मुझे लगता है कि इसका कारण यह है कि उन्होंने इसे लागू करने लायक प्राथमिकता वाली विशेषता नहीं माना है। ऐसा लगता है कि पोस्टग्रेस करता है दोनों का समर्थन करें
UNION और UNION ALL ।
यदि आपके पास इस सुविधा के लिए एक मजबूत मामला है तो आप Connect पर फ़ीडबैक प्रदान कर सकते हैं। (या इसके रिप्लेसमेंट का यूआरएल जो भी होगा)।
डुप्लिकेट को जोड़े जाने से रोकना उपयोगी हो सकता है क्योंकि बाद के चरण में पिछले चरण में जोड़ी गई डुप्लिकेट पंक्ति लगभग हमेशा एक अनंत लूप का कारण बनेगी या अधिकतम रिकर्सन सीमा से अधिक हो जाएगी।
SQL मानक
में कुछ स्थान हैं जहां कोड का उपयोग UNION . प्रदर्शित करते हुए किया जाता है जैसे नीचे
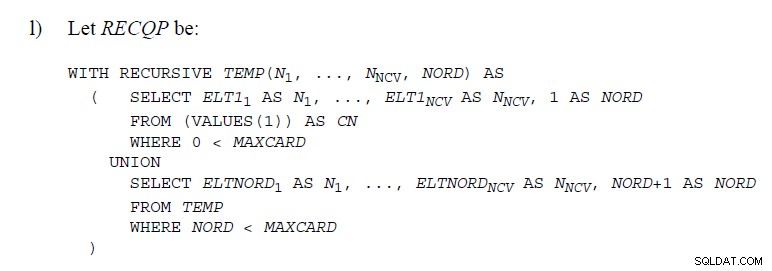
यह लेख बताता है कि उन्हें SQL सर्वर में कैसे लागू किया जाता है
ए> . वे "हुड के नीचे" ऐसा कुछ नहीं कर रहे हैं। स्टैक स्पूल पंक्तियों को हटा देता है क्योंकि यह जाता है इसलिए यह जानना संभव नहीं होगा कि बाद की पंक्ति हटाए गए एक का डुप्लिकेट है या नहीं। समर्थन UNION कुछ अलग दृष्टिकोण की आवश्यकता होगी।
इस बीच आप इसे एक बहु-कथन TVF में आसानी से प्राप्त कर सकते हैं।
नीचे एक मूर्खतापूर्ण उदाहरण लेने के लिए (Postgres Fiddle )
WITH R
AS (SELECT 0 AS N
UNION
SELECT ( N + 1 )%10
FROM R)
SELECT N
FROM R
UNION बदलना करने के लिए UNION ALL और एक DISTINCT adding जोड़ना अंत में आपको अनंत रिकर्सन से नहीं बचाएगा।
लेकिन आप इसे
. के रूप में लागू कर सकते हैंCREATE FUNCTION dbo.F ()
RETURNS @R TABLE(n INT PRIMARY KEY WITH (IGNORE_DUP_KEY = ON))
AS
BEGIN
INSERT INTO @R
VALUES (0); --anchor
WHILE @@ROWCOUNT > 0
BEGIN
INSERT INTO @R
SELECT ( N + 1 )%10
FROM @R
END
RETURN
END
GO
SELECT *
FROM dbo.F ()
उपरोक्त IGNORE_DUP_KEY का उपयोग करता है डुप्लिकेट को त्यागने के लिए। यदि कॉलम सूची अनुक्रमित होने के लिए बहुत विस्तृत है तो आपको DISTINCT . की आवश्यकता होगी और NOT EXISTS बजाय। आप शायद यह भी चाहते हैं कि एक पैरामीटर अधिकतम संख्या में पुनरावर्तन सेट करे और अनंत लूप से बचें।