जो हिस्सा मुझे हमेशा भ्रमित करने वाला लगा वह है स्टार्टअप लागत बनाम कुल लागत। मैं इसे हर बार भूल जाता हूं, जो मुझे यहां वापस लाता है, जो अंतर की व्याख्या नहीं करता है, इसलिए मैं यह उत्तर लिख रहा हूं। पोस्टग्रेज EXPLAIN . से मैंने यही पाया है दस्तावेज़ीकरण, जैसा कि मैं इसे समझता हूं, समझाया गया।
फ़ोरम को प्रबंधित करने वाले एप्लिकेशन का एक उदाहरण यहां दिया गया है:
EXPLAIN SELECT * FROM post LIMIT 50;
Limit (cost=0.00..3.39 rows=50 width=422)
-> Seq Scan on post (cost=0.00..15629.12 rows=230412 width=422)
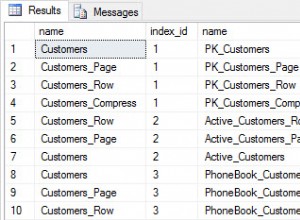
यहाँ PgAdmin की ओर से चित्रमय व्याख्या दी गई है:

(जब आप PgAdmin का उपयोग कर रहे हैं, तो आप लागत विवरण पढ़ने के लिए अपने माउस को एक घटक पर इंगित कर सकते हैं।)
लागत को टपल के रूप में दर्शाया जाता है, उदा। LIMIT . की लागत cost=0.00..3.39 . है और क्रमिक रूप से स्कैन करने की लागत post है cost=0.00..15629.12 . टपल में पहला नंबर स्टार्टअप लागत . है और दूसरा नंबर है कुल लागत . क्योंकि मैंने EXPLAIN . का इस्तेमाल किया है और नहीं EXPLAIN ANALYZE , ये लागतें अनुमान हैं, वास्तविक उपाय नहीं।
- स्टार्टअप लागत एक पेचीदा अवधारणा है। यह उस घटक के शुरू होने . से पहले के समय की मात्रा का केवल प्रतिनिधित्व नहीं करता है . यह उस समय की मात्रा का प्रतिनिधित्व करता है जब घटक निष्पादित करना शुरू करता है (डेटा में पढ़ना) और जब घटक अपनी पहली पंक्ति को आउटपुट करता है ।
- कुल लागत घटक का संपूर्ण निष्पादन समय है, जब से यह डेटा में पढ़ना शुरू करता है और जब यह अपना आउटपुट लिखना समाप्त करता है।
एक जटिलता के रूप में, प्रत्येक "पैरेंट" नोड की लागत में उसके चाइल्ड नोड्स की लागत शामिल होती है। पाठ प्रतिनिधित्व में, पेड़ को इंडेंटेशन द्वारा दर्शाया जाता है, उदा। LIMIT एक पैरेंट नोड है और Seq Scan इसका बच्चा है। PgAdmin प्रतिनिधित्व में, तीर बच्चे से माता-पिता की ओर इंगित करते हैं - डेटा के प्रवाह की दिशा - जो कि यदि आप ग्राफ़ सिद्धांत से परिचित हैं, तो यह उल्टा हो सकता है।
दस्तावेज़ीकरण कहता है कि लागत में सभी चाइल्ड नोड्स शामिल हैं, लेकिन ध्यान दें कि माता-पिता की कुल लागत 3.39 अपने बच्चे की कुल लागत से बहुत कम है 15629.12 . कुल लागत शामिल नहीं है क्योंकि LIMIT . जैसा एक घटक इसके संपूर्ण इनपुट को संसाधित करने की आवश्यकता नहीं है। देखें EXPLAIN SELECT * FROM tenk1 WHERE unique1 < 100 AND unique2 > 9000 LIMIT 2; पोस्टग्रेज में उदाहरण EXPLAIN दस्तावेज़ीकरण।
उपरोक्त उदाहरण में, दोनों घटकों के लिए स्टार्टअप समय शून्य है, क्योंकि पंक्तियों को लिखना शुरू करने से पहले किसी भी घटक को कोई प्रसंस्करण करने की आवश्यकता नहीं है:एक अनुक्रमिक स्कैन तालिका की पहली पंक्ति को पढ़ता है और इसे उत्सर्जित करता है। LIMIT इसकी पहली पंक्ति पढ़ता है और फिर इसे उत्सर्जित करता है।
किसी भी पंक्ति को आउटपुट शुरू करने से पहले किसी घटक को बहुत अधिक प्रसंस्करण करने की आवश्यकता कब होगी? कई संभावित कारण हैं, लेकिन आइए एक स्पष्ट उदाहरण देखें। यहां पहले की वही क्वेरी है लेकिन अब इसमें ORDER BY है खंड:
EXPLAIN SELECT * FROM post ORDER BY body LIMIT 50;
Limit (cost=23283.24..23283.37 rows=50 width=422)
-> Sort (cost=23283.24..23859.27 rows=230412 width=422)
Sort Key: body
-> Seq Scan on post (cost=0.00..15629.12 rows=230412 width=422)
और ग्राफिक रूप से:
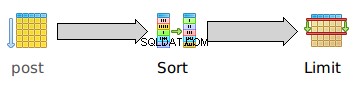
एक बार फिर, post . पर अनुक्रमिक स्कैन इसकी कोई स्टार्टअप लागत नहीं है:यह तुरंत पंक्तियों को आउटपुट करना शुरू कर देता है। लेकिन इस प्रकार की स्टार्टअप लागत महत्वपूर्ण है 23283.24 क्योंकि इसे एक भी पंक्ति को आउटपुट करने से पहले पूरी तालिका को सॉर्ट करना होगा . प्रकार की कुल लागत 23859.27 स्टार्टअप लागत की तुलना में केवल थोड़ा अधिक है, इस तथ्य को दर्शाता है कि एक बार संपूर्ण डेटासेट को सॉर्ट करने के बाद, सॉर्ट किया गया डेटा बहुत तेज़ी से उत्सर्जित किया जा सकता है।
ध्यान दें कि LIMIT . का स्टार्टअप समय 23283.24 इस प्रकार के स्टार्टअप समय के बिल्कुल बराबर है। ऐसा इसलिए नहीं है क्योंकि LIMIT अपने आप में एक उच्च स्टार्टअप समय है। यह वास्तव में अपने आप में शून्य स्टार्टअप समय है, लेकिन EXPLAIN प्रत्येक माता-पिता के लिए सभी बच्चे की लागतों को रोल अप करता है, इसलिए LIMIT स्टार्टअप समय में इसके बच्चों के स्टार्टअप समय का योग शामिल होता है।
लागतों का यह रोलअप प्रत्येक व्यक्तिगत घटक की निष्पादन लागत को समझना मुश्किल बना सकता है। उदाहरण के लिए, हमारा LIMIT शून्य स्टार्टअप समय है, लेकिन यह पहली नज़र में स्पष्ट नहीं है। इस कारण से, कई अन्य लोग, ह्यूबर्ट लुबाज़ेवस्की (a.k.a. depesz) द्वारा बनाया गया एक टूल, जो EXPLAIN को समझने में मदद करता है, से जुड़ा हुआ है। द्वारा - अन्य बातों के अलावा - माता-पिता की लागत से बच्चे की लागत घटाना। उन्होंने अपने टूल के बारे में एक संक्षिप्त ब्लॉग पोस्ट में कुछ अन्य जटिलताओं का उल्लेख किया है।