सबट्री की लागत नमक के एक बड़े दाने के साथ ली जानी चाहिए (और विशेष रूप से तब जब आपके पास बड़ी कार्डिनैलिटी त्रुटियां हों)। SET STATISTICS IO ON; SET STATISTICS TIME ON; आउटपुट वास्तविक प्रदर्शन का एक बेहतर संकेतक है।
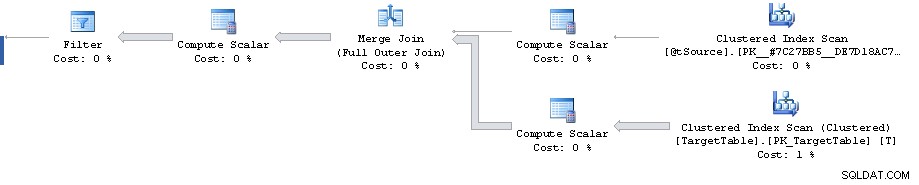
शून्य पंक्ति क्रम में 87% संसाधन नहीं लगते हैं। आपकी योजना में यह समस्या सांख्यिकी अनुमानों में से एक है। वास्तविक योजना में दिखाई गई लागतें अभी भी अनुमानित लागतें हैं। यह वास्तव में जो हुआ उसका हिसाब लेने के लिए उन्हें समायोजित नहीं करता है।
योजना में एक बिंदु है जहां एक फ़िल्टर 1,911,721 पंक्तियों को घटाकर 0 कर देता है लेकिन आगे जाने वाली अनुमानित पंक्तियाँ 1,860,310 हैं। इसके बाद सभी लागतें फर्जी हैं और 87% लागत अनुमानित 3,348,560 पंक्ति क्रम में समाप्त होती हैं।
कार्डिनैलिटी अनुमान त्रुटि को Merge . के बाहर पुन:प्रस्तुत किया जा सकता है Full Outer Join . के लिए अनुमानित योजना को देखकर स्टेटमेंट समतुल्य विधेय के साथ (समान 1,860,310 पंक्ति अनुमान देता है)।
SELECT *
FROM TargetTable T
FULL OUTER JOIN @tSource S
ON S.Key1 = T.Key1 and S.Key2 = T.Key2
WHERE
CASE WHEN S.Key1 IS NOT NULL
/*Matched by Source*/
THEN CASE WHEN T.Key1 IS NOT NULL
/*Matched by Target*/
THEN CASE WHEN [T].[Data1]<>S.[Data1] OR
[T].[Data2]<>S.[Data2] OR
[T].[Data3]<>S.[Data3]
THEN (1)
END
/*Not Matched by Target*/
ELSE (4)
END
/*Not Matched by Source*/
ELSE CASE WHEN [T].[Key1]example@sqldat.com
THEN (3)
END
END IS NOT NULL
हालांकि यह कहा गया है कि फ़िल्टर तक की योजना ही काफी उप-इष्टतम दिखती है। यह एक पूर्ण क्लस्टर इंडेक्स स्कैन कर रहा है जब शायद आप 2 क्लस्टर इंडेक्स रेंज के साथ एक योजना चाहते हैं। एक स्रोत पर शामिल होने से प्राथमिक कुंजी से मेल खाने वाली एकल पंक्ति को पुनः प्राप्त करने के लिए और दूसरा T.Key1 = @id को पुनः प्राप्त करने के लिए रेंज (हालांकि शायद यह बाद में क्लस्टर किए गए कुंजी क्रम में सॉर्ट करने की आवश्यकता से बचने के लिए है?)
शायद आप इस पुनर्लेखन का प्रयास कर सकते हैं और देख सकते हैं कि यह बेहतर या बदतर काम करता है या नहीं
;WITH FilteredTarget AS
(
SELECT T.*
FROM TargetTable AS T WITH (FORCESEEK)
JOIN @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
OR T.Key1 = @id
)
MERGE FilteredTarget AS T
USING @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
-- Only update if the Data columns do not match
WHEN MATCHED AND S.Key1 = T.Key1 AND S.Key2 = T.Key2 AND
(T.Data1 <> S.Data1 OR
T.Data2 <> S.Data2 OR
T.Data3 <> S.Data3) THEN
UPDATE SET T.Data1 = S.Data1,
T.Data2 = S.Data2,
T.Data3 = S.Data3
-- Note from original poster: This extra "safety clause" turned out not to
-- affect the behavior or the execution plan, so I removed it and it works
-- just as well without, but if you find yourself in a similar situation
-- you might want to give it a try.
-- WHEN MATCHED AND (S.Key1 <> T.Key1 OR S.Key2 <> T.Key2) AND T.Key1 = @id THEN
-- DELETE
-- Insert when missing in the target
WHEN NOT MATCHED BY TARGET THEN
INSERT (Key1, Key2, Data1, Data2, Data3)
VALUES (Key1, Key2, Data1, Data2, Data3)
WHEN NOT MATCHED BY SOURCE AND T.Key1 = @id THEN
DELETE;