MySQL मास्टर-स्लेव प्रतिकृति स्थापित करने के लिए बहुत आसान और सरल है। यही मुख्य कारण है कि लोग बेहतर डेटाबेस उपलब्धता प्राप्त करने के लिए इस तकनीक को पहले कदम के रूप में चुनते हैं। हालांकि, यह प्रबंधन और रखरखाव में जटिलता की कीमत पर आता है; विशेष रूप से फ़ेलओवर, फ़ेलबैक, रखरखाव, अपग्रेड आदि के दौरान डेटा अखंडता को बनाए रखना व्यवस्थापक पर निर्भर है।
प्रतिकृति सेटअप के लिए फ़ेलओवर ऑपरेशन करने के तरीके के बारे में वर्णन करने वाले कई लेख हैं। हमने इस ब्लॉग पोस्ट में इस विषय को भी शामिल किया है, MySQL प्रतिकृति के लिए विफलता का परिचय - 101 ब्लॉग। इस ब्लॉग पोस्ट में, हम मूल टोपोलॉजी को पुनर्स्थापित करते समय आपदा के बाद के कार्यों को कवर करने जा रहे हैं - फेलबैक ऑपरेशन करना।
हमें फ़ेलबैक की आवश्यकता क्यों है?
प्रतिकृति सेटअप में प्रतिकृति नेता (मास्टर) सबसे महत्वपूर्ण नोड है। यह सुनिश्चित करने के लिए अच्छे हार्डवेयर स्पेक्स की आवश्यकता है कि यह लिखने की प्रक्रिया कर सकता है, प्रतिकृति घटनाओं को उत्पन्न कर सकता है, महत्वपूर्ण पढ़ने की प्रक्रिया कर सकता है और इसी तरह एक स्थिर तरीके से। जब आपदा पुनर्प्राप्ति या रखरखाव के दौरान फ़ेलओवर की आवश्यकता होती है, तो हमें निम्न हार्डवेयर के साथ एक नए नेता को बढ़ावा देना असामान्य नहीं हो सकता है। यह स्थिति अस्थायी रूप से ठीक हो सकती है, हालांकि लंबे समय के लिए, नामित मास्टर को स्वस्थ होने के बाद प्रतिकृति का नेतृत्व करने के लिए वापस लाया जाना चाहिए।
फ़ेलओवर के विपरीत, फ़ेलबैक ऑपरेशन आमतौर पर स्विचओवर के माध्यम से नियंत्रित वातावरण में होता है, यह शायद ही कभी पैनिक-मोड में होता है। इससे ऑपरेशन टीम को सावधानीपूर्वक योजना बनाने और सुचारू रूप से बदलाव के लिए अभ्यास का पूर्वाभ्यास करने के लिए कुछ समय मिलता है। मुख्य उद्देश्य केवल अच्छे पुराने मास्टर को नवीनतम स्थिति में वापस लाना और प्रतिकृति सेटअप को उसके मूल टोपोलॉजी में पुनर्स्थापित करना है। हालांकि, ऐसे कुछ मामले हैं जहां फ़ेलबैक महत्वपूर्ण है, उदाहरण के लिए जब नए पदोन्नत मास्टर ने अपेक्षा के अनुरूप काम नहीं किया और समग्र डेटाबेस सेवा को प्रभावित किया।
फेलबैक को सुरक्षित तरीके से कैसे करें?
विफलता होने के बाद, पुराना मास्टर रखरखाव या पुनर्प्राप्ति के लिए प्रतिकृति श्रृंखला से बाहर हो जाएगा। स्विचओवर करने के लिए, निम्न कार्य करना चाहिए:
- पुराने मास्टर को सबसे अप-टू-डेट स्लेव बनाकर, सही स्थिति में लाएं।
- आवेदन बंद करो।
- सत्यापित करें कि सभी दास पकड़े गए हैं।
- पुराने गुरु को नए नेता के रूप में पदोन्नत करें।
- सभी दासों को नए स्वामी को सौंपें।
- नए मास्टर को लिखकर एप्लिकेशन प्रारंभ करें।
निम्नलिखित प्रतिकृति सेटअप पर विचार करें:
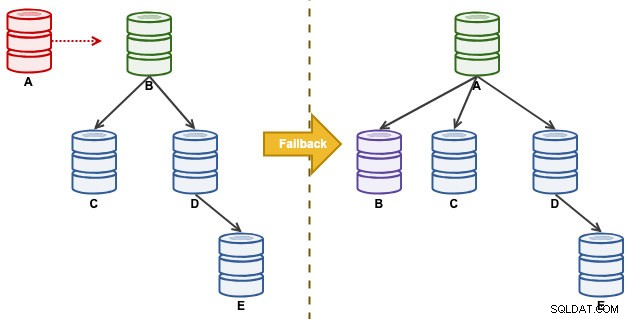
"ए" एक डिस्क-पूर्ण घटना तक एक मास्टर था जो प्रतिकृति श्रृंखला के लिए कहर पैदा करता था। एक विफलता घटना के बाद, हमारी प्रतिकृति टोपोलॉजी बी द्वारा नेतृत्व की गई थी और सी से ई तक दोहराई गई थी। फेलबैक अभ्यास ए को नेता के रूप में वापस लाएगा और आपदा से पहले मूल टोपोलॉजी को पुनर्स्थापित करेगा। ध्यान दें कि सभी नोड जीटीआईडी सक्षम के साथ MySQL 8.0.15 पर चल रहे हैं। विभिन्न प्रमुख संस्करण विभिन्न आदेशों और चरणों का उपयोग कर सकते हैं।
हालांकि फेलओवर के बाद अब हमारा आर्किटेक्चर ऐसा दिखता है (क्लस्टरकंट्रोल के टोपोलॉजी व्यू से लिया गया):
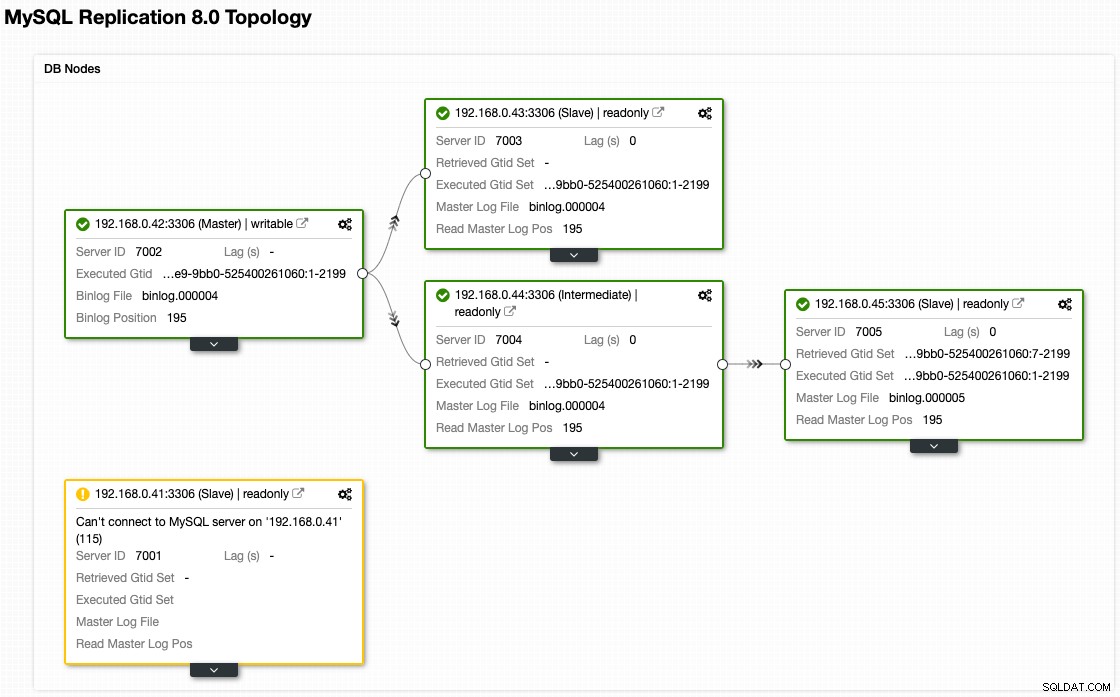
नोड प्रावधान
ए मास्टर बनने से पहले, इसे वर्तमान डेटाबेस स्थिति के साथ अद्यतित किया जाना चाहिए। ऐसा करने का सबसे अच्छा तरीका है कि ए को सक्रिय मास्टर के दास के रूप में चालू करें, बी। चूंकि सभी नोड्स log_slave_updates=ON के साथ कॉन्फ़िगर किए गए हैं (इसका मतलब है कि एक दास भी बाइनरी लॉग उत्पन्न करता है), हम वास्तव में सी और डी जैसे अन्य दासों को चुन सकते हैं प्रारंभिक समन्वयन के लिए सत्य का स्रोत। हालांकि, सक्रिय मास्टर के करीब, बेहतर। बैकअप लेते समय होने वाले अतिरिक्त भार को ध्यान में रखें। इस भाग में अधिकांश फ़ेलबैक घंटे लगते हैं। नोड स्थिति और डेटासेट आकार के आधार पर, पुराने मास्टर को सिंक करने में कुछ समय लग सकता है (यह घंटे और दिन हो सकते हैं)।
एक बार जब "ए" पर समस्या हल हो जाती है और प्रतिकृति श्रृंखला में शामिल होने के लिए तैयार हो जाती है, तो सबसे अच्छा पहला कदम "बी" (192.168.0.42) को चेंज मास्टर स्टेटमेंट के साथ दोहराने का प्रयास करना है:
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */यदि प्रतिकृति काम करती है, तो आपको प्रतिकृति स्थिति में निम्नलिखित देखना चाहिए:
Slave_IO_Running: Yes
Slave_SQL_Running: Yesयदि प्रतिकृति विफल हो जाती है, तो दास स्थिति आउटपुट से Last_IO_Error या Last_SQL_Error देखें। उदाहरण के लिए, यदि आपको निम्न त्रुटि दिखाई देती है:
Last_IO_Error: error connecting to master 'example@sqldat.com:3306' - retry-time: 60 retries: 2फिर, हमें वर्तमान सक्रिय मास्टर, बी पर प्रतिकृति उपयोगकर्ता बनाना होगा:
mysql> CREATE USER example@sqldat.com IDENTIFIED BY 'p4ss';
mysql> GRANT REPLICATION SLAVE ON *.* TO example@sqldat.com;फिर, ए पर दास को फिर से शुरू करने के लिए फिर से शुरू करें:
mysql> STOP SLAVE;
mysql> START SLAVE;अन्य सामान्य त्रुटि जो आप देखेंगे वह है यह पंक्ति:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: ...इसका शायद मतलब है कि दास को वर्तमान मास्टर से बाइनरी लॉग फ़ाइल पढ़ने में समस्या हो रही है। कुछ अवसरों में, दास उस तरह से पीछे हो सकता है जिससे प्रतिकृति शुरू करने के लिए आवश्यक बाइनरी ईवेंट वर्तमान मास्टर से गायब हो गए हैं, या मास्टर पर बाइनरी को फेलओवर के दौरान शुद्ध कर दिया गया है और इसी तरह। इस मामले में, सबसे अच्छा तरीका है कि बी पर पूर्ण बैकअप लेकर और ए पर इसे पुनर्स्थापित करके पूर्ण सिंक निष्पादित किया जाए। बी पर, आप पूर्ण बैकअप लेने के लिए या तो mysqldump या Percona Xtrabackup का उपयोग कर सकते हैं:
$ mysqldump -uroot -p --all-databases --single-transaction --triggers --routines > dump.sql # for mysqldump
$ xtrabackup --defaults-file=/etc/my.cnf --backup --parallel 1 --stream=xbstream --no-timestamp | gzip -6 - > backup-full-2019-04-16_071649.xbstream.gz # for xtrabackupबैकअप फ़ाइल को A में स्थानांतरित करें, उचित सफाई के लिए मौजूदा MySQL स्थापना को पुन:प्रारंभ करें और डेटाबेस बहाली करें:
$ systemctl stop mysqld # if mysql is still running
$ rm -Rf /var/lib/mysql # wipe out old data
$ mysqld --initialize --user=mysql # initialize database
$ systemctl start mysqld # start mysql
$ grep -i 'temporary password' /var/log/mysql/mysqld.log # retrieve the temporary root password
$ mysql -uroot -p -e 'ALTER USER example@sqldat.com IDENTIFIED BY "p455word"' # mandatory root password update
$ mysql -uroot -p < dump.sql # restore the backup using the new root passwordएक बार बहाल हो जाने पर, प्रतिकृति लिंक को सक्रिय मास्टर बी (192.168.0.42) पर सेट करें और केवल-पढ़ने के लिए सक्षम करें। A पर, निम्नलिखित कथन चलाएँ:
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */Percona Xtrabackup के लिए, कृपया दस्तावेज़ीकरण पृष्ठ देखें कि कैसे A को पुनर्स्थापित किया जाए। इसमें MySQL डेटा निर्देशिका को बदलने से पहले बैकअप तैयार करने के लिए एक पूर्वापेक्षा चरण शामिल है।
एक बार जब ए ने सही ढंग से नकल करना शुरू कर दिया, तो स्लेव स्थिति में सेकेंड_बिहाइंड_मास्टर की निगरानी करें। इससे आपको अंदाजा हो जाएगा कि गुलाम कितना पीछे छूट गया है और उसके पकड़ने से पहले आपको कितना इंतजार करना होगा। इस समय, हमारी वास्तुकला इस तरह दिखती है:
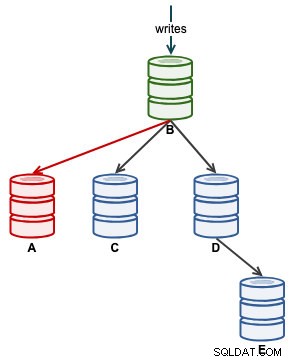
एक बार सेकंड्स_बिहाइंड_मास्टर 0 पर वापस आ जाता है, यही वह क्षण होता है जब ए ने एक अप-टू-डेट गुलाम के रूप में पकड़ लिया है।
यदि आप ClusterControl का उपयोग कर रहे हैं, तो आपके पास मौजूदा बैकअप से पुनर्स्थापित करके नोड को फिर से सिंक करने या सक्रिय मास्टर नोड से सीधे बैकअप बनाने और स्ट्रीम करने का विकल्प है:
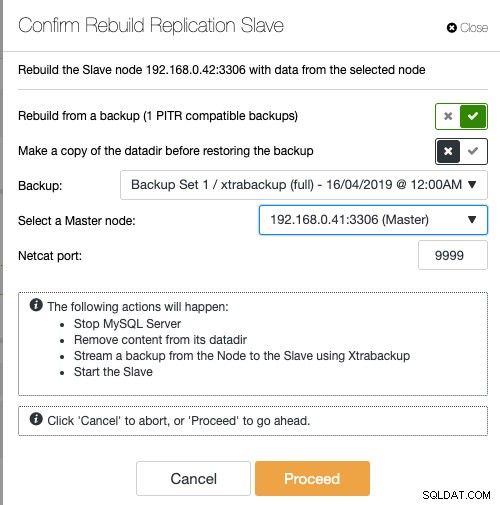
स्लेव को मौजूदा बैकअप के साथ स्टेज करना, स्लेव बनाने के लिए अनुशंसित तरीका है, क्योंकि यह नोड तैयार करते समय सक्रिय मास्टर सर्वर पर कोई प्रभाव नहीं डालता है।
पुराने मास्टर को बढ़ावा दें
A को नए मास्टर के रूप में प्रचारित करने से पहले, सबसे सुरक्षित तरीका है कि B पर सभी लेखन कार्य को रोक दिया जाए। यदि यह संभव नहीं है, तो B को केवल-पढ़ने के लिए मोड में संचालित करने के लिए बाध्य करें:
mysql> SET GLOBAL read_only = 'ON';
mysql> SET GLOBAL super_read_only = 'ON';फिर, A पर, SHOW SLAVE STATUS चलाएँ और निम्न प्रतिकृति स्थिति जाँचें:
Read_Master_Log_Pos: 45889974
Exec_Master_Log_Pos: 45889974
Seconds_Behind_Master: 0
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updatesRead_Master_Log_Pos और Exec_Master_Log_Pos का मान समान होना चाहिए, जबकि Seconds_Behind_Master 0 है और स्थिति 'स्लेव ने सभी रिले लॉग पढ़ ली है' होनी चाहिए। सुनिश्चित करें कि सभी दासों ने अपने रिले लॉग में किसी भी बयान को संसाधित किया है, अन्यथा आप जोखिम लेंगे कि नए प्रश्न रिले लॉग से लेनदेन को प्रभावित करेंगे, सभी प्रकार की समस्याओं को ट्रिगर करेंगे (उदाहरण के लिए, एक एप्लिकेशन कुछ पंक्तियों को हटा सकता है जो लेनदेन द्वारा एक्सेस की जाती हैं रिले लॉग से)।
ए पर, प्रतिकृति को रोकें और सभी प्रतिकृति-संबंधित कॉन्फ़िगरेशन को हटाने और केवल पढ़ने के लिए अक्षम करने के लिए रीसेट स्लेव सभी कथन का उपयोग करें:
mysql> STOP SLAVE;
mysql> RESET SLAVE ALL;
mysql> SET GLOBAL read_only = 'OFF';
mysql> SET GLOBAL super_read_only = 'OFF';इस बिंदु पर, ए लिखने को स्वीकार करने के लिए तैयार है (read_only=OFF), हालांकि दास इससे जुड़े नहीं हैं, जैसा कि नीचे दिखाया गया है:
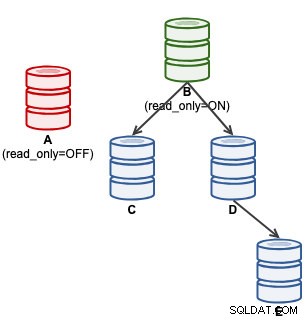
क्लस्टरकंट्रोल उपयोगकर्ताओं के लिए, नोड क्रियाओं के तहत "स्लेव को बढ़ावा दें" सुविधा का उपयोग करके ए को बढ़ावा दिया जा सकता है। ClusterControl स्वचालित रूप से सक्रिय मास्टर B को पदावनत कर देगा, दास A को मास्टर के रूप में बढ़ावा देगा और C और D को A से दोहराने के लिए पुनर्नियुक्त करेगा। B को अलग रखा जाएगा और उपयोगकर्ता को बाद के चरण में A से प्रतिकृति B को फिर से जोड़ने के लिए स्पष्ट रूप से "प्रतिकृति मास्टर बदलें" का चयन करना होगा। ।
गुलाम पुनर्नियुक्ति
ए (192.168.0.41) से दोहराने के लिए संबंधित दासों पर मास्टर को बदलना अब सुरक्षित है। ई को छोड़कर सभी दासों पर, निम्नलिखित को कॉन्फ़िगर करें:
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.41', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;यदि आप एक ClusterControl उपयोगकर्ता हैं, तो आप इस चरण को छोड़ सकते हैं क्योंकि जब आपने A को पहले प्रचारित करने का निर्णय लिया था, तब पुनर्नियुक्ति स्वचालित रूप से की जा रही थी।
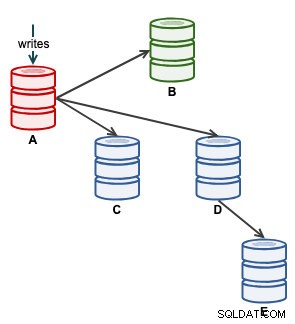
फिर हम ए पर लिखने के लिए अपना आवेदन शुरू कर सकते हैं। इस बिंदु पर, हमारी वास्तुकला कुछ इस तरह दिख रही है:
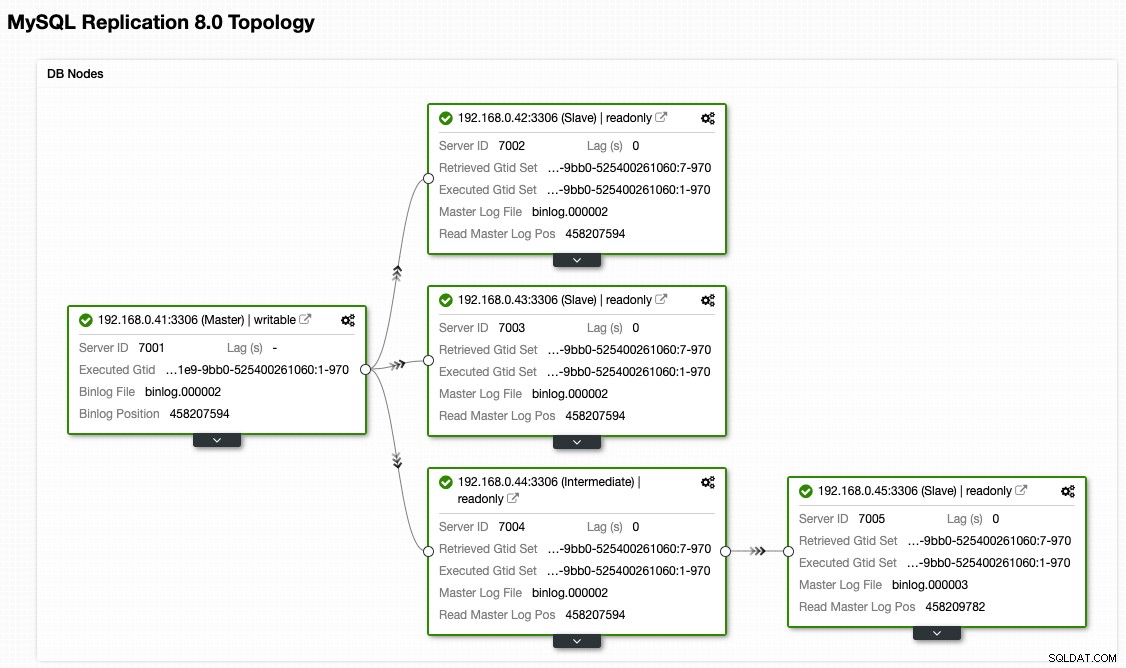
ClusterControl टोपोलॉजी दृश्य से, हमने अपने प्रतिकृति क्लस्टर को इसकी मूल वास्तुकला में पुनर्स्थापित कर दिया है जो इस तरह दिखता है:
ध्यान दें कि फ़ेलओवर की तुलना में फ़ेलबैक व्यायाम बहुत कम जोखिम भरा होता है। अपने व्यवसाय पर प्रभाव को कम करने के लिए इस अभ्यास को ऑफ-पीक घंटों के दौरान शेड्यूल करना महत्वपूर्ण है।
अंतिम विचार
फ़ेलओवर और फ़ेलबैक ऑपरेशन सावधानीपूर्वक किया जाना चाहिए। यदि आपके पास नोड्स की एक छोटी संख्या है, लेकिन जटिल प्रतिकृति श्रृंखला वाले कई नोड्स के लिए ऑपरेशन काफी सरल है, तो यह एक जोखिम भरा और त्रुटि-प्रवण अभ्यास हो सकता है। हमने यह भी दिखाया कि कैसे क्लस्टरकंट्रोल का उपयोग यूआई के माध्यम से जटिल संचालन को सरल बनाने के लिए किया जा सकता है, साथ ही टोपोलॉजी दृश्य को वास्तविक समय में देखा जाता है ताकि आपको उस प्रतिकृति टोपोलॉजी की समझ हो, जिसे आप बनाना चाहते हैं।