क्या आपने क्लाइंट को सर्वर से अलग मशीन में विभाजित किया है? स्केलिंग में यह पहला, छोटा, कदम है।
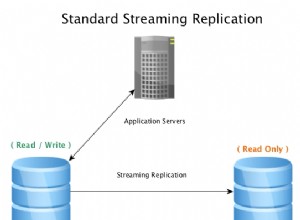
क्या आपके पास दासों को भेजे गए प्रतिकृति और केवल पढ़ने के लिए प्रश्न हैं? यह असीमित पढ़ने . की अनुमति दे सकता है स्केलिंग। (लेकिन यह मास्टर पर भार को हल्का करने के अलावा अद्यतन प्रश्न को संबोधित नहीं करता है।)
एकल, कताई, डिस्क पर 115 IOP इसे बहुत अधिक संतृप्त करेंगे। innodb_flush_log_at_trx_commit डिफ़ॉल्ट रूप से 1 हो जाता है, जिससे प्रति लेन-देन कम से कम 1 IOP हो जाता है। कुछ अस्थायी समाधान (जब तक कि आपका ट्रैफ़िक और 10 गुना बढ़ न जाए)...
SSDs -- शायद 1000 IOPs।
अपडेट बैच करें (जैसे @N. B. द्वारा उल्लिखित) यह "फ्लश" की संख्या में 100 गुना की कटौती करता है।
innodb_flush_log_at_trx_commit =2 -- वस्तुतः फ्लश को समाप्त करने के लिए (सुरक्षा के कुछ नुकसान पर)।
लेकिन -- भले ही आप अद्यतनों को काफी तेजी से कर सकें, क्या आपको मूल्यों को पढ़ने की भी आवश्यकता नहीं है? यानी विवाद होगा। समान . पर कितने चयन टेबल कर रहे हो? 100/सेकंड ठीक हो सकता है; 1000/सेकंड से इतना अधिक व्यवधान उत्पन्न हो सकता है कि यह काम नहीं करेगा।
टेबल कितनी बड़ी है? इनमें से किसी के भी काम करने के लिए, इसे इतना छोटा होना चाहिए कि इसे हर समय कैश किया जा सके।
Reddit एक और तरीका है - वहां अपडेट कैप्चर करें। फिर संचित गणनाओं को लगातार बाहर निकालें और आवश्यक अद्यतन करें।
Sharding -- यह वह जगह है जहाँ आप डेटा को कई मशीनों में विभाजित करते हैं। उपयोगकर्ता आईडी के हैश या लुकअप (या दोनों का कॉम्बो) पर बंटवारा आम है। फिर UPDATE को यह पता लगाने की जरूरत है कि किस मशीन को अपडेट करना है, फिर वहां कार्रवाई करें। यदि आपके पास 10 शार्प (मशीनें) हैं, तो आप अद्यतन दर से लगभग 10 गुना अधिक बनाए रख सकते हैं। अंततः, यही एकमात्र तरीका है जिससे सभी भारी हिटर 100M+ उपयोगकर्ताओं और अरबों प्रश्नों/दिनों को संभाल सकते हैं।
विभाजन से मदद मिलने की संभावना नहीं है। इस तरह की एक छोटी सी क्वेरी के लिए बहुत अधिक ओवरहेड से बचने के लिए विभाजन प्रूनिंग कोड अभी तक पर्याप्त कुशल नहीं है।