यह ब्लॉग जेनकिंस के बारे में एक संक्षिप्त प्रस्तुति है और आपको दिखाता है कि अपने दैनिक पोस्टग्रेएसक्यूएल प्रशासन और प्रबंधन कार्यों में मदद के लिए इस टूल का उपयोग कैसे करें।
जेनकिंस के बारे में
जेनकिंस ऑटोमेशन के लिए एक ओपन सोर्स सॉफ्टवेयर है। यह जावा में विकसित किया गया है और सतत एकीकरण (सीआई) और सतत वितरण (सीडी) के लिए सबसे लोकप्रिय उपकरणों में से एक है।
2010 में, ओरेकल द्वारा सन माइक्रोसिस्टम्स के अधिग्रहण के बाद, "हडसन" सॉफ्टवेयर अपने ओपन सोर्स समुदाय के साथ विवाद में था। यह विवाद जेनकिंस परियोजना के शुभारंभ का आधार बना।
आजकल, "हडसन" (ग्रहण सार्वजनिक लाइसेंस) और "जेनकिंस" (एमआईटी लाइसेंस) एक समान उद्देश्य के साथ दो सक्रिय और स्वतंत्र परियोजनाएं हैं।
जेनकिंस में हजारों प्लगइन्स हैं जिनका उपयोग आप संपूर्ण विकास जीवन-चक्र के लिए स्वचालन के माध्यम से विकास चरण को गति देने के लिए कर सकते हैं; निर्माण, दस्तावेज़, परीक्षण, पैकेज, चरण और परिनियोजन।
जेनकिंस क्या करता है?
हालांकि जेनकिंस का मुख्य उपयोग कंटीन्यूअस इंटीग्रेशन (सीआई) और कंटीन्यूअस डिलीवरी (सीडी) हो सकता है, इस ओपन सोर्स में कार्यात्मकताओं का एक सेट है और इसका उपयोग सीआई या सीडी से किसी भी प्रतिबद्धता या निर्भरता के बिना किया जा सकता है, इस प्रकार जेनकिंस कुछ दिलचस्प कार्यात्मकताओं को प्रस्तुत करता है। एक्सप्लोर करें:
- अवधि की नौकरियों का समय निर्धारण (पारंपरिक crontab . का उपयोग करने के बजाय )
- नौकरियों, उसके लॉग और गतिविधियों पर एक साफ नज़र से निगरानी रखना (क्योंकि उनके पास समूह बनाने का विकल्प है)
- नौकरियों का रखरखाव आसानी से किया जा सकता है; यह मानते हुए कि जेनकिंस के पास इसके लिए विकल्पों का एक सेट है
- एक ही होस्ट में या किसी अन्य में सॉफ़्टवेयर इंस्टॉलेशन (कठपुतली का उपयोग करके) सेटअप और शेड्यूलिंग।
- रिपोर्ट प्रकाशित करना और ईमेल सूचनाएं भेजना
जेनकिंस में PostgreSQL कार्य चलाना
PostgreSQL डेवलपर या डेटाबेस व्यवस्थापक को दैनिक आधार पर तीन सामान्य कार्य करने होते हैं:
- पोस्टग्रेएसक्यूएल स्क्रिप्ट का शेड्यूलिंग और निष्पादन
- तीन या अधिक स्क्रिप्ट से बनी PostgreSQL प्रक्रिया को निष्पादित करना
- पीएल/पीजीएसक्यूएल विकास के लिए सतत एकीकरण (सीआई)
इन उदाहरणों के निष्पादन के लिए, यह माना जाता है कि जेनकिंस और पोस्टग्रेएसक्यूएल (कम से कम संस्करण 9.5) सर्वर स्थापित हैं और ठीक से काम कर रहे हैं।
एक PostgreSQL स्क्रिप्ट का शेड्यूलिंग और निष्पादन
ज्यादातर मामलों में एक सामान्य कार्य के निष्पादन के लिए दैनिक (या समय-समय पर) PostgreSQL स्क्रिप्ट का कार्यान्वयन जैसे...
- बैकअप का निर्माण
- बैकअप की पुनर्स्थापना का परीक्षण करें
- रिपोर्टिंग उद्देश्यों के लिए एक क्वेरी का निष्पादन
- लॉग फ़ाइलें साफ़ करें और संग्रहीत करें
- टेबल को शुद्ध करने के लिए PL/pgSQL प्रक्रिया को कॉल करना
t को crontab . पर परिभाषित किया गया है :
0 5,17 * * * /filesystem/scripts/archive_logs.sh
0 2 * * * /db/scripts/db_backup.sh
0 6 * * * /db/data/scripts/backup_client_tables.sh
0 4 * * * /db/scripts/Test_db_restore.sh
*/10 * * * * /db/scripts/monitor.sh
0 4 * * * /db/data/scripts/queries.sh
0 4 * * * /db/scripts/data_extraction.sh
0 5 * * * /db/scripts/data_import.sh
0 */4 * * * /db/data/scripts/report.shक्रॉस्टैब . के रूप में इस तरह के शेड्यूलिंग को प्रबंधित करने के लिए सबसे अच्छा उपयोगकर्ता के अनुकूल उपकरण नहीं है, इसे जेनकिंस पर निम्नलिखित लाभों के साथ किया जा सकता है...
- उनकी प्रगति और वर्तमान स्थिति की निगरानी के लिए बहुत अनुकूल इंटरफेस
- लॉग तुरंत उपलब्ध हैं और उन्हें एक्सेस करने के लिए किसी विशेष अनुदान की आवश्यकता नहीं है
- कार्य को शेड्यूल करने के बजाय जेनकिंस पर मैन्युअल रूप से निष्पादित किया जा सकता है
- किसी प्रकार की नौकरियों के लिए, उपयोगकर्ताओं और पासवर्ड को सादे पाठ फ़ाइलों में परिभाषित करने की आवश्यकता नहीं है क्योंकि जेनकिंस इसे सुरक्षित तरीके से करते हैं
- कार्यों को API निष्पादन के रूप में परिभाषित किया जा सकता है
इसलिए, पोस्टग्रेएसक्यूएल कार्यों से संबंधित नौकरियों को क्रोंटैब के बजाय जेनकिंस में माइग्रेट करना एक अच्छा समाधान हो सकता है।
दूसरी ओर, अधिकांश डेटाबेस प्रशासकों और डेवलपर्स के पास स्क्रिप्टिंग भाषाओं में मजबूत कौशल है और उनके लिए अपने कार्यों में सुधार के लक्ष्य के साथ स्वचालित प्रक्रियाओं को लागू करने के लिए इन लिपियों से निपटने के लिए छोटे इंटरफेस विकसित करना आसान होगा। लेकिन याद रखें, जेनकिंस के पास इसे करने के लिए पहले से ही कार्यों का एक सेट है और ये कार्यात्मकता उन डेवलपर्स के लिए जीवन को आसान बना सकती है जो उनका उपयोग करना चुनते हैं।
इस प्रकार स्क्रिप्ट के निष्पादन को परिभाषित करने के लिए "नई वस्तु" विकल्प का चयन करते हुए एक नया कार्य बनाना आवश्यक है।
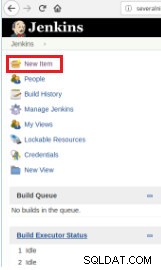 चित्र 1 - "नया आइटम" एक पोस्टग्रेएसक्यूएल स्क्रिप्ट को निष्पादित करने के लिए कार्य को परिभाषित करने के लिए
चित्र 1 - "नया आइटम" एक पोस्टग्रेएसक्यूएल स्क्रिप्ट को निष्पादित करने के लिए कार्य को परिभाषित करने के लिए फिर, इसे नाम देने के बाद, "फ्री स्टाइल प्रोजेक्ट्स" टाइप करें और ओके पर क्लिक करें।
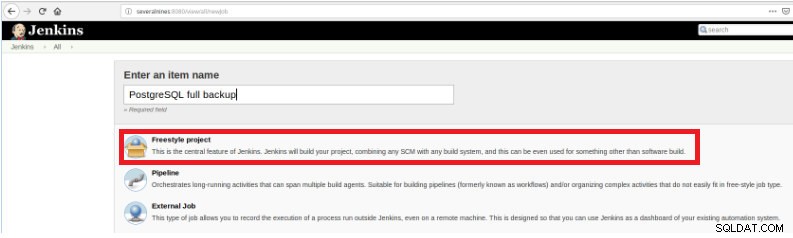 चित्र 2 - नौकरी (आइटम) प्रकार का चयन
चित्र 2 - नौकरी (आइटम) प्रकार का चयन इस नई नौकरी के निर्माण को समाप्त करने के लिए, "बिल्ड" अनुभाग में "एक्ज़ीक्यूट स्क्रिप्ट" विकल्प का चयन किया जाना चाहिए और कमांड लाइन बॉक्स में स्क्रिप्ट का पथ और पैरामीटराइजेशन जिसे निष्पादित किया जाएगा:
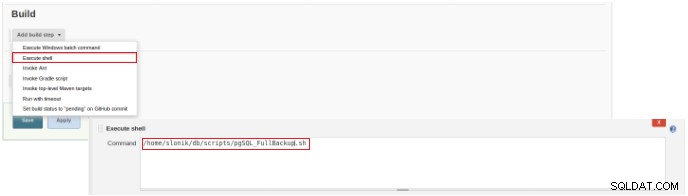 चित्र 3 - निष्पादित करने के लिए कमांड की विशिष्टता
चित्र 3 - निष्पादित करने के लिए कमांड की विशिष्टता इस तरह के काम के लिए, स्क्रिप्ट अनुमतियों को सत्यापित करने की सलाह दी जाती है, क्योंकि कम से कम उस समूह के लिए निष्पादन जो फ़ाइल से संबंधित है और सभी के लिए सेट होना चाहिए।
इस उदाहरण में, स्क्रिप्ट query.sh सभी के लिए अनुमतियाँ पढ़ें और निष्पादित करें, समूह के लिए अनुमतियाँ पढ़ें और निष्पादित करें और उपयोगकर्ता के लिए पढ़ें और लिखें और निष्पादित करें:
example@sqldat.com:~/db/scripts$ ls -l query.sh
-rwxr-xr-x 1 slonik slonik 365 May 11 20:01 query.sh
example@sqldat.com:~/db/scripts$ इस स्क्रिप्ट में बयानों का एक बहुत ही सरल सेट है, मूल रूप से केवल क्वेरी को निष्पादित करने के लिए उपयोगिता psql को कॉल करता है:
#!/bin/bash
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl" > /home/slonik/db/scripts/appl.dat
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl_users" > /home/slonik/db/scripts/appl_user.dat
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl_rights" > /home/slonik/db/scripts/appl_rights.datतीन या अधिक लिपियों से बनी PostgreSQL प्रक्रिया का निष्पादन
इस उदाहरण में, मैं वर्णन करूंगा कि संवेदनशील डेटा को छिपाने के लिए आपको तीन अलग-अलग लिपियों को निष्पादित करने की क्या आवश्यकता है और उसके लिए, हम नीचे दिए गए चरणों का पालन करेंगे...
- फ़ाइलों से डेटा आयात करें
- मास्क करने के लिए डेटा तैयार करें
- डेटाबेस का बैकअप नकाबपोश के साथ
इसलिए, इस नई नौकरी को परिभाषित करने के लिए जेनकिंस मुख्य पृष्ठ में "नई वस्तु" विकल्प का चयन करना आवश्यक है और फिर, एक नाम निर्दिष्ट करने के बाद, "पाइपलाइन" विकल्प चुना जाना चाहिए:
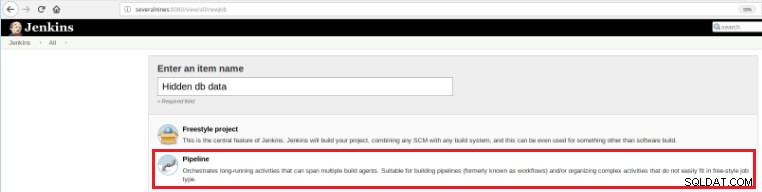 चित्र 5 - जेनकिंस में पाइपलाइन आइटम
चित्र 5 - जेनकिंस में पाइपलाइन आइटम "पाइपलाइन" अनुभाग में कार्य सहेजे जाने के बाद, "उन्नत परियोजना विकल्प" टैब पर, "परिभाषा" फ़ील्ड को "पाइपलाइन स्क्रिप्ट" पर सेट किया जाना चाहिए, जैसा कि नीचे दिखाया गया है:
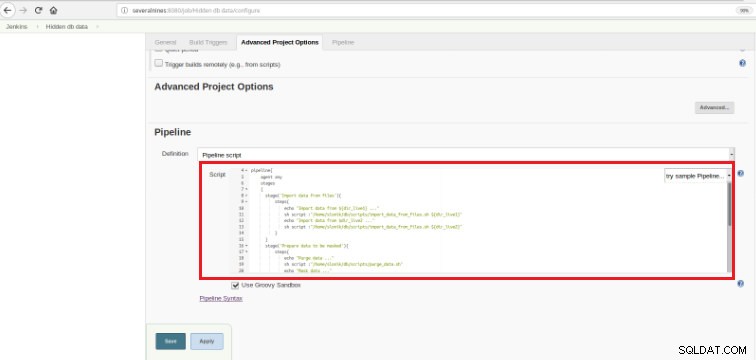 चित्र 6 - पाइपलाइन अनुभाग में ग्रूवी स्क्रिप्ट
चित्र 6 - पाइपलाइन अनुभाग में ग्रूवी स्क्रिप्ट जैसा कि मैंने अध्याय की शुरुआत में उल्लेख किया है, इस्तेमाल की गई ग्रोवी लिपि तीन चरणों से बना है, इसका मतलब तीन अलग-अलग हिस्सों (चरणों) है, जैसा कि निम्नलिखित लिपि में प्रस्तुत किया गया है:
def dir_live1='/data/ftp/server1'
def dir_live2='/data/ftp/server2'
pipeline{
agent any
stages
{
stage('Import data from files'){
steps{
echo "Import data from ${dir_live1} ..."
sh script :"/home/slonik/db/scripts/import_data_from_files.sh ${dir_live1}"
echo "Import data from $dir_live2 ..."
sh script :"/home/slonik/db/scripts/import_data_from_files.sh ${dir_live2}"
}
}
stage('Prepare data to be masked'){
steps{
echo "Purge data ..."
sh script :"/home/slonik/db/scripts/purge_data.sh"
echo "Mask data ..."
sh script :"/home/slonik/db/scripts/mask_data.sh"
}
}
stage('Backup of database with data masked'){
steps{
echo "Backup database after masking ..."
sh script :"/home/slonik/db/scripts/backup_db.sh"
}
}
}
}ग्रूवी जावा प्लेटफॉर्म के लिए जावा-सिंटैक्स-संगत ऑब्जेक्ट ओरिएंटेड प्रोग्रामिंग भाषा है। यह पाइथन, रूबी, पर्ल और स्मॉलटाक जैसी सुविधाओं के साथ एक स्थिर और गतिशील भाषा है।
इसे समझना आसान है क्योंकि इस तरह की स्क्रिप्ट कुछ कथनों पर आधारित होती है…
चरण
यानी 3 प्रक्रियाएं जिन्हें निष्पादित किया जाएगा:"फ़ाइलों से डेटा आयात करें", "मास्क किए जाने के लिए डेटा तैयार करें"
और "डेटाबेस का बैकअप डेटा मास्क के साथ"।
चरण
एक "स्टेप" (जिसे अक्सर "बिल्ड स्टेप" कहा जाता है) एक एकल कार्य है जो एक अनुक्रम का हिस्सा होता है। प्रत्येक चरण कई चरणों से बना हो सकता है। इस उदाहरण में, पहले चरण में दो चरण होते हैं।
sh script :"/home/slonik/db/scripts/import_data_from_files.sh '/data/ftp/server1'
sh script :"/home/slonik/db/scripts/import_data_from_files.sh '/data/ftp/server2'डेटा दो अलग-अलग स्रोतों से आयात किया जा रहा है।
पिछले उदाहरण में, यह ध्यान रखना महत्वपूर्ण है कि शुरुआत में और वैश्विक दायरे के साथ परिभाषित दो चर हैं:
dir_live1
dir_live2इन तीन चरणों में प्रयुक्त स्क्रिप्ट psql . को कॉल कर रही हैं , pg_restore और pg_dump उपयोगिताओं।
एक बार नौकरी परिभाषित हो जाने के बाद, इसे निष्पादित करने का समय आ गया है और उसके लिए, केवल "अभी बनाएं" विकल्प पर क्लिक करना आवश्यक है:
 चित्र 7 - निष्पादन कार्य
चित्र 7 - निष्पादन कार्य निर्माण शुरू होने के बाद इसकी प्रगति को सत्यापित करना संभव है।
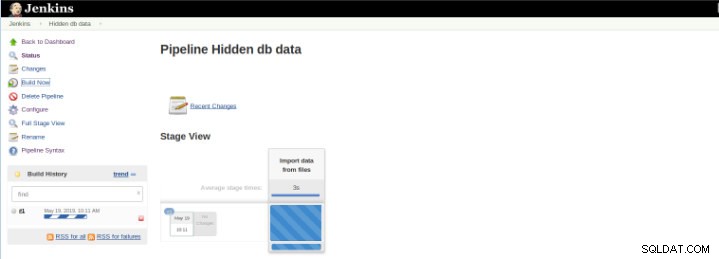 चित्र 8 - "बिल्ड" शुरू करना
चित्र 8 - "बिल्ड" शुरू करना पाइपलाइन स्टेज व्यू प्लगइन में स्टेज व्यू के तहत फ्लो प्रोजेक्ट के इंडेक्स पेज पर पाइपलाइन बिल्ड हिस्ट्री का विस्तारित विज़ुअलाइज़ेशन शामिल है। जैसे ही कार्य पूर्ण होते हैं, यह दृश्य बनाया जाता है और प्रत्येक कार्य को बाएं से दाएं कॉलम द्वारा दर्शाया जाता है और सर्वल निष्पादन के लिए बीता हुआ समय देखना और तुलना करना संभव है (जिसे जेनकिंस में बिल्ड के रूप में जाना जाता है)।
एक बार निष्पादन (जिसे बिल्ड भी कहा जाता है) समाप्त हो जाने के बाद, तैयार थ्रेड (लाल बॉक्स) पर क्लिक करके अतिरिक्त विवरण प्राप्त करना संभव है।
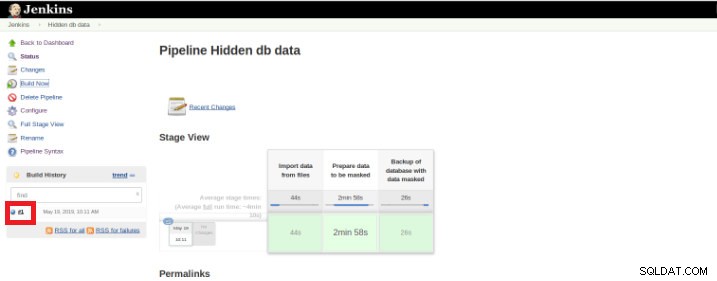 चित्र 9 - "बिल्ड" शुरू करना
चित्र 9 - "बिल्ड" शुरू करना और फिर "कंसोल आउटपुट" विकल्प में।
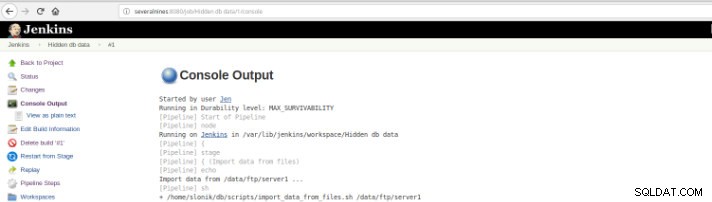 चित्र 10 - कंसोल आउटपुट
चित्र 10 - कंसोल आउटपुट पिछले दृश्य अत्यधिक उपयोगी हैं क्योंकि वे प्रत्येक चरण के लिए आवश्यक रनटाइम की धारणा रखने की अनुमति देते हैं।
पाइपलाइन, जिसे वर्कफ़्लो के रूप में भी जाना जाता है, यह एक प्लगइन है जो एप्लिकेशन जीवनचक्र की परिभाषा की अनुमति देता है और यह निरंतर वितरण (सीडी) के लिए जेनकिंस में उपयोग की जाने वाली कार्यक्षमता है। vयह प्लगइन एक लचीली, एक्स्टेंसिबल और स्क्रिप्ट-आधारित सीडी वर्कफ़्लो क्षमता के लिए आवश्यकताओं के साथ बनाया गया था। मन में।
यह उदाहरण संवेदनशील डेटा को छिपाने के लिए है, लेकिन निश्चित रूप से PostgreSQL डेटाबेस व्यवस्थापक के दैनिक आधार पर कई अन्य उदाहरण हैं जिन्हें पाइपलाइन कार्य पर निष्पादित किया जा सकता है।
पाइपलाइन संस्करण 2.0 से जेनकिंस पर उपलब्ध है और यह एक अविश्वसनीय समाधान है!

PL/pgSQL विकास के लिए सतत एकीकरण (CI)
डेटाबेस विकास के लिए निरंतर एकीकरण अन्य प्रोग्रामिंग भाषाओं की तरह आसान नहीं है क्योंकि डेटा खो सकता है, इसलिए डेटाबेस को स्रोत नियंत्रण में रखना और इसे एक समर्पित सर्वर पर तैनात करना आसान नहीं है, विशेष रूप से एक बार स्क्रिप्ट होने पर जिसमें डीडीएल (डेटा डेफिनिशन लैंग्वेज) और डीएमएल (डेटा मैनिपुलेशन लैंग्वेज) स्टेटमेंट शामिल हैं। ऐसा इसलिए है क्योंकि इस प्रकार के बयान डेटाबेस की वर्तमान स्थिति को संशोधित करते हैं और अन्य प्रोग्रामिंग भाषाओं के विपरीत संकलित करने के लिए कोई स्रोत कोड नहीं है।
दूसरी ओर, डेटाबेस स्टेटमेंट का एक सेट है जिसके लिए अन्य प्रोग्रामिंग भाषाओं की तरह निरंतर एकीकरण संभव है।
यह उदाहरण यह केवल प्रक्रियाओं के विकास पर आधारित है और यह जेनकिंस द्वारा परीक्षणों के एक सेट (पायथन में लिखे गए) के ट्रिगरिंग का वर्णन करेगा, जब पोस्टग्रेएसक्यूएल स्क्रिप्ट, जिस पर निम्नलिखित कार्यों के कोड संग्रहीत होते हैं, एक कोड रिपॉजिटरी में प्रतिबद्ध होते हैं।
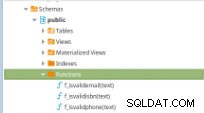 चित्र 11 - PLpg/SQL फ़ंक्शन
चित्र 11 - PLpg/SQL फ़ंक्शन ये फ़ंक्शन सरल हैं और इसकी सामग्री में PLpg/SQL . में केवल कुछ तर्क या क्वेरी हैं या प्लपरलू फ़ंक्शन के रूप में भाषा f_IsValidEmail :
CREATE OR REPLACE FUNCTION f_IsValidEmail(email text) RETURNS bool
LANGUAGE plperlu
AS $$
use Email::Address;
my @addresses = Email::Address->parse($_[0]);
return scalar(@addresses) > 0 ? 1 : 0;
$$;यहां प्रस्तुत सभी कार्य एक-दूसरे पर निर्भर नहीं हैं, और फिर न तो इसके विकास में और न ही इसके परिनियोजन में कोई पूर्वता है। साथ ही, जैसा कि आगे सत्यापित किया जाएगा, उनके सत्यापन पर कोई निर्भरता नहीं है।
इसलिए, सत्यापन स्क्रिप्ट के एक सेट को एक बार कोड रिपॉजिटरी में किए जाने के बाद निष्पादित करने के लिए जेनकिंस में एक बिल्ड जॉब (नया आइटम) का निर्माण आवश्यक है:
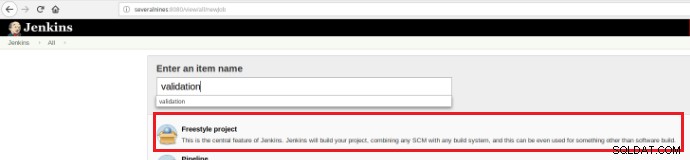 चित्र 12 - सतत एकीकरण के लिए "फ्रीस्टाइल" परियोजना
चित्र 12 - सतत एकीकरण के लिए "फ्रीस्टाइल" परियोजना यह नया बिल्ड जॉब "फ्रीस्टाइल" प्रोजेक्ट के रूप में बनाया जाना चाहिए और "सोर्स कोड रिपोजिटरी" सेक्शन में रिपोजिटरी यूआरएल और उसके क्रेडेंशियल्स (नारंगी बॉक्स) को परिभाषित किया जाना चाहिए:
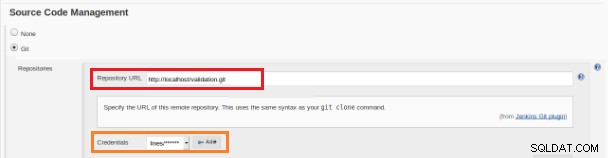 चित्र 13 - स्रोत कोड भंडार
चित्र 13 - स्रोत कोड भंडार "बिल्ड ट्रिगर" अनुभाग में "GITScm मतदान के लिए GitHub हुक ट्रिगर" विकल्प की जाँच की जानी चाहिए:
 चित्र 14 - "ट्रिगर बनाएं" अनुभाग
चित्र 14 - "ट्रिगर बनाएं" अनुभाग अंत में, "बिल्ड" अनुभाग में, "एक्ज़ीक्यूट शेल" विकल्प का चयन किया जाना चाहिए और कमांड बॉक्स में स्क्रिप्ट जो विकसित कार्यों का सत्यापन करेगी:
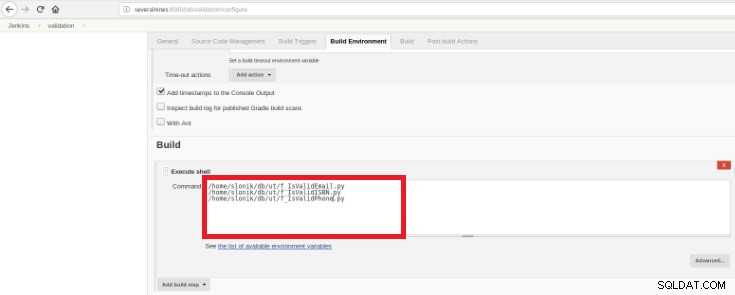 चित्र 15 - "पर्यावरण बनाएं" अनुभाग
चित्र 15 - "पर्यावरण बनाएं" अनुभाग इसका उद्देश्य प्रत्येक विकसित फ़ंक्शन के लिए एक सत्यापन स्क्रिप्ट रखना है।
इस पायथन लिपि में बयानों का एक सरल सेट है जो इन प्रक्रियाओं को कुछ पूर्वनिर्धारित अपेक्षित परिणामों के साथ डेटाबेस से कॉल करेगा:
#!/usr/bin/python
import psycopg2
con = psycopg2.connect(database="db_deploy", user="postgres", password="postgres10", host="localhost", port="5432")
cur = con.cursor()
email_list = { 'example@sqldat.com' : True,
'tintinmail.com' : False,
'example@sqldat.com' : False,
'director#mail.com': False,
'example@sqldat.com' : True
}
result_msg= "f_IsValidEmail -> OK"
for key in email_list:
cur.callproc('f_IsValidEmail', (key,))
row = cur.fetchone()
if email_list[key]!=row[0]:
result_msg= "f_IsValidEmail -> Nok"
print result_msg
cur.close()
con.close()यह स्क्रिप्ट प्रस्तुत PLpg/SQL का परीक्षण करेगी या प्लपरलू कार्यों और विकास पर प्रतिगमन से बचने के लिए कोड रिपॉजिटरी में प्रत्येक प्रतिबद्धता के बाद इसे निष्पादित किया जाएगा।
एक बार जब यह जॉब बिल्ड निष्पादित हो जाता है, तो लॉग निष्पादन सत्यापित किया जा सकता है।
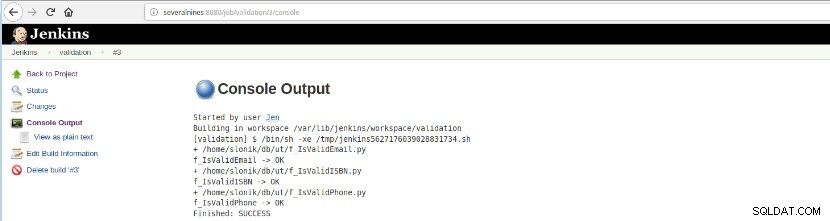 चित्र 16 - "कंसोल आउटपुट"
चित्र 16 - "कंसोल आउटपुट" यह विकल्प अंतिम स्थिति प्रस्तुत करता है:सफलता या विफलता, कार्यक्षेत्र, निष्पादित फ़ाइलें/स्क्रिप्ट, बनाई गई अस्थायी फ़ाइलें और त्रुटि संदेश (विफल लोगों के लिए)!
निष्कर्ष
संक्षेप में, जेनकिंस को कंटीन्यूअस इंटीग्रेशन (CI) और कंटीन्यूअस डिलीवरी (CD) के लिए एक बेहतरीन टूल के रूप में जाना जाता है, हालाँकि, इसका उपयोग विभिन्न कार्यात्मकताओं जैसे,
के लिए किया जा सकता है।- कार्य शेड्यूल करना
- स्क्रिप्ट का निष्पादन
- निगरानी प्रक्रियाओं
इन सभी उद्देश्यों के लिए प्रत्येक निष्पादन (जेनकींस शब्दावली पर निर्माण) पर लॉग और बीता हुआ समय का विश्लेषण किया जा सकता है।
बड़ी संख्या में उपलब्ध प्लगइन्स के कारण यह एक विशिष्ट उद्देश्य के साथ कुछ विकास से बच सकता है, शायद एक प्लगइन है जो ठीक वही करता है जो आप खोज रहे हैं, यह केवल अपडेट सेंटर खोजने या जेनकींस प्रबंधित करने का मामला है>> प्लगइन्स को अंदर प्रबंधित करें वेब एप्लिकेशन।



