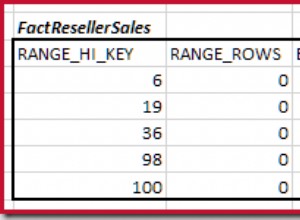
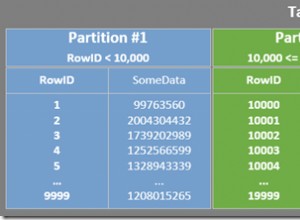
यह इस बात पर निर्भर करता है कि विभाजित तालिका में पंक्तियों का आकार किस हद तक विभाजन के आवश्यक होने का कारण है।
यदि पंक्ति का आकार छोटा है और विभाजन का कारण सरासर संख्या . है पंक्तियों का, तो मुझे नहीं पता कि आपको क्या करना चाहिए।
यदि पंक्ति का आकार काफी बड़ा है, तो क्या आपने निम्नलिखित पर विचार किया है:
चलो P विभाजित तालिका हो और F होने वाली विदेशी कुंजी में संदर्भित तालिका बनें। एक नई तालिका बनाएं X :
CREATE TABLE `X` (
`P_id` INT UNSIGNED NOT NULL,
-- I'm assuming an INT is adequate, but perhaps
-- you will actually require a BIGINT
`F_id` INT UNSIGNED NOT NULL,
PRIMARY KEY (`P_id`, `F_id`),
CONSTRAINT `Constr_X_P_fk`
FOREIGN KEY `P_fk` (`P_id`) REFERENCES `P`.`id`
ON DELETE CASCADE ON UPDATE RESTRICT,
CONSTRAINT `Constr_X_F_fk`
FOREIGN KEY `F_fk` (`F_id`) REFERENCES `F`.`id`
ON DELETE RESTRICT ON UPDATE RESTRICT
) ENGINE=INNODB CHARACTER SET ascii COLLATE ascii_general_ci
और महत्वपूर्ण रूप से, तालिका में पंक्तियों को जोड़ने के लिए एक संग्रहीत कार्यविधि बनाएं P . आपकी संग्रहीत प्रक्रिया को निश्चित करना चाहिए (लेन-देन का उपयोग करें) कि जब भी कोई पंक्ति तालिका में जोड़ी जाती है P , एक संगत पंक्ति को तालिका X . में जोड़ा जाता है . आपको P . में पंक्तियों को जोड़ने की अनुमति नहीं देनी चाहिए "सामान्य" तरीके से! आप केवल गारंटी दे सकते हैं कि यदि आप पंक्तियों को जोड़ने के लिए अपनी संग्रहीत प्रक्रिया का उपयोग करना जारी रखते हैं तो संदर्भात्मक अखंडता बनी रहेगी। आप P . से स्वतंत्र रूप से हटा सकते हैं हालांकि सामान्य तरीके से।
यहाँ विचार यह है कि आपकी तालिका X पर्याप्त रूप से छोटी पंक्तियाँ हैं जिन्हें आपको उम्मीद है कि इसे विभाजित करने की आवश्यकता नहीं है, भले ही इसमें कई पंक्तियाँ हों। मुझे लगता है कि टेबल पर मौजूद इंडेक्स मेमोरी का काफी बड़ा हिस्सा लेगा।
क्या आपको P से पूछताछ करने की आवश्यकता है? विदेशी कुंजी पर, आप निश्चित रूप से X query को क्वेरी करेंगे इसके बजाय, जैसा कि वास्तव में विदेशी कुंजी है।