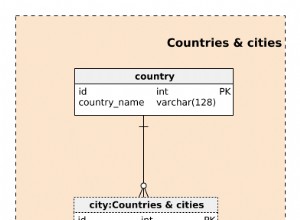
यह डेटा सामान्यीकृत है
TABLE { FIELDS }
-----------------------------------------------------------------------
building { id, data }
floor { id, building_id, data }
room {id, floor_id, data }
bed {id, room_id, data }
यह तालिका नहीं है (बुरा विचार)
TABLE { FIELDS }
-----------------------------------------------------------------------
building { id, data }
floor { id, building_id, data }
room {id, building_id, floor_id, data }
bed {id, building_id, floor_id, room_id, data }
- पहली (अच्छी) तालिका में आपके पास अनावश्यक डुप्लिकेट डेटा नहीं है।
- पहली तालिका में सम्मिलित करना बहुत तेज़ होगा।
- पहली तालिकाएं आपके प्रश्नों को तेज करते हुए स्मृति में अधिक आसानी से फिट हो जाएंगी।
- InnoDB मॉडल A को ध्यान में रखते हुए अनुकूलित किया गया है, मॉडल B के साथ नहीं।
- बाद वाली (खराब) तालिका में डुप्लिकेट डेटा है, अगर जो सिंक से बाहर हो जाता है, आपके पास एक गड़बड़ होगी। डीबी ए सिंक से बाहर निकलने के लिए ज्यादा कठिन नहीं हो सकता है, क्योंकि डेटा केवल एक बार सूचीबद्ध होता है।
- अगर मैं डेटा को जोड़ना चाहता हूं भवन, फर्श, कमरे और बिस्तर से मुझे मॉडल ए के साथ-साथ मॉडल बी में सभी चार तालिकाओं को संयोजित करने की आवश्यकता होगी, आप यहां समय कैसे बचा रहे हैं।
- InnoDB अनुक्रमित डेटा को अपनी फ़ाइल में संग्रहीत करता है, यदि आप
selectकेवल अनुक्रमणिका , टेबल स्वयं कभी नहीं पहुँचा जा सकता है। तो आप इंडेक्स को डुप्लिकेट क्यों कर रहे हैं? MySQL को वैसे भी मुख्य तालिका को पढ़ने की आवश्यकता नहीं होगी। - InnoDB PK को हर सेकेंडरी इंडेक्स में स्टोर करता है , एक समग्र और इस प्रकार लंबे पीके के साथ, आप प्रत्येक चयन को धीमा कर रहे हैं जो एक इंडेक्स का उपयोग करता है और फाइलसाइज को बलून करता है; बिना किसी लाभ के।
- क्या आपको गति की गंभीर समस्या है? यदि नहीं, तो क्या आप अपनी टेबल को असामान्य बना रहे हैं?
- MyISAM का उपयोग करने के बारे में भी न सोचें, जो इन मुद्दों से कम ग्रस्त है, यह बहु-जुड़ने वाले डेटाबेस के लिए अनुकूलित नहीं है और संदर्भात्मक अखंडता या लेनदेन का समर्थन नहीं करता है और इस कार्यभार के लिए एक खराब मिलान है।
- समग्र कुंजी का उपयोग करते समय आप केवल कुंजी के सबसे दाहिने हिस्से का उपयोग कर सकते हैं, अर्थात आप
floor_idका उपयोग नहीं कर सकते हैं तालिका मेंbedid+building_id+floor_id. का उपयोग करने के अलावा अन्य , इसका मतलब है कि आपको मॉडल ए में आवश्यकता से कहीं अधिक कुंजी-स्थान का उपयोग करना पड़ सकता है। या तो आपको या आपको एक अतिरिक्त अनुक्रमणिका जोड़ने की आवश्यकता है (जो पीके की पूरी प्रतिलिपि को खींच लेगी)।
संक्षेप में
मुझे मॉडल बी में बिल्कुल शून्य लाभ और बहुत सारी कमियां दिखाई देती हैं, इसका कभी भी उपयोग न करें!