SQL Server सेट-आधारित संचालन में सबसे अच्छा है, जबकि CASCADE विलोपन, उनके स्वभाव से, रिकॉर्ड-आधारित होते हैं।
SQL Server , अन्य सर्वरों के विपरीत, तत्काल सेट-आधारित संचालन को अनुकूलित करने का प्रयास करता है, हालांकि, यह केवल एक स्तर की गहराई तक काम करता है। निचले स्तर की तालिकाओं में रिकॉर्ड को हटाने के लिए इसे ऊपरी-स्तर की तालिकाओं में हटाए जाने की आवश्यकता है।
दूसरे शब्दों में, कैस्केडिंग ऑपरेशन ऊपर-नीचे काम करते हैं, जबकि आपका समाधान डाउन-अप काम करता है, जो अधिक सेट-आधारित और कुशल है।
यहाँ एक नमूना स्कीमा है:
CREATE TABLE t_g (id INT NOT NULL PRIMARY KEY)
CREATE TABLE t_p (id INT NOT NULL PRIMARY KEY, g INT NOT NULL, CONSTRAINT fk_p_g FOREIGN KEY (g) REFERENCES t_g ON DELETE CASCADE)
CREATE TABLE t_c (id INT NOT NULL PRIMARY KEY, p INT NOT NULL, CONSTRAINT fk_c_p FOREIGN KEY (p) REFERENCES t_p ON DELETE CASCADE)
CREATE INDEX ix_p_g ON t_p (g)
CREATE INDEX ix_c_p ON t_c (p)
, यह प्रश्न:
DELETE
FROM t_g
WHERE id > 50000
और इसकी योजना:
|--Sequence
|--Table Spool
| |--Clustered Index Delete(OBJECT:([test].[dbo].[t_g].[PK__t_g__176E4C6B]), WHERE:([test].[dbo].[t_g].[id] > (50000)))
|--Index Delete(OBJECT:([test].[dbo].[t_p].[ix_p_g]) WITH ORDERED PREFETCH)
| |--Sort(ORDER BY:([test].[dbo].[t_p].[g] ASC, [test].[dbo].[t_p].[id] ASC))
| |--Table Spool
| |--Clustered Index Delete(OBJECT:([test].[dbo].[t_p].[PK__t_p__195694DD]) WITH ORDERED PREFETCH)
| |--Sort(ORDER BY:([test].[dbo].[t_p].[id] ASC))
| |--Merge Join(Inner Join, MERGE:([test].[dbo].[t_g].[id])=([test].[dbo].[t_p].[g]), RESIDUAL:([test].[dbo].[t_p].[g]=[test].[dbo].[t_g].[id]))
| |--Table Spool
| |--Index Scan(OBJECT:([test].[dbo].[t_p].[ix_p_g]), ORDERED FORWARD)
|--Index Delete(OBJECT:([test].[dbo].[t_c].[ix_c_p]) WITH ORDERED PREFETCH)
|--Sort(ORDER BY:([test].[dbo].[t_c].[p] ASC, [test].[dbo].[t_c].[id] ASC))
|--Clustered Index Delete(OBJECT:([test].[dbo].[t_c].[PK__t_c__1C330188]) WITH ORDERED PREFETCH)
|--Table Spool
|--Sort(ORDER BY:([test].[dbo].[t_c].[id] ASC))
|--Hash Match(Inner Join, HASH:([test].[dbo].[t_p].[id])=([test].[dbo].[t_c].[p]))
|--Table Spool
|--Index Scan(OBJECT:([test].[dbo].[t_c].[ix_c_p]), ORDERED FORWARD)
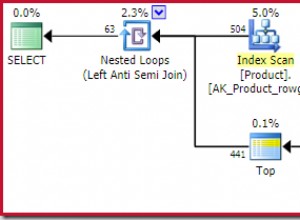
सबसे पहले, SQL Server t_g . से रिकॉर्ड हटाता है , फिर t_p . के साथ हटाए गए रिकॉर्ड में शामिल हो जाता है और बाद वाले से हटाता है, अंत में, t_p . से हटाए गए रिकॉर्ड में शामिल हो जाता है t_c . के साथ और t_c . से हटाता है ।
इस मामले में एक सिंगल थ्री-टेबल जॉइन अधिक कुशल होगा, और यही आप अपने वर्कअराउंड के साथ करते हैं।
अगर यह आपको बेहतर महसूस कराता है, Oracle कैस्केड संचालन को किसी भी तरह से अनुकूलित नहीं करता है:वे हमेशा NESTED LOOPS . होते हैं और यदि आप संदर्भ स्तंभ पर एक अनुक्रमणिका बनाना भूल गए हैं तो ईश्वर आपकी सहायता करता है।