शुद्ध BigQuery (मानक SQL) के साथ अपने कार्य को हल करने के विकल्प के साथ कूदना चाहता था
पूर्वापेक्षाएँ / धारणाएँ :स्रोत डेटा sandbox.temp.id1_id2_pairs . में है
आपको इसे अपने से बदलना चाहिए या यदि आप अपने प्रश्न के डमी डेटा के साथ परीक्षण करना चाहते हैं - आप नीचे इस तालिका को बना सकते हैं (बेशक sandbox.temp को बदलें अपने स्वयं के project.dataset . के साथ )
सुनिश्चित करें कि आपने संबंधित गंतव्य तालिका सेट की है
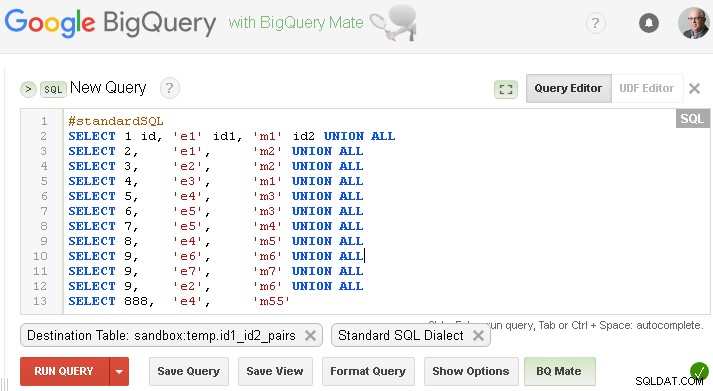
नोट :आप इस उत्तर के नीचे सभी संबंधित प्रश्न (पाठ के रूप में) पा सकते हैं, लेकिन अभी के लिए मैं स्क्रीनशॉट के साथ अपना उत्तर दिखा रहा हूं - इसलिए सभी प्रस्तुत किए गए हैं - क्वेरी, परिणाम और उपयोग किए गए विकल्प
तो, तीन चरण होंगे:
चरण 1 - आरंभीकरण
यहां, हम id2 के कनेक्शन के आधार पर id1 का प्रारंभिक समूहीकरण करते हैं:
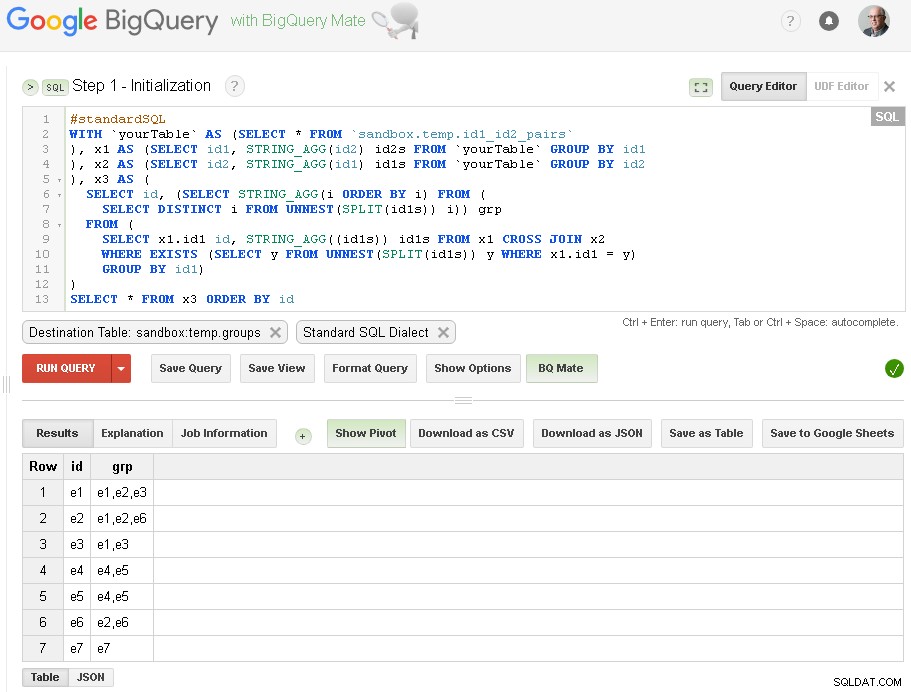
जैसा कि आप यहां देख सकते हैं - हमने id2 के माध्यम से सरल एक-स्तरीय कनेक्शन के आधार पर संबंधित कनेक्शन के साथ सभी id1 मानों की सूची बनाई है
आउटपुट टेबल sandbox.temp.groups है
चरण 2 - पुनरावृत्तियों को समूहीकृत करना
प्रत्येक पुनरावृत्ति में हम पहले से स्थापित समूहों के आधार पर समूहीकरण को समृद्ध करेंगे।
क्वेरी का स्रोत पिछले चरण की आउटपुट तालिका है (sandbox.temp.groups ) और गंतव्य एक ही तालिका है (sandbox.temp.groups ) ओवरराइट के साथ
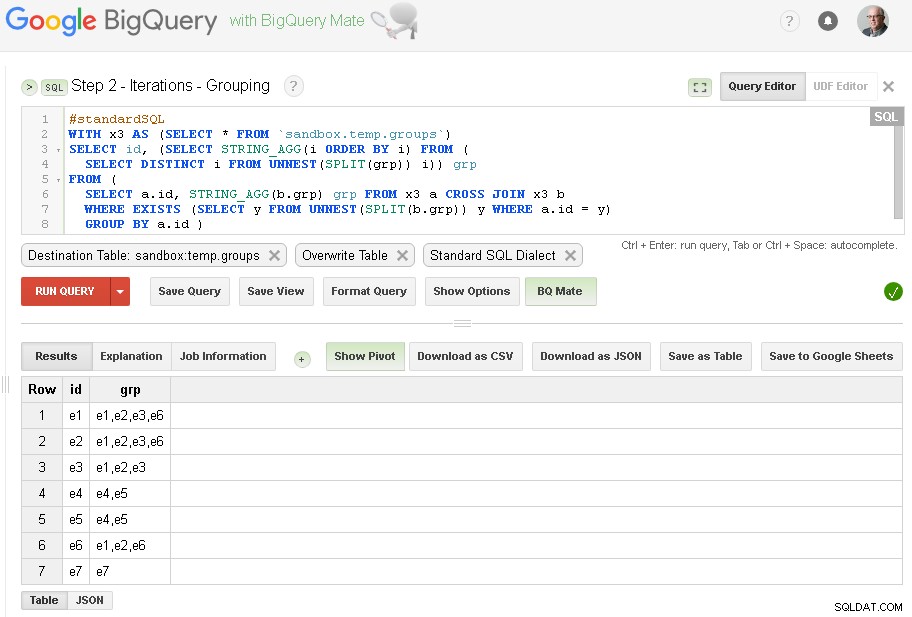
हम पुनरावृत्तियों को तब तक जारी रखेंगे जब तक पाए गए समूहों की संख्या पिछले पुनरावृत्ति के समान नहीं होगी
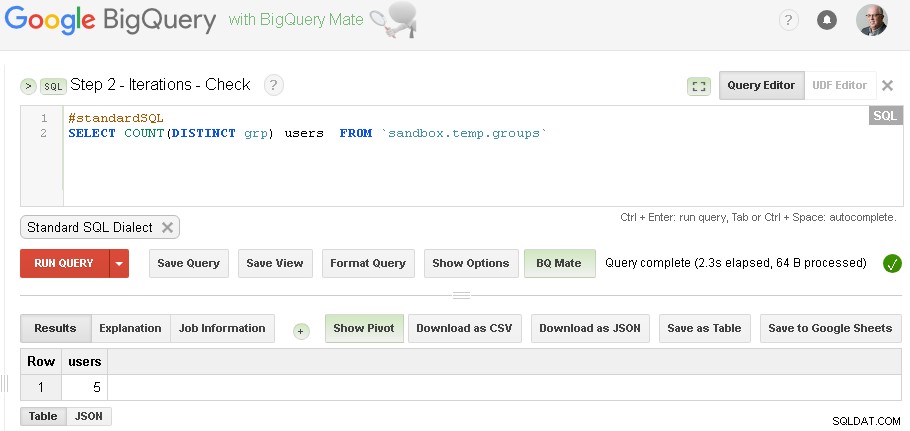
नोट :आप बस दो BigQuery वेब UI टैब खोल सकते हैं (जैसा कि यह ऊपर दिखाया गया है) और बिना किसी कोड को बदले बस ग्रुपिंग चलाएं और फिर पुनरावृत्ति होने तक बार-बार जांचें
(विशिष्ट डेटा के लिए जो मैंने पूर्व-आवश्यकता अनुभाग में उपयोग किया था - मेरे पास तीन पुनरावृत्तियों थे - पहला पुनरावृत्ति 5 उपयोगकर्ताओं का उत्पादन करता था, दूसरा पुनरावृत्ति 3 उपयोगकर्ताओं का उत्पादन करता था और तीसरा पुनरावृत्ति 3 उपयोगकर्ताओं का उत्पादन करता था - जो इंगित करता था कि हमने पुनरावृत्तियों के साथ किया था।
बेशक, वास्तविक जीवन के मामले में - पुनरावृत्तियों की संख्या सिर्फ तीन से अधिक हो सकती है - इसलिए हमें किसी प्रकार के स्वचालन की आवश्यकता है (उत्तर के नीचे संबंधित अनुभाग देखें)।
चरण 3 - अंतिम समूहीकरण
जब id1 ग्रुपिंग पूरी हो जाती है - हम id2 के लिए फाइनल ग्रुपिंग जोड़ सकते हैं
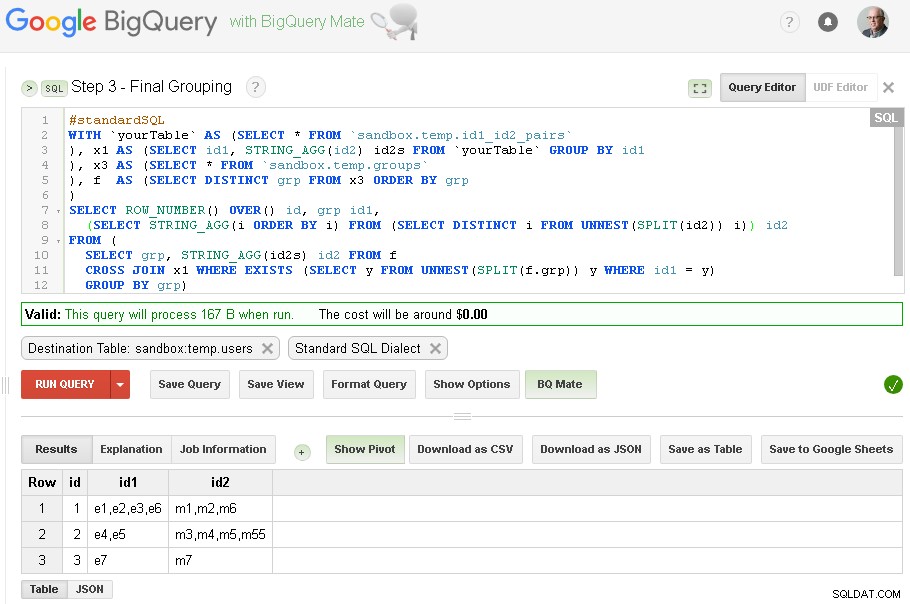
अंतिम परिणाम अब sandbox.temp.users में है टेबल
प्रयुक्त क्वेरी (उपरोक्त वर्णित तर्क और स्क्रीनशॉट के अनुसार संबंधित गंतव्य तालिकाओं को सेट करना और आवश्यकता पड़ने पर ओवरराइट करना न भूलें):
पूर्व-आवश्यकताएं:
#standardSQL
SELECT 1 id, 'e1' id1, 'm1' id2 UNION ALL
SELECT 2, 'e1', 'm2' UNION ALL
SELECT 3, 'e2', 'm2' UNION ALL
SELECT 4, 'e3', 'm1' UNION ALL
SELECT 5, 'e4', 'm3' UNION ALL
SELECT 6, 'e5', 'm3' UNION ALL
SELECT 7, 'e5', 'm4' UNION ALL
SELECT 8, 'e4', 'm5' UNION ALL
SELECT 9, 'e6', 'm6' UNION ALL
SELECT 9, 'e7', 'm7' UNION ALL
SELECT 9, 'e2', 'm6' UNION ALL
SELECT 888, 'e4', 'm55'
चरण 1
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x2 AS (SELECT id2, STRING_AGG(id1) id1s FROM `yourTable` GROUP BY id2
), x3 AS (
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(id1s)) i)) grp
FROM (
SELECT x1.id1 id, STRING_AGG((id1s)) id1s FROM x1 CROSS JOIN x2
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(id1s)) y WHERE x1.id1 = y)
GROUP BY id1)
)
SELECT * FROM x3
चरण 2 - समूह बनाना
#standardSQL
WITH x3 AS (select * from `sandbox.temp.groups`)
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(grp)) i)) grp
FROM (
SELECT a.id, STRING_AGG(b.grp) grp FROM x3 a CROSS JOIN x3 b
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(b.grp)) y WHERE a.id = y)
GROUP BY a.id )
चरण 2 - चेक करें
#standardSQL
SELECT COUNT(DISTINCT grp) users FROM `sandbox.temp.groups`
चरण 3
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x3 as (select * from `sandbox.temp.groups`
), f AS (SELECT DISTINCT grp FROM x3 ORDER BY grp
)
SELECT ROW_NUMBER() OVER() id, grp id1,
(SELECT STRING_AGG(i ORDER BY i) FROM (SELECT DISTINCT i FROM UNNEST(SPLIT(id2)) i)) id2
FROM (
SELECT grp, STRING_AGG(id2s) id2 FROM f
CROSS JOIN x1 WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(f.grp)) y WHERE id1 = y)
GROUP BY grp)
स्वचालन :
बेशक, उपरोक्त "प्रक्रिया" को मैन्युअल रूप से निष्पादित किया जा सकता है यदि पुनरावृत्तियों का तेजी से अभिसरण होता है - तो आप 10-20 रन के साथ समाप्त हो जाएंगे। लेकिन वास्तविक जीवन के अधिक मामलों में आप इसे किसी भी क्लाइंट
के साथ आसानी से स्वचालित कर सकते हैं अपनी पसंद का