षित
PostgreSQL 11 स्वचालित रूप से क्वेरी समांतरता को निष्पादित करता है यदि ऑप्टिमाइज़र यह निर्धारित करता है कि यह क्वेरी को पूरा करने का सबसे तेज़ तरीका है। आपके द्वारा उपयोग किए जा रहे PostgreSQL संस्करण जितना अधिक होगा, आपके डेटाबेस में उतनी ही अधिक समानांतर क्षमता होगी। दुर्भाग्य से, सभी प्रश्नों को समानांतर तरीके से निष्पादित नहीं किया जाना चाहिए, भले ही इसमें क्षमता हो। आप जिस प्रकार की क्वेरी कर रहे हैं उसकी विशिष्ट सीमाएँ हो सकती हैं और इसके लिए आवश्यक होगा कि केवल एक कोर सभी प्रसंस्करण को पूरा करे। यह आपके सिस्टम के प्रदर्शन को धीमा कर देगा, लेकिन यह गारंटी देगा कि प्राप्त डेटा संपूर्ण है।
यह सुनिश्चित करने के लिए कि आपके प्रश्नों को कभी भी जोखिम में नहीं डाला जाए, डेवलपर्स ने समानांतर असुरक्षित नामक एक फ़ंक्शन बनाया है। आप डेटाबेस ऑप्टिमाइज़र को मैन्युअल रूप से ओवरराइड कर सकते हैं और क्वेरी के समानांतर कभी नहीं होने का अनुरोध कर सकते हैं। समानता की प्रक्रिया नहीं की जाएगी।
PostgreSQL डेटाबेस के भीतर समानता एक ऐसी सुविधा है जो केवल प्रत्येक डेटाबेस संस्करण के साथ बेहतर हो रही है। भले ही प्रौद्योगिकी का भविष्य अनिश्चित है, ऐसा लगता है कि इस सुविधा का उपयोग यहां रहने के लिए है।
अधिक जानकारी के लिए, आप निम्न को देख सकते हैं...
- https://www.postgresql.org/docs/10/parallel-query.html
- https://www.postgresql.org/docs/10/how-parallel-query-works.html
- https://www.bbc.com/news/business-42797846
- https://www.technologyreview.com/s/421186/why-cpus-arent-getting-any-faster/
- https://www.percona.com/blog/2019/02/21/parallel-queries-in-postgresql/
- https://malisper.me/postgres-merge-joins/
- https://www.enterprisedb.com/blog/partition-wise-joins-“divid-and-conquer-joins-between-partitioned-table



