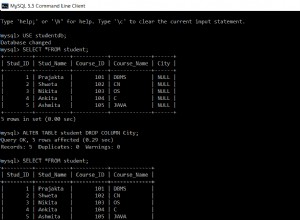
ऐसा लगता है कि निम्नलिखित चाल चल रहा है:
SET @locationID=0,@ts=NULL,@changed=0;
SELECT
MIN(assetID) AS id
, MIN(locationID) AS location
, SUM(secDiff) AS duration
FROM
(SELECT
assetID
, locationID
, @changed := IF(locationID <> previousLocationID, @changed + 1, @changed) AS changed
, IFNULL(TIMESTAMPDIFF(SECOND,
previousTs,
ts
),
0
) AS secDiff
FROM
(SELECT
assetID
, locationID
, @locationID AS previousLocationID
, @locationID := locationID AS currentLocationID
, ts
, @ts AS previousTs
, @ts := ts AS currentTs
FROM Logs L1
WHERE assetid = 1157
ORDER BY ts
) L2
ORDER BY ts
) L3
GROUP BY changed
ORDER BY changed DESC
;
इसे क्रिया में देखें:SQL Fiddle ।
अपडेट करें:
यदि आपको अतिरिक्त तालिकाओं में शामिल होने की आवश्यकता है, तो आपको वास्तव में JOIN और उप-चयन नहीं। जैसा कि एक GROUP BY है वर्तमान में सबसे बाहरी स्तर पर, मौजूदा कथन को कोष्ठक के दूसरे सेट में लपेटने की आवश्यकता है - तथ्य तालिकाओं पर समूहीकरण को रोकने के लिए। उस दिशा में कुछ अन्य समायोजनों के साथ:
SET @locationID=0,@ts=NULL,@changed=0;
SELECT
A.name
, L4.assetID
, L.name
, L4.locationID
, duration
FROM
(SELECT
MIN(assetID) AS assetID
, MIN(locationID) AS locationID
, SUM(secDiff) AS duration
, changed
FROM
(
-- no change in here
) L3
GROUP BY changed
) L4
JOIN Asset A
ON L4.assetID = A.id
JOIN Location L
ON L4.locationID = L.id
ORDER BY changed DESC
;
विस्तृत SQL Fiddle ।
अपडेट 2:
डुप्लिकेट लिस्टिंग को संबोधित करने का सबसे सीधा तरीका DISTINCT . होना चाहिए उन्हें पहले चरण के रूप में दूर करें:
-- no change here
(SELECT
assetID
, locationID
, @locationID AS previousLocationID
, @locationID := locationID AS currentLocationID
, ts
, @ts AS previousTs
, @ts := ts AS currentTs
FROM
(SELECT DISTINCT
assetID
, locationID
, ts
FROM Logs
WHERE assetid = 1157
) L1
ORDER BY ts
) L2
-- no change here either
यह SQL Fiddle डुप्लिकेट किए गए लॉग . के लिए रिटर्न डेटा वही परिणाम सेट करें जो SQL Fiddle के रूप में सेट किया गया हो , जहां पहले की क्वेरी बिना किसी डुप्लीकेट वाले डेटा के विरुद्ध चलती है।
कृपया टिप्पणी करें, यदि और इसके लिए समायोजन/आगे विवरण की आवश्यकता है।