आप (ab) उपयोग कर सकते हैं MERGE
OUTPUT के साथ खंड।
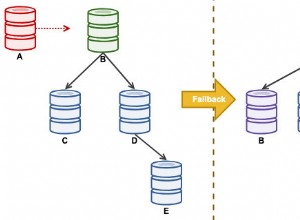
MERGE कर सकते हैं INSERT , UPDATE और DELETE पंक्तियाँ। हमारे मामले में हमें केवल INSERT . की आवश्यकता है .1=0 हमेशा झूठा होता है, इसलिए NOT MATCHED BY TARGET भाग हमेशा निष्पादित होता है। सामान्य तौर पर, अन्य शाखाएं हो सकती हैं, दस्तावेज़ देखें।WHEN MATCHED आमतौर पर UPDATE . के लिए उपयोग किया जाता है;WHEN NOT MATCHED BY SOURCE आमतौर पर DELETE . के लिए उपयोग किया जाता है , लेकिन हमें यहां उनकी आवश्यकता नहीं है।
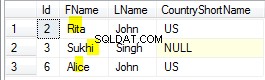
MERGE . का यह जटिल रूप सरल INSERT . के बराबर है , लेकिन साधारण INSERT . के विपरीत इसका OUTPUT खंड उन स्तंभों को संदर्भित करने की अनुमति देता है जिनकी हमें आवश्यकता है। यह स्रोत और गंतव्य तालिका दोनों से स्तंभों को पुनः प्राप्त करने की अनुमति देता है इस प्रकार पुरानी और नई आईडी के बीच मानचित्रण को सहेजता है।
MERGE INTO [dbo].[Test]
USING
(
SELECT [Data]
FROM @Old AS O
) AS Src
ON 1 = 0
WHEN NOT MATCHED BY TARGET THEN
INSERT ([Data])
VALUES (Src.[Data])
OUTPUT Src.ID AS OldID, inserted.ID AS NewID
INTO @New(ID, [OtherID])
;
आपके अपडेट के संबंध में और जेनरेट किए गए IDENTITY . के क्रम पर निर्भर मान।
साधारण स्थिति में, जब [dbo].[Test] IDENTITY है कॉलम, फिर INSERT ORDER BY . के साथ होगा गारंटी है कि उत्पन्न IDENTITY मान निर्दिष्ट क्रम में होंगे। एसक्यूएल सर्वर में गारंटी ऑर्डर करना . ध्यान रहे, यह सम्मिलित पंक्तियों के भौतिक क्रम की गारंटी नहीं देता है, लेकिन यह उस क्रम की गारंटी देता है जिसमें IDENTITY मान उत्पन्न होते हैं।
INSERT INTO [dbo].[Test] ([Data])
SELECT [Data]
FROM @Old
ORDER BY [RowID]
लेकिन, जब आप OUTPUT . का उपयोग करते हैं खंड:
INSERT INTO [dbo].[Test] ([Data])
OUTPUT inserted.[ID] INTO @New
SELECT [Data]
FROM @Old
ORDER BY [RowID]
OUTPUT में पंक्तियाँ धारा का आदेश नहीं है। कम से कम, कड़ाई से बोलते हुए, ORDER BY क्वेरी में प्राथमिक INSERT . पर लागू होता है ऑपरेशन, लेकिन वहाँ कुछ भी नहीं है जो कहता है कि OUTPUT . का क्रम क्या है . इसलिए, मैं उस पर भरोसा करने की कोशिश नहीं करूंगा। या तो MERGE का उपयोग करें या आईडी के बीच मैपिंग को स्पष्ट रूप से संग्रहीत करने के लिए एक अतिरिक्त कॉलम जोड़ें।