SQL DDL (डेटा परिभाषा भाषा) कथन इस तरह दिख सकते हैं:
CREATE TABLE product (
product_id serial PRIMARY KEY -- implicit primary key constraint
, product text NOT NULL
, price numeric NOT NULL DEFAULT 0
);
CREATE TABLE bill (
bill_id serial PRIMARY KEY
, bill text NOT NULL
, billdate date NOT NULL DEFAULT CURRENT_DATE
);
CREATE TABLE bill_product (
bill_id int REFERENCES bill (bill_id) ON UPDATE CASCADE ON DELETE CASCADE
, product_id int REFERENCES product (product_id) ON UPDATE CASCADE
, amount numeric NOT NULL DEFAULT 1
, CONSTRAINT bill_product_pkey PRIMARY KEY (bill_id, product_id) -- explicit pk
);
मैंने कुछ समायोजन किए:
-
n:m संबंध आमतौर पर एक अलग तालिका द्वारा कार्यान्वित किया जाता है -
bill_productइस मामले में। -
मैंने
serialadded जोड़ा प्राथमिक कुंजियों को सरोगेट करें . के रूप में कॉलम . Postgres 10 या बाद के संस्करण मेंIDENTITY. पर विचार करें इसके बजाय कॉलम। देखें:- क्रमिक प्राथमिक कुंजी कॉलम का उपयोग करके तालिकाओं का सुरक्षित रूप से नाम बदलें
- ऑटो इंक्रीमेंट टेबल कॉलम
- https://www.2ndquadrant.com/hi/blog/postgresql-10-identity-columns/
मैं इसकी अत्यधिक अनुशंसा करता हूं, क्योंकि किसी उत्पाद का नाम शायद ही अद्वितीय हो (एक अच्छी "प्राकृतिक कुंजी" नहीं)। साथ ही, विशिष्टता को लागू करना और कॉलम को विदेशी कुंजियों में संदर्भित करना आमतौर पर 4-बाइट
integerके साथ सस्ता होता है। (या यहां तक कि एक 8-बाइटbigint)text. के रूप में संग्रहीत स्ट्रिंग के बजाय याvarchar। -
बुनियादी डेटा प्रकारों जैसे
date. के नामों का उपयोग न करें पहचानकर्ता . के रूप में . हालांकि यह संभव है, यह खराब शैली है और भ्रमित करने वाली त्रुटियों और त्रुटि संदेशों की ओर ले जाती है। कानूनी, लोअर केस, गैर-उद्धृत पहचानकर्ताओं का प्रयोग करें। कभी भी आरक्षित शब्दों का प्रयोग न करें और यदि संभव हो तो दोहरे-उद्धृत मिश्रित केस पहचानकर्ताओं से बचें। -
"नाम" एक अच्छा नाम नहीं है। मैंने तालिका के कॉलम का नाम बदल दिया
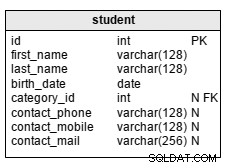
productproductहोने के लिए (याproduct_nameया इसी के समान)। यह एक बेहतर नामकरण परंपरा है . अन्यथा, जब आप किसी क्वेरी में कुछ तालिकाओं को जोड़ते हैं - जो आप बहुत कुछ करते हैं एक संबंधपरक डेटाबेस में - आप "नाम" नामक कई कॉलम के साथ समाप्त होते हैं और गड़बड़ी को हल करने के लिए कॉलम उपनाम का उपयोग करना पड़ता है। यह मददगार नहीं है। कॉलम नाम के रूप में एक और व्यापक विरोधी पैटर्न सिर्फ "id" होगा।
मुझे यकीन नहीं है किbillका नाम क्या है होगा।bill_idशायद इस मामले में पर्याप्त होगा। -
priceडेटा प्रकार . का हैnumericभिन्नात्मक संख्याओं को संगृहीत करने के लिए ठीक वैसे ही जैसे दर्ज किया गया है (फ़्लोटिंग पॉइंट प्रकार के बजाय मनमाना सटीक प्रकार)। यदि आप विशेष रूप से पूर्ण संख्याओं से निपटते हैं, तो वहintegerबनाएं . उदाहरण के लिए, आप कीमतों को सेंट के रूप में बचा सकते हैं । -
amount("Products"आपके प्रश्न में) लिंकिंग तालिका में जाता हैbill_productऔरnumeric. प्रकार का है भी। फिर से,integerयदि आप पूर्ण संख्याओं के साथ विशेष रूप से व्यवहार करते हैं। -
आपको विदेशी कुंजियां दिखाई देती हैं
bill_product. में ? मैंने दोनों को कैस्केड परिवर्तनों के लिए बनाया है:ON UPDATE CASCADE. अगर एकproduct_idयाbill_idबदलना चाहिए, परिवर्तनbill_product. में सभी निर्भर प्रविष्टियों के लिए कैस्केड किया गया है और कुछ नहीं टूटता। वे केवल अपने स्वयं के महत्व के बिना संदर्भ हैं।
मैंनेON DELETE CASCADEका भी उपयोग किया हैbill_id. के लिए :यदि कोई बिल हटा दिया जाता है, तो उसका विवरण उसके साथ समाप्त हो जाता है।
उत्पादों के लिए ऐसा नहीं है:आप किसी बिल में उपयोग किए गए उत्पाद को हटाना नहीं चाहते हैं। यदि आप यह प्रयास करते हैं तो पोस्टग्रेज एक त्रुटि फेंक देगा। आपproduct. में एक और कॉलम जोड़ेंगे इसके बजाय अप्रचलित पंक्तियों ("सॉफ्ट-डिलीट") को चिह्नित करने के लिए। -
इस मूल उदाहरण के सभी कॉलम
NOT NULL. के रूप में समाप्त होते हैं , इसलिएNULLमूल्यों की अनुमति नहीं है। (हां, सभी कॉलम - प्राथमिक कुंजी कॉलम परिभाषित हैंUNIQUE NOT NULLस्वचालित रूप से।) ऐसा इसलिए है क्योंकिNULLमान किसी भी कॉलम में समझ में नहीं आएंगे। यह एक नौसिखिया के जीवन को आसान बनाता है। लेकिन आप इतनी आसानी से नहीं निकलेंगे, आपकोNULLको समझने की जरूरत है वैसे भी संभालना। अतिरिक्त कॉलमNULLallow की अनुमति दे सकते हैं मान, फ़ंक्शन और जॉइनNULLintroduce को पेश कर सकते हैं प्रश्नों आदि में मूल्य। -
CREATE TABLEपर अध्याय पढ़ें मैनुअल में। -
प्राथमिक कुंजियाँ एक अद्वितीय अनुक्रमणिका . के साथ क्रियान्वित की जाती हैं कुंजी कॉलम पर, जो पीके कॉलम पर शर्तों के साथ तेजी से पूछताछ करता है। हालाँकि, बहु-स्तंभ कुंजियों में कुंजी स्तंभों का क्रम प्रासंगिक है। चूंकि PK
bill_product. पर है(bill_id, product_id)पर है मेरे उदाहरण में, आप केवलproduct_id. पर एक और अनुक्रमणिका जोड़ना चाह सकते हैं या(product_id, bill_id)यदि आपके पास दिए गएproduct_id. की तलाश में कोई प्रश्न हैं और नहींbill_id. देखें:- PostgreSQL समग्र प्राथमिक कुंजी
- क्या पहले फ़ील्ड पर प्रश्नों के लिए एक समग्र अनुक्रमणिका भी अच्छी है?
- PostgreSQL में अनुक्रमणिका का कार्य करना
-
मैनुअल में इंडेक्स पर अध्याय पढ़ें।