PostgreSQL इंस्टॉलेशन के प्रबंधन में सॉफ़्टवेयर/इन्फ्रास्ट्रक्चर स्टैक में पहलुओं की एक विस्तृत श्रृंखला पर निरीक्षण और नियंत्रण शामिल है, जिस पर PostgreSQL चलता है। इसमें शामिल होना चाहिए:
- डेटाबेस उपयोग/लेनदेन/कनेक्शन के संबंध में एप्लिकेशन ट्यूनिंग
- डेटाबेस कोड (प्रश्न, कार्य)
- डेटाबेस सिस्टम (प्रदर्शन, HA, बैकअप)
- हार्डवेयर/इन्फ्रास्ट्रक्चर (डिस्क, सीपीयू/मेमोरी)
PostgreSQL कोर डेटाबेस परत प्रदान करता है जिस पर हम अपने डेटा को संग्रहीत, संसाधित और परोसने के लिए भरोसा करते हैं। यह वास्तव में आधुनिक, कुशल, विश्वसनीय और सुरक्षित प्रणाली रखने के लिए सभी तकनीक भी प्रदान करता है। लेकिन अक्सर यह तकनीक कोर पोस्टग्रेएसक्यूएल वितरण में उपयोग के लिए तैयार, परिष्कृत व्यवसाय/उद्यम श्रेणी के उत्पाद के रूप में उपलब्ध नहीं होती है। इसके बजाय, PostgreSQL समुदाय या वाणिज्यिक पेशकशों द्वारा बहुत सारे उत्पाद/समाधान हैं जो उन जरूरतों को पूरा करते हैं। वे समाधान या तो मूल प्रौद्योगिकियों के लिए उपयोगकर्ता के अनुकूल परिशोधन के रूप में आते हैं, या मुख्य प्रौद्योगिकियों के विस्तार या यहां तक कि पोस्टग्रेएसक्यूएल घटकों और सिस्टम के अन्य घटकों के बीच एकीकरण के रूप में भी आते हैं। पोस्टग्रेएसक्यूएल के साथ प्रोडक्शन में जाने के लिए टेन टिप्स शीर्षक वाले हमारे पिछले ब्लॉग में, हमने कुछ ऐसे टूल्स पर ध्यान दिया, जो प्रोडक्शन में पोस्टग्रेएसक्यूएल इंस्टॉलेशन को मैनेज करने में मदद कर सकते हैं। इस ब्लॉग में हम उन पहलुओं का अधिक विस्तार से पता लगाएंगे जिन्हें उत्पादन में PostgreSQL स्थापना का प्रबंधन करते समय कवर किया जाना चाहिए, और उस उद्देश्य के लिए सबसे अधिक उपयोग किए जाने वाले टूल। हम निम्नलिखित विषयों को कवर करेंगे:
- तैनाती
- प्रबंधन
- स्केलिंग
- निगरानी
तैनाती
पुराने दिनों में, लोग पोस्टग्रेएसक्यूएल को हाथ से डाउनलोड और संकलित करते थे, और फिर रनटाइम पैरामीटर और उपयोगकर्ता एक्सेस कंट्रोल को कॉन्फ़िगर करते थे। अभी भी कुछ मामले हैं जहां इसकी आवश्यकता हो सकती है लेकिन जैसे-जैसे सिस्टम परिपक्व होते गए और बढ़ने लगे, पोस्टग्रेस्क्ल को तैनात और प्रबंधित करने के लिए अधिक मानकीकृत तरीकों की आवश्यकता पैदा हुई। अधिकांश OS PostgreSQL क्लस्टर को स्थापित करने, तैनात करने और प्रबंधित करने के लिए पैकेज प्रदान करते हैं। डेबियन ने अपने स्वयं के सिस्टम लेआउट को मानकीकृत किया है जो कई पोस्टग्रेस्क्ल संस्करणों का समर्थन करता है, और एक ही समय में प्रति संस्करण कई क्लस्टर। postgresql-common debian पैकेज आवश्यक उपकरण प्रदान करता है। उदाहरण के लिए डेबियन में PostgreSQL संस्करण 10 के लिए एक नया क्लस्टर (i18n_cluster कहा जाता है) बनाने के लिए, हम इसे निम्नलिखित कमांड देकर कर सकते हैं:
$ pg_createcluster 10 i18n_cluster -- --encoding=UTF-8 --data-checksumsफिर सिस्टमड रीफ़्रेश करें:
$ sudo systemctl daemon-reloadऔर अंत में नया क्लस्टर शुरू करें और उसका उपयोग करें:
$ sudo systemctl start example@sqldat.com_cluster.service
$ createdb -p 5434 somei18ndb(ध्यान दें कि डेबियन 5432, 5433 और इसी तरह के विभिन्न बंदरगाहों के उपयोग से विभिन्न समूहों को संभालता है)
जैसे-जैसे अधिक स्वचालित और बड़े पैमाने पर तैनाती की आवश्यकता बढ़ती है, अधिक से अधिक इंस्टॉलेशन ऑटोमेशन टूल जैसे Ansible, Chef और Puppet का उपयोग करते हैं। तैनाती के स्वचालन और पुनरुत्पादन के अलावा, स्वचालन उपकरण बहुत अच्छे हैं क्योंकि वे क्लस्टर की तैनाती और कॉन्फ़िगरेशन को दस्तावेज करने का एक अच्छा तरीका हैं। दूसरी ओर, स्वचालन अपने आप में एक बड़ा क्षेत्र बनने के लिए विकसित हुआ है, जिसके लिए कुशल लोगों को स्वचालित स्क्रिप्ट लिखने, प्रबंधित करने और चलाने की आवश्यकता होती है। PostgreSQL प्रोविज़निंग के बारे में अधिक जानकारी इस ब्लॉग में मिल सकती है:PostgreSQL DBA बनें:प्रोविजनिंग और परिनियोजन।
प्रबंधन
लाइव सिस्टम के प्रबंधन में इस प्रकार के कार्य शामिल हैं:बैकअप शेड्यूल करें और उनकी स्थिति, आपदा पुनर्प्राप्ति, कॉन्फ़िगरेशन प्रबंधन, उच्च उपलब्धता प्रबंधन और स्वचालित विफलता प्रबंधन की निगरानी करें। Postgresql क्लस्टर का बैकअप विभिन्न तरीकों से किया जा सकता है। निम्न स्तर के उपकरण:
- पारंपरिक pg_dump (तार्किक बैकअप)
- फ़ाइल सिस्टम स्तर बैकअप (भौतिक बैकअप)
- pg_basebackup (भौतिक बैकअप)
या उच्च स्तर:
- बर्मन
- पीजीबैकरेस्ट
उनमें से प्रत्येक तरीके अलग-अलग उपयोग के मामलों और पुनर्प्राप्ति परिदृश्यों को कवर करते हैं, और जटिलता में भिन्न होते हैं। पोस्टग्रेएसक्यूएल बैकअप पीआईटीआर, वाल संग्रह और प्रतिकृति की धारणाओं से कसकर संबंधित है। वर्षों से PostgreSQL के साथ बैकअप लेने, परीक्षण करने और अंत में (उंगलियों को पार करने!) की प्रक्रिया एक जटिल कार्य के रूप में विकसित हुई है। इस ब्लॉग में पोस्टग्रेएसक्यूएल के लिए बैकअप समाधानों का एक अच्छा अवलोकन मिल सकता है:पोस्टग्रेएसक्यूएल के लिए शीर्ष बैकअप उपकरण।
उच्च उपलब्धता और स्वचालित विफलता के संबंध में इसे लागू करने के लिए एक इंस्टॉलेशन के पास न्यूनतम न्यूनतम होना चाहिए:
- कार्यरत प्राथमिक
- वाल को स्वीकार करने वाला एक हॉट स्टैंडबाय प्राथमिक से स्ट्रीम किया गया
- असफल प्राथमिक की स्थिति में, प्राथमिक को यह बताने का एक तरीका कि यह अब प्राथमिक नहीं है (कभी-कभी STONITH कहा जाता है)
- दो सर्वरों के बीच कनेक्टिविटी और प्राथमिक के स्वास्थ्य की जांच करने के लिए एक दिल की धड़कन तंत्र
- विफल होने का एक तरीका (उदाहरण के लिए pg_ctl प्रचार, या ट्रिगर फ़ाइल के माध्यम से)
- नए स्टैंडबाय के रूप में पुराने प्राइमरी के मनोरंजन के लिए एक स्वचालित प्रक्रिया:एक बार प्राइमरी में व्यवधान या विफलता का पता चलने पर एक स्टैंडबाय को नए प्राइमरी के रूप में प्रचारित किया जाना चाहिए। पुराना प्राथमिक अब मान्य या प्रयोग करने योग्य नहीं है। तो सिस्टम के पास इस स्थिति को फेलओवर और पुराने प्राथमिक सर्वर के नए स्टैंडबाय के रूप में पुन:निर्माण के बीच संभालने का एक तरीका होना चाहिए। इस स्थिति को डीजेनरेट स्टेट कहा जाता है, और PostgreSQL पुराने प्राइमरी को नए प्राइमरी से सिंक-सक्षम स्थिति में वापस लाने की प्रक्रिया को तेज करने के लिए pg_rewind नामक एक टूल प्रदान करता है।
- ऑन-डिमांड/नियोजित स्विचओवर करने का एक तरीका
उपरोक्त सभी को संभालने वाला एक व्यापक रूप से उपयोग किया जाने वाला टूल रेपमग्र है। हम उस न्यूनतम सेटअप का वर्णन करेंगे जो एक सफल स्विचओवर की अनुमति देगा। हम फ्रीबीएसडी 11.1 पर चलने वाले एक वर्किंग पोस्टग्रेएसक्यूएल 10.4 प्राथमिक से शुरू करते हैं, मैन्युअल रूप से निर्मित और स्थापित, और इस संस्करण (10.4) के लिए मैन्युअल रूप से निर्मित और स्थापित repmgr 4.0 भी। हम PostgreSQL और repmgr के समान संस्करणों के साथ fbsd (192.168.1.80) और fbsdclone (192.168.1.81) नामक दो होस्ट का उपयोग करेंगे। प्राथमिक पर (शुरू में fbsd , 192.168.1.80) हम सुनिश्चित करते हैं कि निम्नलिखित PostgreSQL पैरामीटर सेट हैं:
max_wal_senders = 10
wal_level = 'logical'
hot_standby = on
archive_mode = 'on'
archive_command = '/usr/bin/true'
wal_keep_segments = '1000' फिर हम repmgr उपयोगकर्ता (सुपरयूज़र के रूप में) और डेटाबेस बनाते हैं:
example@sqldat.com:~ % createuser -s repmgr
example@sqldat.com:~ % createdb repmgr -O repmgrऔर निम्न पंक्तियों को शीर्ष पर रखकर pg_hba.conf में होस्ट आधारित अभिगम नियंत्रण स्थापित करें:
local replication repmgr trust
host replication repmgr 127.0.0.1/32 trust
host replication repmgr 192.168.1.0/24 trust
local repmgr repmgr trust
host repmgr repmgr 127.0.0.1/32 trust
host repmgr repmgr 192.168.1.0/24 trustहम सुनिश्चित करते हैं कि हम क्लस्टर के सभी नोड्स में उपयोगकर्ता repmgr के लिए पासवर्ड रहित लॉगिन सेटअप करते हैं, हमारे मामले में fbsd और fbsdclone में .ssh में अधिकृत_की सेट करके और फिर .ssh साझा करके। फिर हम प्राथमिक पर repmrg.conf बनाते हैं:
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=1
node_name=fbsd
conninfo='host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'फिर हम प्राथमिक पंजीकृत करते हैं:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf primary register
NOTICE: attempting to install extension "repmgr"
NOTICE: "repmgr" extension successfully installed
NOTICE: primary node record (id: 1) registeredऔर क्लस्टर की स्थिति जांचें:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2अब हम निम्नानुसार repmgr.conf सेट करके स्टैंडबाय पर काम करते हैं:
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=2
node_name=fbsdclone
conninfo='host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'हम यह भी सुनिश्चित करते हैं कि ऊपर की पंक्ति में निर्दिष्ट डेटा निर्देशिका मौजूद है, खाली है और सही अनुमतियां हैं:
example@sqldat.com:~ % rm -fr data && mkdir data
example@sqldat.com:~ % chmod 700 dataअब हमें अपने नए स्टैंडबाय का क्लोन बनाना होगा:
example@sqldat.com:~ % repmgr -h 192.168.1.80 -U repmgr -f /etc/repmgr.conf --force standby clone
NOTICE: destination directory "/usr/local/var/lib/pgsql/data" provided
NOTICE: starting backup (using pg_basebackup)...
HINT: this may take some time; consider using the -c/--fast-checkpoint option
NOTICE: standby clone (using pg_basebackup) complete
NOTICE: you can now start your PostgreSQL server
HINT: for example: pg_ctl -D /usr/local/var/lib/pgsql/data start
HINT: after starting the server, you need to register this standby with "repmgr standby register"और स्टैंडबाय शुरू करें:
example@sqldat.com:~ % pg_ctl -D data startइस बिंदु पर प्रतिकृति अपेक्षित रूप से काम कर रही होनी चाहिए, pg_stat_replication (fbsd) और pg_stat_wal_receiver (fbsdclone) को क्वेरी करके इसे सत्यापित करें। स्टैंडबाय रजिस्टर करने के लिए अगला कदम है:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby registerअब हम स्टैंडबाय या प्राइमरी पर क्लस्टर की स्थिति प्राप्त कर सकते हैं और सत्यापित कर सकते हैं कि स्टैंडबाय पंजीकृत है:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | standby | running | fbsd | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2अब मान लेते हैं कि हम एक शेड्यूल किए गए मैन्युअल स्विचओवर को क्रम में करना चाहते हैं उदा। नोड fbsd पर कुछ प्रशासन कार्य करने के लिए। स्टैंडबाय नोड पर, हम निम्नलिखित कमांड चलाते हैं:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby switchover
…
NOTICE: STANDBY SWITCHOVER has completed successfullyस्विचओवर सफलतापूर्वक निष्पादित किया गया है! आइए देखें कि क्लस्टर शो क्या देता है:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+-----------+----------+---------------------------------------------------------------
1 | fbsd | standby | running | fbsdclone | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | primary | * running | | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2दो सर्वरों ने भूमिकाओं की अदला-बदली की है! Repmgr repmgrd डेमॉन प्रदान करता है जो निगरानी, स्वचालित विफलता, साथ ही सूचनाएं/अलर्ट प्रदान करता है। pgbouncer के साथ repmgrd का संयोजन, डेटाबेस की कनेक्शन जानकारी के स्वचालित अद्यतन को कार्यान्वित करना संभव है, इस प्रकार विफल प्राथमिक के लिए बाड़ लगाना (एप्लिकेशन द्वारा किसी भी उपयोग से विफल नोड को रोकना) साथ ही साथ एप्लिकेशन के लिए न्यूनतम डाउनटाइम प्रदान करना। अधिक जटिल योजनाओं में एक अन्य विचार यह है कि प्राप्त करने के लिए Keepalived को HAProxy के साथ pgbouncer और repmgr के शीर्ष पर संयोजित किया जाए:
- लोड संतुलन (स्केलिंग)
- उच्च उपलब्धता
ध्यान दें कि ClusterControl भी PostgreSQL प्रतिकृति सेटअप की विफलता का प्रबंधन करता है, और HAProxy और VirtualIP को स्वचालित रूप से कार्य करने वाले मास्टर के लिए क्लाइंट कनेक्शन को फिर से रूट करने के लिए एकीकृत करता है। पोस्टग्रेएसक्यूएल ऑटोमेशन पर इस श्वेतपत्र में अधिक जानकारी मिल सकती है।
आज श्वेतपत्र डाउनलोड करें क्लस्टरकंट्रोल के साथ पोस्टग्रेएसक्यूएल प्रबंधन और स्वचालन इस बारे में जानें कि पोस्टग्रेएसक्यूएल को तैनात करने, मॉनिटर करने, प्रबंधित करने और स्केल करने के लिए आपको क्या जानना चाहिए। श्वेतपत्र डाउनलोड करेंस्केलिंग
PostgreSQL 10 (और 11) के रूप में अभी भी मल्टी-मास्टर प्रतिकृति होने का कोई तरीका नहीं है, कम से कम कोर पोस्टग्रेएसक्यूएल से नहीं। इसका मतलब है कि केवल चुनिंदा (केवल पढ़ने के लिए) गतिविधि को बढ़ाया जा सकता है। PostgreSQL में स्केलिंग अधिक हॉट स्टैंडबाय जोड़कर प्राप्त की जाती है, इस प्रकार केवल-पढ़ने के लिए गतिविधि के लिए अधिक संसाधन प्रदान करता है। repmgr के साथ नया स्टैंडबाय जोड़ना आसान है जैसा कि हमने पहले स्टैंडबाय क्लोन . के माध्यम से देखा था और स्टैंडबाय रजिस्टर आदेश। जोड़े गए स्टैंडबाय (या हटाए गए) को लोड-बैलेंसर के कॉन्फ़िगरेशन से अवगत कराया जाना चाहिए। HAProxy, जैसा कि ऊपर प्रबंधन विषय में बताया गया है, PostgreSQL के लिए एक लोकप्रिय लोड बैलेंसर है। आमतौर पर इसे Keepalived के साथ जोड़ा जाता है जो VRRP के माध्यम से वर्चुअल IP प्रदान करता है। PostgreSQL के साथ HAProxy और Keepalived का उपयोग करने का एक अच्छा अवलोकन इस लेख में पाया जा सकता है:HAProxy और Keepalived का उपयोग करके PostgreSQL लोड संतुलन।
निगरानी
पोस्टग्रेएसक्यूएल में क्या मॉनिटर करना है इसका एक सिंहावलोकन इस लेख में पाया जा सकता है:पोस्टग्रेएसक्यूएल में मॉनिटर करने के लिए मुख्य चीजें - अपने कार्यभार का विश्लेषण। ऐसे कई उपकरण हैं जो प्लगइन्स के माध्यम से सिस्टम और पोस्टग्रेस्क्ल मॉनिटरिंग प्रदान कर सकते हैं। कुछ उपकरण ऐतिहासिक मूल्यों (मुनिन) के ग्राफिकल चार्ट को प्रस्तुत करने के क्षेत्र को कवर करते हैं, अन्य उपकरण लाइव डेटा की निगरानी और लाइव अलर्ट (नागियोस) प्रदान करने के क्षेत्र को कवर करते हैं, जबकि कुछ उपकरण दोनों क्षेत्रों (ज़बिक्स) को कवर करते हैं। PostgreSQL के लिए ऐसे टूल की सूची यहां पाई जा सकती है:https://wiki.postgresql.org/wiki/Monitoring। ऑफ़लाइन (लॉग फ़ाइल आधारित) निगरानी के लिए एक लोकप्रिय उपकरण pgBadger है। pgBadger एक पर्ल स्क्रिप्ट है जो पोस्टग्रेएसक्यूएल लॉग (जो आमतौर पर एक दिन की गतिविधि को कवर करती है) को पार्स करके काम करती है, जानकारी निकालने, आंकड़ों की गणना करने और अंत में परिणाम प्रस्तुत करने वाले फैंसी एचटीएमएल पेज का निर्माण करती है। pgBadger log_line_prefix सेटिंग पर प्रतिबंधात्मक नहीं है, यह आपके पहले से मौजूद प्रारूप के अनुकूल हो सकता है। उदाहरण के लिए यदि आपने अपने postgresql.conf में कुछ इस तरह सेट किया है:
log_line_prefix = '%r [%p] %c %m %a %example@sqldat.com%d line:%l 'फिर लॉग फ़ाइल को पार्स करने और परिणाम उत्पन्न करने के लिए pgbbadger कमांड इस तरह दिख सकता है:
./pgbadger --prefix='%r [%p] %c %m %a %example@sqldat.com%d line:%l ' -Z +2 -o pgBadger_$today.html $yesterdayfile.log && rm -f $yesterdayfile.logpgBadger इसके लिए रिपोर्ट प्रदान करता है:
- अवलोकन आँकड़े (ज्यादातर SQL ट्रैफ़िक)
- कनेक्शन (प्रति सेकंड, प्रति डेटाबेस/उपयोगकर्ता/होस्ट)
- सत्र (संख्या, सत्र समय, प्रति डेटाबेस/उपयोगकर्ता/होस्ट/एप्लिकेशन)
- चेकप्वाइंट (बफ़र, वॉल फ़ाइलें, गतिविधि)
- अस्थायी फ़ाइलें उपयोग
- वैक्यूम/विश्लेषण गतिविधि (प्रति तालिका, टुपल्स/पृष्ठ हटाए गए)
- ताले
- प्रश्न (प्रकार/डेटाबेस/उपयोगकर्ता/होस्ट/एप्लिकेशन, उपयोगकर्ता द्वारा अवधि)
- शीर्ष (प्रश्न:सबसे धीमा, समय लेने वाला, अधिक बार-बार, सामान्यीकृत सबसे धीमा)
- ईवेंट (त्रुटियां, चेतावनियां, घातक, आदि)
सत्र दिखाने वाली स्क्रीन इस तरह दिखती है:
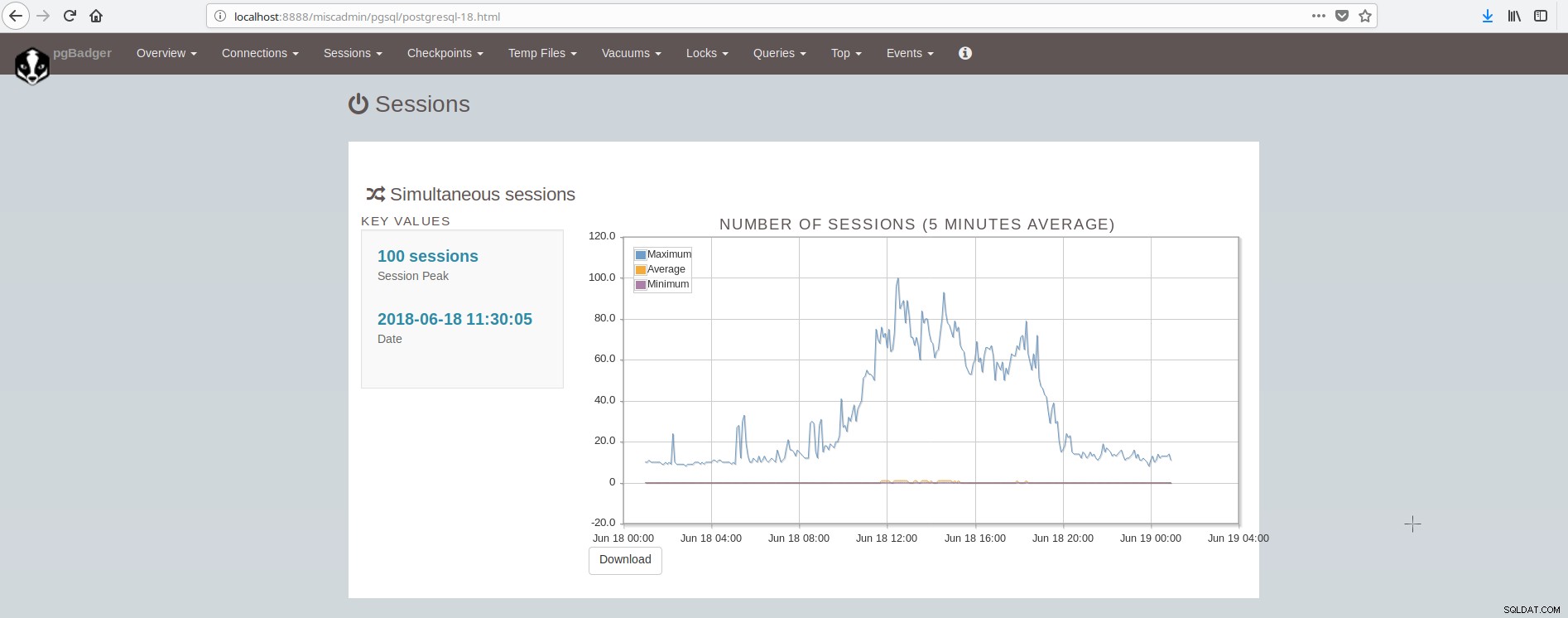
जैसा कि हम निष्कर्ष निकाल सकते हैं, औसत PostgreSQL स्थापना को आधुनिक विश्वसनीय और तेज़ बुनियादी ढांचे के लिए कई उपकरणों को एकीकृत और देखभाल करना पड़ता है और यह हासिल करने के लिए काफी जटिल है, जब तक कि पोस्टग्रेस्क्ल और सिस्टम प्रशासन में बड़ी टीम शामिल न हो। एक बढ़िया सुइट जो उपरोक्त सभी और बहुत कुछ करता है, वह है ClusterControl।