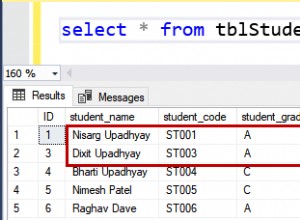
हां यह अलग होना चाहिए - (1) तेज होने की उम्मीद है।
यह सुनिश्चित करने के बाद कि पहले मुख्य क्वेरी चलाई जाती है और फिर फ़िल्टर लागू किया जाता है - इसलिए यह मूल रूप से (क्वेरी माइनस वाले) द्वारा लौटाए गए डेटासेट पर काम करता है।
पहली क्वेरी बेहतर होनी चाहिए, क्योंकि यह उन रिकॉर्ड्स को बिल्कुल भी नहीं चुनती है।