मैं कैड रॉक्स से सहमत हूं।
यह लेख आपको सही रास्ते पर ले जाना चाहिए:
- एसक्यूएल सर्वर 2005/2008 में अनुक्रमणिका - सर्वोत्तम अभ्यास, भाग 1
- एसक्यूएल सर्वर 2005/2008 में अनुक्रमणिका - भाग 2 - आंतरिक
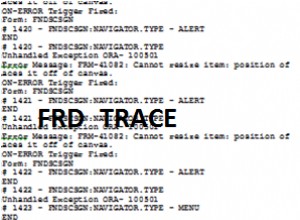
एक बात ध्यान देने योग्य है, क्लस्टर इंडेक्स में पहले कॉलम के रूप में एक अद्वितीय कुंजी (एक पहचान कॉलम जो मैं अनुशंसा करता हूं) होना चाहिए। मूल रूप से यह इंडेक्स के अंत में आपके डेटा को सम्मिलित करने में मदद करता है और बहुत सारे डिस्क आईओ और पेज स्प्लिट का कारण नहीं बनता है।
दूसरे, यदि आप अपने डेटा पर अन्य इंडेक्स बना रहे हैं और उनका निर्माण चतुराई से किया गया है तो उनका पुन:उपयोग किया जाएगा।
जैसे कल्पना कीजिए कि आप तीन स्तंभों पर एक तालिका खोजते हैं
राज्य, काउंटी, ज़िप।
- आप कभी-कभी केवल राज्य के आधार पर खोज करते हैं।
- आप कभी-कभी राज्य और काउंटी द्वारा खोजते हैं।
- आप अक्सर राज्य, काउंटी, ज़िप द्वारा खोजते हैं।
फिर राज्य, काउंटी, ज़िप के साथ एक सूचकांक। इन तीनों खोजों में उपयोग किया जाएगा।
यदि आप अकेले ज़िप द्वारा बहुत अधिक खोज करते हैं तो उपरोक्त अनुक्रमणिका का उपयोग नहीं किया जाएगा (वैसे भी SQL सर्वर द्वारा) क्योंकि ज़िप उस अनुक्रमणिका का तीसरा भाग है और क्वेरी ऑप्टिमाइज़र उस अनुक्रमणिका को सहायक के रूप में नहीं देखेगा।
फिर आप अकेले Zip पर एक इंडेक्स बना सकते हैं जिसका इस उदाहरण में उपयोग किया जाएगा।
वैसे हम इस तथ्य का लाभ उठा सकते हैं कि मल्टी-कॉलम इंडेक्सिंग के साथ पहला इंडेक्स कॉलम हमेशा खोज के लिए प्रयोग योग्य होता है और जब आप केवल 'स्टेट' द्वारा खोज करते हैं तो यह कुशल होता है लेकिन फिर भी 'स्टेट' पर सिंगल-कॉलम इंडेक्स जितना कुशल नहीं होता है। '
मुझे लगता है कि आप जिस उत्तर की तलाश कर रहे हैं, वह यह है कि यह आपके द्वारा अक्सर उपयोग किए जाने वाले प्रश्नों के आपके और आपके समूह पर निर्भर करता है।
लेख बहुत मदद करेगा। :-)