ROLLUP और CUBE ऑपरेटरों का उपयोग ग्रुप बाय क्लॉज में कॉलम द्वारा एकत्रित परिणामों को वापस करने के लिए किया जाता है।
GROUPING और GROUPING_ID फ़ंक्शन का उपयोग यह पहचानने के लिए किया जाता है कि क्या GROUP BY सूची में कॉलम एकत्रित हैं (रोलअप या CUBE ऑपरेटरों का उपयोग करके) या नहीं।
GROUPING और GROUPING_ID फ़ंक्शंस के बीच दो प्रमुख अंतर हैं।
वे इस प्रकार हैं:
- ग्रुपिंग फ़ंक्शन एकल कॉलम पर लागू होता है, जबकि GROUPING_ID फ़ंक्शन के लिए कॉलम सूची को ग्रुप बाय क्लॉज में कॉलम सूची से मेल खाना चाहिए।
- ग्रुपिंग फ़ंक्शन इंगित करता है कि ग्रुप बाय सूची में एक कॉलम एकत्रित है या नहीं। यदि परिणाम सेट को समेकित किया जाता है तो यह 1 देता है, और यदि परिणाम सेट एकत्रित नहीं होता है तो यह 0 देता है।
दूसरी ओर, GROUPING_ID फ़ंक्शन भी एक पूर्णांक देता है। हालांकि, यह सभी ग्रुपिंग कार्यों के परिणाम को संयोजित करने के बाद बाइनरी से दशमलव रूपांतरण करता है।
इस लेख में, हम उदाहरणों की सहायता से GROUPING और GROUPING_ID कार्यों को कार्य करते हुए देखेंगे।
कुछ डमी डेटा तैयार करना
हमेशा की तरह, आइए कुछ डमी डेटा बनाते हैं जिसका उपयोग हम उदाहरण के लिए करने जा रहे हैं, जिसके साथ हम इस लेख में काम करेंगे।
निम्न स्क्रिप्ट निष्पादित करें:
CREATE Database company;
USE company;
CREATE TABLE employee
(
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
gender VARCHAR(50) NOT NULL,
salary INT NOT NULL,
department VARCHAR(50) NOT NULL
)
INSERT INTO employee
VALUES
(1, 'David', 'Male', 5000, 'Sales'),
(2, 'Jim', 'Female', 6000, 'HR'),
(3, 'Kate', 'Female', 7500, 'IT'),
(4, 'Will', 'Male', 6500, 'Marketing'),
(5, 'Shane', 'Female', 5500, 'Finance'),
(6, 'Shed', 'Male', 8000, 'Sales'),
(7, 'Vik', 'Male', 7200, 'HR'),
(8, 'Vince', 'Female', 6600, 'IT'),
(9, 'Jane', 'Female', 5400, 'Marketing'),
(10, 'Laura', 'Female', 6300, 'Finance'),
(11, 'Mac', 'Male', 5700, 'Sales'),
(12, 'Pat', 'Male', 7000, 'HR'),
(13, 'Julie', 'Female', 7100, 'IT'),
(14, 'Elice', 'Female', 6800,'Marketing'),
(15, 'Wayne', 'Male', 5000, 'Finance')
ऊपर की लिपि में, हमने "कंपनी" नाम का एक डेटाबेस बनाया है। हमने तब कंपनी डेटाबेस के भीतर एक टेबल "कर्मचारी" बनाया है। अंत में, हमने कर्मचारी तालिका में कुछ डमी रिकॉर्ड डाले हैं।
ग्रुपिंग फ़ंक्शन
जैसा कि ऊपर बताया गया है, अगर परिणाम सेट को समेकित किया जाता है तो ग्रुपिंग फ़ंक्शन 1 देता है, और यदि परिणाम सेट एकत्रित नहीं होता है तो 0 देता है।
ग्रुपिंग फ़ंक्शन को क्रिया में देखने के लिए निम्न स्क्रिप्ट पर एक नज़र डालें।
SELECT department AS Department, gender AS Gender, sum(salary) as Salary_Sum, GROUPING(department) as GP_Department, GROUPING(gender) as GP_Gender FROM employee GROUP BY ROLLUP (department, gender)
उपरोक्त लिपि में सभी पुरुष और महिला कर्मचारियों के वेतन का योग गिना जाता है, जिन्हें पहले विभाग कॉलम और फिर जेंडर कॉलम द्वारा समूहीकृत किया जाता है। विभाग और लिंग कॉलम पर लागू ग्रुपिंग फ़ंक्शन के परिणाम को प्रदर्शित करने के लिए दो और कॉलम जोड़े गए हैं।
ROLLUP ऑपरेटर का उपयोग वेतन के योग को कुल योग और उप-योग के रूप में प्रदर्शित करने के लिए किया जाता है।
ऊपर की स्क्रिप्ट का आउटपुट इस तरह दिखता है।
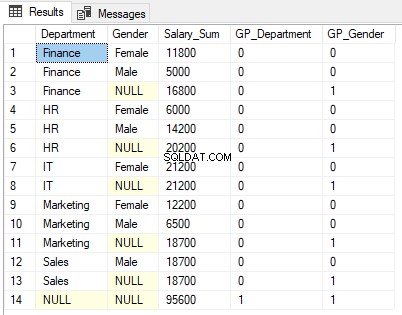
आउटपुट पर ध्यान से देखें। वेतन का योग विभाग के लिंग (पंक्तियों 1, 2, 4, 5, 7, 9, 10, और 12) द्वारा लिंग द्वारा प्रदर्शित किया जाता है। इसके बाद इसे केवल लिंग (पंक्तियों 3, 6, 8, 11, और 13) द्वारा भी एकत्रित किया जाता है। अंत में, विभाग और लिंग दोनों द्वारा एकत्रित वेतन का कुल योग पंक्ति 14 में प्रदर्शित होता है।
1 को GROUPING फ़ंक्शन कॉलम GP_Gender में उन पंक्तियों के लिए प्रदर्शित किया जाता है जहाँ परिणाम लिंग द्वारा एकत्रित किए जाते हैं अर्थात पंक्तियाँ 3, 6, 8, 11, और 13। ऐसा इसलिए है क्योंकि GP_Gender कॉलम में GROUPING फ़ंक्शन का परिणाम होता है, जो लिंग कॉलम पर लागू होता है।
इसी तरह, पंक्ति 14 में सभी विभागों और सभी स्तंभों का योग है। इसलिए GP_Department और GP_Gender दोनों कॉलम के लिए 1 लौटाया जाता है।
आप देख सकते हैं कि एनयूएलएल विभाग में प्रदर्शित होता है और आउटपुट में जेंडर कॉलम जहां परिणाम एकत्रित होते हैं। उदाहरण के लिए पंक्ति 3 में, NULL को जेंडर कॉलम में प्रदर्शित किया जाता है क्योंकि परिणाम लिंग कॉलम द्वारा एकत्रित किए जाते हैं और इसलिए प्रदर्शित करने के लिए कोई कॉलम मान नहीं होता है। हम नहीं चाहते कि हमारे उपयोगकर्ता NULL देखें, यहां एक बेहतर शब्द "सभी लिंग" हो सकता है।
ऐसा करने के लिए, हमें अपनी स्क्रिप्ट को इस प्रकार संशोधित करना होगा:
SELECT CASE WHEN GROUPING(department) = 1 THEN 'All Departments' ELSE ISNULL(department, 'Unknown') END as Department, CASE WHEN GROUPING(gender) = 1 THEN 'All Genders' ELSE ISNULL(gender, 'Unknown') END as Gender, sum(salary) as Salary_Sum FROM employee GROUP BY ROLLUP (department, gender)
उपरोक्त लिपि में, यदि विभाग कॉलम पर लागू ग्रुपिंग फ़ंक्शन 1 रिटर्न करता है और "सभी विभाग" विभाग कॉलम में प्रदर्शित होता है। अन्यथा, यदि विभाग कॉलम में NULL मान है, तो यह "अज्ञात" प्रदर्शित करेगा। लिंग कॉलम को उसी तरह संशोधित किया गया है।
उपरोक्त स्क्रिप्ट चलाने से निम्न परिणाम प्राप्त होते हैं:
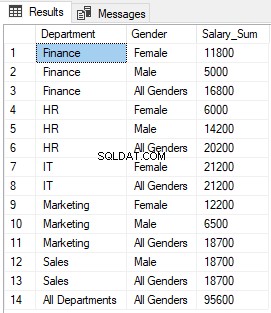
आप देख सकते हैं कि विभाग और लिंग कॉलम में जहां GROUPING फ़ंक्शन 1 देता है, NULL को क्रमशः "सभी विभाग" और "सभी लिंग" से बदल दिया गया है।
GROUPING_ID फ़ंक्शन
GROUPING_ID फ़ंक्शन GROUP BY क्लॉज़ में निर्दिष्ट सभी स्तंभों पर लागू GROUPING फ़ंक्शन के आउटपुट को संयोजित करता है। इसके बाद यह अंतिम आउटपुट को वापस करने से पहले बाइनरी से दशमलव रूपांतरण करता है।
आइए पहले विभाग और जेंडर कॉलम पर लागू ग्रुपिंग फ़ंक्शन द्वारा लौटाए गए आउटपुट को संयोजित करें। निम्नलिखित स्क्रिप्ट पर एक नज़र डालें:
USE company SELECT department AS Department, gender AS Gender, sum(salary) as Salary_Sum, CAST(GROUPING(department) AS VARCHAR(1)) + CAST(GROUPING(gender) AS VARCHAR (1)) as Grouping FROM employee GROUP BY ROLLUP (department, gender)
आउटपुट में, आप 0s और 1s को GROUPING फंक्शन द्वारा एक साथ जोड़कर लौटा हुआ देखेंगे। आउटपुट इस तरह दिखता है:
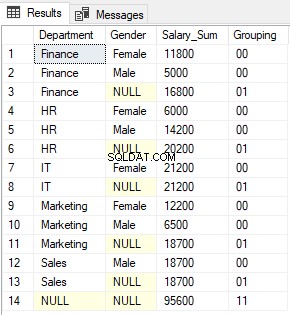
GROUPING_ID फ़ंक्शन, GROUPING फ़ंक्शन द्वारा लौटाए गए मानों के संयोजन के परिणामस्वरूप बने बाइनरी मान के दशमलव समतुल्य को केवल लौटाता है।
ग्रुपिंग आईडी फ़ंक्शन को क्रिया में देखने के लिए निम्न स्क्रिप्ट निष्पादित करें:
USE company SELECT department AS Department, gender AS Gender, sum(salary) as Salary_Sum, CAST(GROUPING(department) AS VARCHAR(1)) + CAST(GROUPING(gender) AS VARCHAR (1)) as Grouping, GROUPING_ID(department, gender) as Grouping_Id FROM employee GROUP BY ROLLUP (department, gender)
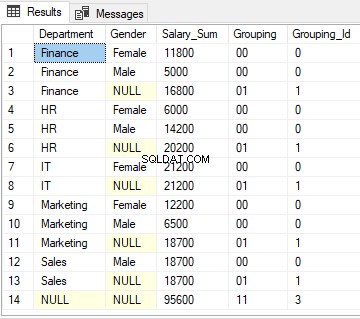
पंक्ति 1 के लिए, ग्रुपिंग आईडी फ़ंक्शन 0 लौटाएगा क्योंकि '00' का दशमलव समतुल्य शून्य है।
3, 6, 8, 11 और 13 पंक्तियों के लिए, GROUPING_ID फ़ंक्शन 1 लौटाता है क्योंकि '01' का दशमलव समतुल्य 1 है।
अंत में, पंक्ति 14 के लिए, GROUPIND_ID फ़ंक्शन 3 लौटाता है, क्योंकि '11' का बाइनरी समतुल्य 3 है।
ऊपर की स्क्रिप्ट का आउटपुट इस तरह दिखता है:
यह भी देखें:
माइक्रोसॉफ्ट:Grouping_ID अवलोकन
माइक्रोसॉफ्ट:ग्रुपिंग ओवरव्यू
यूट्यूब:ग्रुपिंग और ग्रुपिंग_आईडी