अनुपस्थित विंडो फ़ंक्शन, आप tbl ऑर्डर कर सकते हैं और अपने विभाजन ("तारीख" मान) पर रैंक की गणना करने के लिए उपयोगकर्ता चर का उपयोग स्वयं करें:
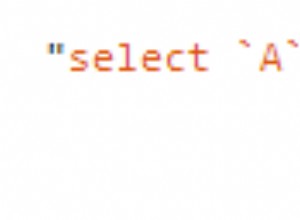
SELECT "date", -- D) Desired columns
id,
value,
rank
FROM (SELECT "date", -- C) Rank by date
id,
value,
CASE COALESCE(@partition, "date")
WHEN "date" THEN @rank := @rank + 1
ELSE @rank := 1
END AS rank,
@partition := "date" AS dummy
FROM (SELECT @rank := 0 AS rank, -- A) User var init
@partition := NULL AS partition) dummy
STRAIGHT_JOIN
( SELECT "date", -- B) Ordering query
id,
value
FROM tbl
ORDER BY date, value) tbl_ordered;
अपडेट करें
तो, वह क्वेरी क्या कर रही है?
हम उपयोगकर्ता चर का उपयोग कर रहे हैं एक क्रमबद्ध परिणाम सेट के माध्यम से "लूप" करने के लिए, एक काउंटर को बढ़ाना या रीसेट करना (@rank ) परिणाम सेट के किस सन्निहित खंड पर निर्भर करता है (@partition . में ट्रैक किया गया ) हम अंदर हैं।
क्वेरी में A हम दो उपयोगकर्ता चर प्रारंभ करते हैं। क्वेरी में B हमें आपकी तालिका के रिकॉर्ड उस क्रम में मिलते हैं जिसकी हमें आवश्यकता होती है:पहले तिथि के अनुसार और फिर मूल्य के अनुसार। ए और बी एक साथ एक व्युत्पन्न तालिका बनाएं, tbl_ordered , जो कुछ इस तरह दिखता है:
rank | partition | "date" | id | value
---- + --------- + ------ + ---- + -----
0 | NULL | d1 | id2 | 1
0 | NULL | d1 | id1 | 2
0 | NULL | d2 | id1 | 10
0 | NULL | d2 | id2 | 11
याद रखें, हम वास्तव में dummy.rank कॉलमों की परवाह नहीं करते हैं और dummy.partition - वे सिर्फ इस बात की दुर्घटना हैं कि हम वेरिएबल्स को कैसे प्रारंभ करते हैं @rank और @partition ।
क्वेरी में सी हम व्युत्पन्न तालिका के रिकॉर्ड के माध्यम से लूप करते हैं। हम जो कर रहे हैं वह कमोबेश वही है जो निम्न स्यूडोकोड करता है:
rank = 0
partition = nil
foreach row in fetch_rows(sorted_query):
(date, id, value) = row
if partition is nil or partition == date:
rank += 1
else:
rank = 1
partition = date
stdout.write(date, id, value, rank, partition)
अंत में, क्वेरी D C . के सभी कॉलम प्रोजेक्ट करता है छोड़कर @partition वाले कॉलम के लिए (जिसे हमने dummy . नाम दिया है और प्रदर्शित करने की आवश्यकता नहीं है)।