SQL सर्वर 2014 CTP1 अब कुछ हफ्तों के लिए बाहर हो गया है, और आपने मेमोरी-ऑप्टिमाइज़्ड टेबल और अपडेट करने योग्य कॉलमस्टोर इंडेक्स के बारे में काफी कुछ देखा होगा। हालांकि ये निश्चित रूप से ध्यान देने योग्य हैं, इस पोस्ट में मैं नए चयन का पता लगाना चाहता था ... समांतरता सुधार में। सुधार उन तैयार-पहनने वाले परिवर्तनों में से एक है, जो इसके दिखने से, इसका लाभ उठाने के लिए महत्वपूर्ण कोड परिवर्तनों की आवश्यकता नहीं होगी। मेरे अन्वेषण संस्करण Microsoft SQL Server 2014 (CTP1) - 11.0.9120.5 (X64), एंटरप्राइज़ मूल्यांकन संस्करण का उपयोग करके किए गए थे।
समानांतर चयन ... में
SQL सर्वर 2014 समानांतर-सक्षम SELECT ... INTO . का परिचय देता है डेटाबेस के लिए और इस सुविधा का परीक्षण करने के लिए मैंने AdventureWorksDW2012 डेटाबेस और FactInternetSales तालिका के एक संस्करण का उपयोग किया जिसमें 61,847,552 पंक्तियाँ थीं (मैं उन पंक्तियों को जोड़ने के लिए जिम्मेदार था; वे डिफ़ॉल्ट रूप से डेटाबेस के साथ नहीं आती हैं)।
क्योंकि इस सुविधा के लिए, CTP1 के रूप में, डेटाबेस संगतता स्तर 110 की आवश्यकता है, परीक्षण उद्देश्यों के लिए मैंने डेटाबेस को संगतता स्तर 100 पर सेट किया और अपने पहले परीक्षण के लिए निम्नलिखित क्वेरी निष्पादित की:
चुनें [ProductKey], [OrderDateKey], [DueDateKey], [ShipDateKey], [CustomerKey], [PromotionKey], [CurrencyKey], [SalesTerritoryKey], [SalesOrderNumber], [SalesOrderLineNumber], [RevisionNumberity], [OrderQuantity] ], [UnitPrice], [ExtendedAmount], [UnitPriceDiscountPct], [DiscountAmount], [ProductStandardCost], [TotalProductCost], [SalesAmount], [TaxAmt], [Freight], [CarrierTrackingNumber], [CustomerPONumber], [ऑर्डरडेट] [ड्यू डेट], [शिपडेट] डीबीओ में.FactInternetSales_V2FROM dbo.FactInternetSales;
मेरे परीक्षण VM पर क्वेरी निष्पादन अवधि 3 मिनट और 19 सेकंड थी और वास्तविक क्वेरी निष्पादन योजना इस प्रकार थी:

SQL सर्वर ने एक सीरियल प्लान का उपयोग किया, जैसा कि मुझे उम्मीद थी। यह भी ध्यान दें कि मेरी तालिका में एक गैर-संकुलित कॉलमस्टोर इंडेक्स था जिसे स्कैन किया गया था (मैंने अन्य परीक्षणों के साथ उपयोग के लिए इस गैर-क्लस्टर किए गए कॉलमस्टोर इंडेक्स को बनाया है, लेकिन मैं आपको बाद में भी क्लस्टर्ड कॉलमस्टोर इंडेक्स क्वेरी निष्पादन योजना दिखाऊंगा)। योजना ने समानांतरवाद का उपयोग नहीं किया और कॉलमस्टोर इंडेक्स स्कैन ने बैच निष्पादन मोड के बजाय पंक्ति निष्पादन मोड का उपयोग किया।
इसके बाद, मैंने डेटाबेस संगतता स्तर को संशोधित किया (और ध्यान दें कि अभी तक CTP1 में SQL Server 2014 संगतता स्तर नहीं है):
उपयोग [मास्टर];GOALTER DATABASE [AdventureWorksDW2012] SET COMPATIBILITY_LEVEL =110;GO
मैंने FactInternetSales_V2 तालिका को छोड़ दिया और फिर अपना मूल SELECT ... INTO पुनः निष्पादित किया कार्यवाही। इस बार क्वेरी निष्पादन अवधि 1 मिनट 7 सेकंड थी और वास्तविक क्वेरी निष्पादन योजना इस प्रकार थी:
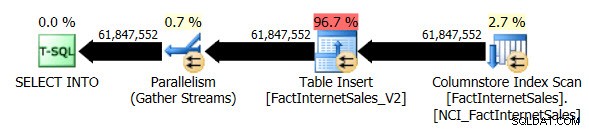
अब हमारे पास एक समानांतर योजना है और मुझे केवल वही परिवर्तन करना था जो एडवेंचरवर्क्सडीडब्ल्यू2012 के लिए डेटाबेस संगतता स्तर पर था। मेरे परीक्षण VM में चार vCPU आवंटित किए गए हैं, और क्वेरी निष्पादन योजना ने चार थ्रेड्स में पंक्तियों को वितरित किया है:

गैर-संकुलित कॉलमस्टोर इंडेक्स स्कैन, समानांतरवाद का उपयोग करते हुए, बैच निष्पादन मोड का उपयोग नहीं करता है। इसके बजाय यह पंक्ति निष्पादन मोड का उपयोग करता है।
यहाँ अब तक के परीक्षा परिणाम दिखाने के लिए एक तालिका है:
| स्कैन प्रकार | संगतता स्तर | समानांतर चयन ... में | निष्पादन मोड | <थ>अवधि|
|---|---|---|---|---|
| गैर-संकुलित Columnstore अनुक्रमणिका स्कैन | 100 | नहीं | पंक्ति | 3:19 |
| गैर-संकुलित Columnstore अनुक्रमणिका स्कैन | 110 | हां | पंक्ति | 1:07 |
इसलिए अगले परीक्षण के रूप में, मैंने गैर-क्लस्टर किए गए कॉलमस्टोर इंडेक्स को छोड़ दिया और SELECT ... INTO को फिर से निष्पादित किया। डेटाबेस संगतता स्तर 100 और 110 दोनों का उपयोग करके क्वेरी।
संगतता स्तर 100 परीक्षण को चलने में 5 मिनट और 44 सेकंड का समय लगा, और निम्नलिखित योजना तैयार की गई:
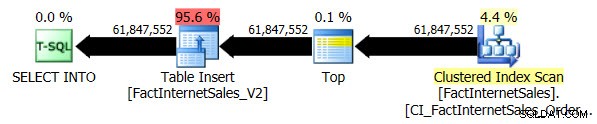
सीरियल क्लस्टर इंडेक्स स्कैन सीरियल नॉनक्लस्टर्ड कॉलमस्टोर इंडेक्स स्कैन की तुलना में 2 मिनट 25 सेकंड अधिक समय लेता है।
संगतता स्तर 110 का उपयोग करते हुए, क्वेरी को चलने में 1 मिनट 55 सेकंड का समय लगा, और निम्न योजना तैयार की गई:

समानांतर गैर-क्लस्टर किए गए कॉलमस्टोर इंडेक्स स्कैन टेस्ट के समान, समानांतर क्लस्टर्ड इंडेक्स स्कैन चार थ्रेड्स में पंक्तियों को वितरित करता है:
निम्न तालिका इन दो उपर्युक्त परीक्षणों का सार प्रस्तुत करती है:
| स्कैन प्रकार | संगतता स्तर | समानांतर चयन ... में | निष्पादन मोड | <थ>अवधि|
|---|---|---|---|---|
| संकुल अनुक्रमणिका स्कैन | 100 | नहीं | पंक्ति (N/A) | 5:44 |
| संकुल अनुक्रमणिका स्कैन | 110 | हां | पंक्ति (N/A) | 1:55 |
तो फिर मैंने क्लस्टर्ड कॉलमस्टोर इंडेक्स (एसक्यूएल सर्वर 2014 में नया) के प्रदर्शन के बारे में सोचा, इसलिए मैंने मौजूदा इंडेक्स को छोड़ दिया और फैक्टइंटरनेटसेल्स टेबल पर क्लस्टर्ड कॉलमस्टोर इंडेक्स बनाया। क्लस्टर्ड कॉलमस्टोर इंडेक्स बनाने से पहले मुझे टेबल पर परिभाषित आठ अलग-अलग विदेशी कुंजी बाधाओं को भी छोड़ना पड़ा।
चर्चा कुछ हद तक अकादमिक हो जाती है, क्योंकि मैं तुलना कर रहा हूं SELECT ... INTO डेटाबेस संगतता स्तरों पर प्रदर्शन जो पहले स्थान पर क्लस्टर्ड कॉलमस्टोर इंडेक्स की पेशकश नहीं करता था - न ही डेटाबेस संगतता स्तर 100 पर गैर-क्लस्टर किए गए कॉलमस्टोर इंडेक्स के लिए पहले के परीक्षण - और फिर भी समग्र प्रदर्शन विशेषताओं को देखना और तुलना करना दिलचस्प है।
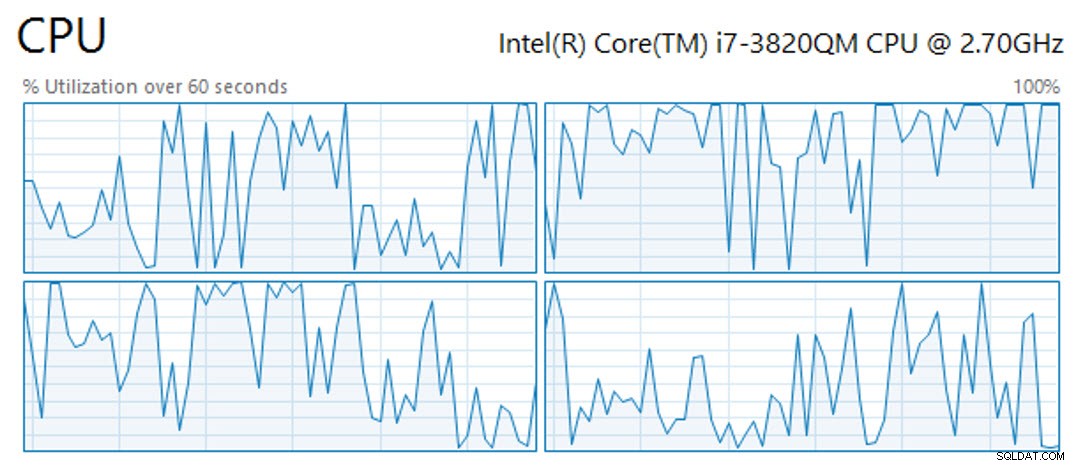
एक तरफ, 61,847,552 मिलियन पंक्ति तालिका पर क्लस्टर्ड कॉलमस्टोर इंडेक्स बनाने के ऑपरेशन में चार उपलब्ध वीसीपीयू (जिनमें से ऑपरेशन ने उन सभी का लाभ उठाया), 4 जीबी रैम और ओसीजेड वर्टेक्स एसएसडी पर वर्चुअल गेस्ट स्टोरेज के साथ 11 मिनट और 25 सेकंड का समय लिया। उस समय के दौरान CPU को पूरे समय नहीं लगाया गया था, बल्कि चोटियों और घाटियों को प्रदर्शित किया गया था (नीचे दिखाए गए CPU गतिविधि के 60 सेकंड का एक नमूना):
क्लस्टर्ड कॉलमस्टोर इंडेक्स बनने के बाद, मैंने दो SELECT ... INTO को फिर से निष्पादित किया परीक्षण। संगतता स्तर 100 परीक्षण को चलने में 3 मिनट और 22 सेकंड का समय लगा, और योजना अपेक्षित रूप से एक धारावाहिक थी (मैं SQL सर्वर 2014 CTP1 के रूप में क्लस्टर किए गए कॉलमस्टोर इंडेक्स स्कैन के बाद से योजना का SQL सर्वर प्रबंधन स्टूडियो संस्करण दिखा रहा हूं। , अभी तक प्लान एक्सप्लोरर द्वारा पूरी तरह से मान्यता प्राप्त नहीं है):

इसके बाद मैंने डेटाबेस संगतता स्तर को 110 में बदल दिया और परीक्षण को फिर से चलाया, जिसमें इस बार क्वेरी में 1 मिनट और 11 सेकंड लगे और निम्नलिखित वास्तविक निष्पादन योजना थी:

योजना ने चार थ्रेड्स में पंक्तियों को वितरित किया, और गैर-क्लस्टर किए गए कॉलमस्टोर इंडेक्स की तरह, क्लस्टर्ड कॉलमस्टोर इंडेक्स स्कैन का निष्पादन मोड पंक्ति था और बैच नहीं।
निम्न तालिका इस पोस्ट के भीतर सभी परीक्षणों को सारांशित करती है (अवधि के क्रम में, निम्न से उच्च):
| स्कैन प्रकार | संगतता स्तर | समानांतर चयन ... में | निष्पादन मोड | <थ>अवधि|
|---|---|---|---|---|
| गैर-संकुलित Columnstore अनुक्रमणिका स्कैन | 110 | हां | पंक्ति | 1:07 |
| क्लस्टर किए गए कॉलमस्टोर इंडेक्स स्कैन | 110 | हां | पंक्ति | 1:11 |
| संकुल अनुक्रमणिका स्कैन | 110 | हां | पंक्ति (N/A) | 1:55 |
| गैर-संकुलित Columnstore अनुक्रमणिका स्कैन | 100 | नहीं | पंक्ति | 3:19 |
| क्लस्टर किए गए कॉलमस्टोर इंडेक्स स्कैन | 100 | नहीं | पंक्ति | 3:22 |
| संकुल अनुक्रमणिका स्कैन | 100 | नहीं | पंक्ति (N/A) | 5:44 |
कुछ अवलोकन:
- मुझे यकीन नहीं है कि समानांतर के बीच का अंतर
SELECT ... INTOएक गैर-क्लस्टर किए गए कॉलमस्टोर इंडेक्स बनाम क्लस्टर्ड कॉलमस्टोर इंडेक्स के खिलाफ ऑपरेशन सांख्यिकीय रूप से महत्वपूर्ण है। मुझे और परीक्षण करने की आवश्यकता होगी, लेकिन मुझे लगता है कि मैं RTM तक उन्हें करने के लिए प्रतीक्षा करूंगा। - मैं सुरक्षित रूप से कह सकता हूं कि समानांतर
SELECT ... INTOक्लस्टर इंडेक्स, गैर-क्लस्टर किए गए कॉलमस्टोर और क्लस्टर्ड कॉलमस्टोर इंडेक्स टेस्ट में सीरियल समकक्षों से बेहतर प्रदर्शन किया।
यह उल्लेखनीय है कि ये परिणाम उत्पाद के सीटीपी संस्करण के लिए हैं, और मेरे परीक्षणों को कुछ ऐसी चीज के रूप में देखा जाना चाहिए जो आरटीएम द्वारा व्यवहार में बदलाव कर सके - इसलिए मुझे स्टैंडअलोन अवधियों में कम दिलचस्पी थी बनाम सीरियल और समानांतर के बीच की तुलना में उन अवधियों की तुलना में मुझे कम दिलचस्पी थी शर्तें।
कुछ प्रदर्शन सुविधाओं के लिए महत्वपूर्ण रीफैक्टरिंग की आवश्यकता होती है - लेकिन SELECT ... INTO . के लिए सुधार, मुझे बस इतना करना था कि लाभ देखना शुरू करने के लिए डेटाबेस संगतता स्तर को ऊपर उठाना था, जो निश्चित रूप से कुछ ऐसा है जिसकी मैं सराहना करता हूं।



