संक्षिप्त सारांश
- सबक्वायरी विधि का प्रदर्शन डेटा वितरण पर निर्भर करता है।
- सशर्त एकत्रीकरण का प्रदर्शन डेटा वितरण पर निर्भर नहीं करता है।
सबक्वेरी विधि सशर्त एकत्रीकरण की तुलना में तेज़ या धीमी हो सकती है, यह डेटा वितरण पर निर्भर करती है।
स्वाभाविक रूप से, यदि तालिका में एक उपयुक्त सूचकांक है, तो उपश्रेणियों को इससे लाभ होने की संभावना है, क्योंकि सूचकांक पूर्ण स्कैन के बजाय तालिका के केवल प्रासंगिक भाग को स्कैन करने की अनुमति देगा। एक उपयुक्त सूचकांक होने से सशर्त एकत्रीकरण विधि को महत्वपूर्ण रूप से लाभ होने की संभावना नहीं है, क्योंकि यह वैसे भी पूर्ण सूचकांक को स्कैन करेगा। एकमात्र लाभ यह होगा कि यदि सूचकांक तालिका से संकरा है और इंजन को मेमोरी में कम पृष्ठ पढ़ने होंगे।
यह जानकर आप तय कर सकते हैं कि कौन सा तरीका चुनना है।
पहला परीक्षण
मैंने 5M पंक्तियों के साथ एक बड़ी परीक्षण तालिका बनाई। मेज पर कोई अनुक्रमणिका नहीं थी। मैंने SQL संतरी योजना एक्सप्लोरर का उपयोग करके IO और CPU आँकड़ों को मापा। मैंने इन परीक्षणों के लिए SQL Server 2014 SP1-CU7 (12.0.4459.0) एक्सप्रेस 64-बिट का उपयोग किया।
वास्तव में, आपके मूल प्रश्नों ने जैसा आपने वर्णन किया है वैसा ही व्यवहार किया, अर्थात उपश्रेणियाँ तेज़ थीं, भले ही पठन 3 गुना अधिक था।
इंडेक्स के बिना टेबल पर कुछ कोशिशों के बाद मैंने DATEADD का मान रखने के लिए आपके कंडीशनल एग्रीगेट और जोड़े गए वैरिएबल को फिर से लिखा भाव।
कुल मिलाकर समय काफी तेज हो गया।
फिर मैंने SUM . को बदल दिया COUNT . के साथ और यह फिर से थोड़ा तेज हो गया।
आखिरकार, सशर्त एकत्रीकरण सबक्वेरी जितना तेज़ हो गया।
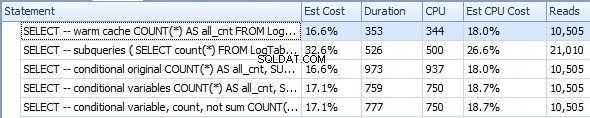
कैश को गर्म करें (सीपीयू=375)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
उपश्रेणियां (सीपीयू=1031)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-1,GETDATE())
) last_year_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-10,GETDATE())
) last_ten_year_cnt
OPTION (RECOMPILE);
मूल सशर्त एकत्रीकरण (सीपीयू=1641)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-1,GETDATE())
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-10,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
चर के साथ सशर्त एकत्रीकरण (सीपीयू=1078)
DECLARE @VarYear1 datetime = DATEADD(year,-1,GETDATE());
DECLARE @VarYear10 datetime = DATEADD(year,-10,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear1
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > @VarYear10
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
चर के साथ सशर्त एकत्रीकरण और SUM के बजाय COUNT (सीपीयू=1062)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear1
THEN 1 ELSE NULL END) AS last_year_cnt,
COUNT(CASE WHEN datesent > @VarYear10
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);

इन परिणामों के आधार पर मेरा अनुमान है कि CASE लागू किया गया DATEADD प्रत्येक पंक्ति के लिए, जबकि WHERE एक बार इसकी गणना करने के लिए पर्याप्त स्मार्ट था। साथ ही COUNT SUM . से थोड़ा अधिक कुशल है ।
अंत में, सशर्त एकत्रीकरण सबक्वेरी (1062 बनाम 1031) की तुलना में केवल थोड़ा धीमा है, शायद इसलिए कि WHERE CASE . से थोड़ा अधिक कुशल है अपने आप में, और इसके अलावा, WHERE कुछ पंक्तियों को फ़िल्टर कर देता है, इसलिए COUNT कम पंक्तियों को संसाधित करना पड़ता है।
व्यवहार में मैं सशर्त एकत्रीकरण का उपयोग करूंगा, क्योंकि मुझे लगता है कि पढ़ने की संख्या अधिक महत्वपूर्ण है। यदि आपकी टेबल फिट होने के लिए छोटी है और बफर पूल में रहती है, तो अंतिम उपयोगकर्ता के लिए कोई भी प्रश्न तेज होगा। लेकिन, यदि तालिका उपलब्ध मेमोरी से बड़ी है, तो मुझे उम्मीद है कि डिस्क से पढ़ने से सबक्वेरी काफी धीमी हो जाएगी।
दूसरा परीक्षण
दूसरी ओर, जितनी जल्दी हो सके पंक्तियों को फ़िल्टर करना भी महत्वपूर्ण है।
यहां परीक्षण की थोड़ी भिन्नता है, जो इसे प्रदर्शित करती है। यह सुनिश्चित करने के लिए कि कोई भी पंक्ति फ़िल्टर मानदंड को पूरा नहीं करती है, यहां मैंने सीमा को GETDATE() + 100 वर्ष निर्धारित किया है।
कैश को गर्म करें (सीपीयू=344)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
उपश्रेणियां (सीपीयू=500)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,100,GETDATE())
) last_year_cnt
OPTION (RECOMPILE);
मूल सशर्त एकत्रीकरण (सीपीयू=937)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,100,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
चर के साथ सशर्त एकत्रीकरण (सीपीयू=750)
DECLARE @VarYear100 datetime = DATEADD(year,100,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear100
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
चर के साथ सशर्त एकत्रीकरण और SUM के बजाय COUNT (सीपीयू=750)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear100
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
नीचे उपश्रेणियों के साथ एक योजना है। आप देख सकते हैं कि दूसरी सबक्वेरी में 0 पंक्तियाँ स्ट्रीम एग्रीगेट में चली गईं, उन सभी को टेबल स्कैन चरण में फ़िल्टर कर दिया गया।
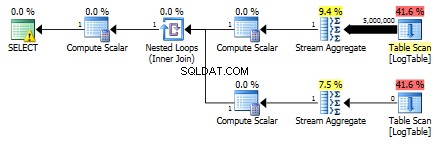
नतीजतन, सबक्वेरी फिर से तेज हो जाती हैं।
तीसरा परीक्षण
यहां मैंने पिछले परीक्षण के फ़िल्टरिंग मानदंड को बदल दिया:सभी > < . से बदल दिया गया . परिणामस्वरूप, सशर्त COUNT सभी पंक्तियों के बजाय कोई नहीं गिना। अचंभा अचंभा! सशर्त एकत्रीकरण क्वेरी में समान 750 ms लगे, जबकि सबक्वेरी 500 के बजाय 813 हो गईं।

यहां सबक्वायरी की योजना है:
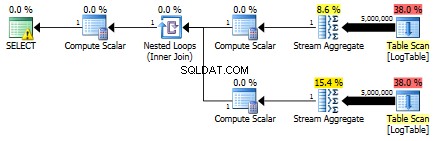
क्या आप मुझे एक उदाहरण दे सकते हैं, जहां सशर्त एकत्रीकरण विशेष रूप से सबक्वेरी समाधान से बेहतर प्रदर्शन करता है?
यही पर है। सबक्वेरी पद्धति का प्रदर्शन डेटा वितरण पर निर्भर करता है। सशर्त एकत्रीकरण का प्रदर्शन डेटा वितरण पर निर्भर नहीं करता है।
सशर्त एकत्रीकरण की तुलना में सबक्वेरी विधि तेज या धीमी हो सकती है, यह डेटा वितरण पर निर्भर करता है।
यह जानकर आप तय कर सकते हैं कि कौन सा तरीका चुनना है।
बोनस विवरण
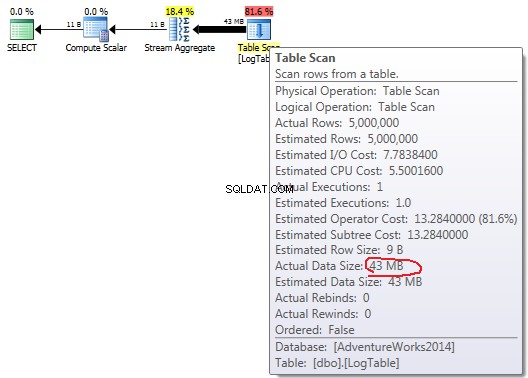
यदि आप माउस को Table Scan के ऊपर मँडराते हैं ऑपरेटर आप देख सकते हैं Actual Data Size विभिन्न रूपों में।
- साधारण
COUNT(*):
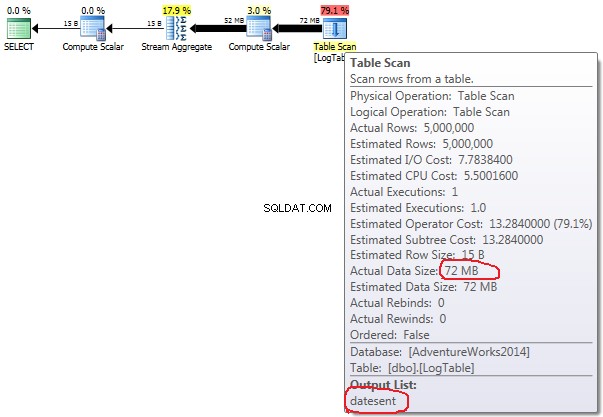
- सशर्त एकत्रीकरण:
- टेस्ट 2 में सबक्वेरी:
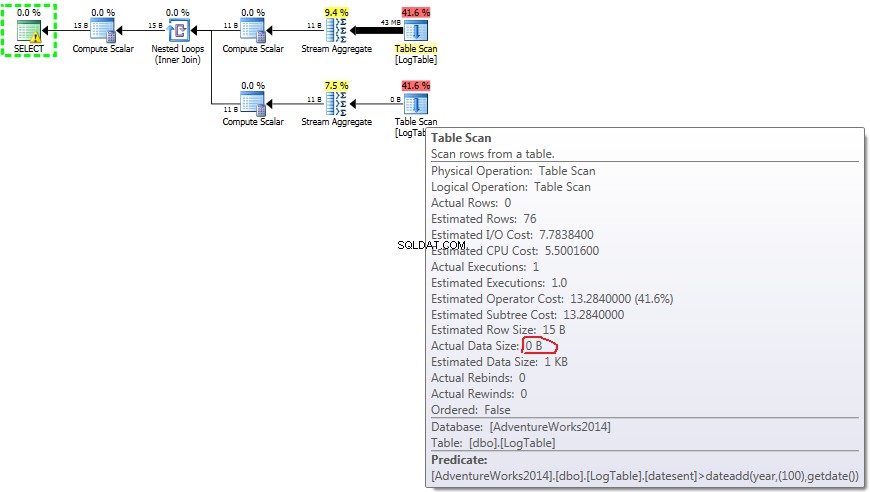
- टेस्ट 3 में सबक्वेरी:
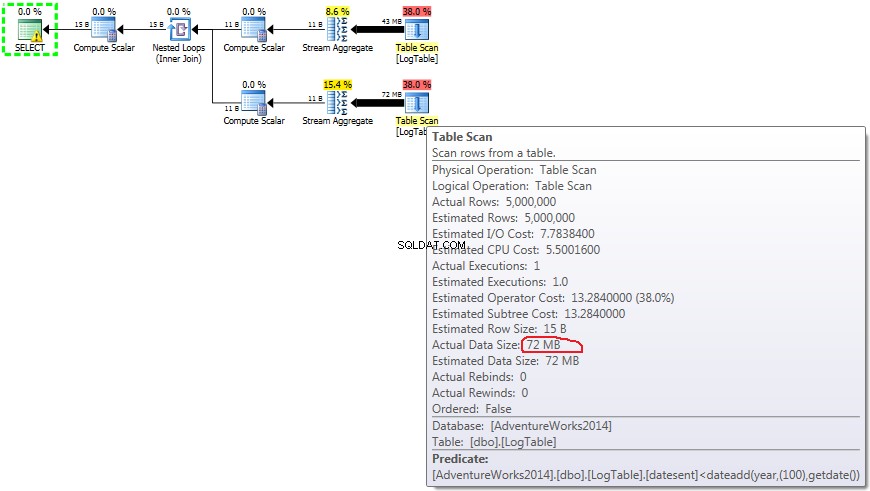
अब यह स्पष्ट हो गया है कि प्रदर्शन में अंतर योजना के माध्यम से प्रवाहित होने वाले डेटा की मात्रा में अंतर के कारण होने की संभावना है।
सरल COUNT(*) . के मामले में कोई Output list नहीं है (कोई कॉलम मान की आवश्यकता नहीं है) और डेटा का आकार सबसे छोटा (43MB) है।
सशर्त एकत्रीकरण के मामले में यह राशि परीक्षण 2 और 3 के बीच नहीं बदलती है, यह हमेशा 72MB होती है। Output list एक कॉलम है datesent ।
सबक्वेरी के मामले में, यह राशि करती है डेटा वितरण के आधार पर परिवर्तन।