यह वैसे काम नहीं करता जैसा आपको लगता है कि इसे करना चाहिए और दस्तावेज
ए> DISTINCT . का अर्थ समझाता है :यह अलग पंक्तियों . के बारे में है :
(स्रोत:https://dev.mysql.com /doc/refman/5.7/hi/select.html )
प्रत्येक उपयोगकर्ता के लिए एक पंक्ति प्राप्त करने के लिए आपको उपयोगकर्ता द्वारा पंक्तियों को समूहित करने की आवश्यकता है, लेकिन दुर्भाग्य से, आप इस तरह से उनका सबसे हालिया स्कोर प्राप्त नहीं कर सकते हैं। आप अधिकतम, न्यूनतम, औसत स्कोर और अन्य गणना मान प्राप्त कर सकते हैं। GROUP BY कुल कार्य
।
क्वेरी
यह वह क्वेरी है जो आपको आवश्यक मान प्राप्त करती है:
SELECT u.fsname, u.emailaddress, la.score
FROM users u
INNER JOIN attempts la # 'la' from 'last attempt'
ON u.emailaddress = la.emailaddress
LEFT JOIN attempts mr # 'mr' from 'more recent' (than last attempt)
ON la.emailaddress = mr.emailaddress AND la.datetime < mr.datetime
WHERE mr.datetime IS NULL
यह कैसे काम करता है
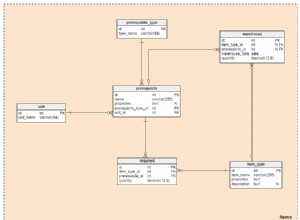
यह तालिका में शामिल हो जाता है उपयोगकर्ता (उपनाम u . के रूप में ) तालिका के साथ प्रयास (उपनाम la . के रूप में , "अंतिम प्रयास" के लिए संक्षिप्त) ईमेल पता . का उपयोग करके मिलान कॉलम के रूप में। यह आपकी क्वेरी में आपके पास पहले से ही शामिल है, मैंने उपनाम जोड़े क्योंकि वे उस बिंदु से कम लिखने में आपकी सहायता करते हैं।
इसके बाद, यह प्रयासों . में शामिल हो जाता है तालिका फिर से (mr के रूप में उपनामित) "अधिक हाल के . से पिछले प्रयास से")। यह la . के प्रत्येक प्रयास से मेल खाता है mr . के सभी प्रयासों के साथ एक ही उपयोगकर्ता (उनके ईमेल पते . द्वारा पहचाना जाता है) ) और जिनके पास हाल ही का डेटाटाइम है . बाएं शामिल हों सुनिश्चित करता है कि प्रत्येक पंक्ति la . से mr . से कम से कम एक पंक्ति से मेल खाता है . la . से पंक्तियां जिसका mr . में कोई मेल नहीं है वे पंक्तियाँ हैं जिनमें datetime . का सबसे बड़ा मान है प्रत्येक ईमेल पता . के लिए . वे NULL . से भरी पंक्तियों से मेल खाते हैं (श्री . के लिए भाग)।
अंत में, WHERE क्लॉज केवल उन पंक्तियों को रखता है जिनमें NULL है डेटाटाइम . में mr . से चयनित पंक्ति का स्तंभ . ये वे पंक्तियाँ हैं जो la . की नवीनतम प्रविष्टियों से मेल खाती हैं ईमेल पता . के प्रत्येक मान के लिए ।
प्रदर्शन टिप्पणियां
इस क्वेरी को तेजी से चलाने के लिए (कोई भी प्रश्न! ) को JOIN . में इस्तेमाल किए गए कॉलम पर इंडेक्स चाहिए , कहां , ग्रुप बाय और आर्डर बाय खंड।
आपको ईमेल पता का उपयोग नहीं करना चाहिए तालिका में प्रयास उपयोगकर्ता की पहचान करने के लिए। आपके पास PK होना चाहिए (प्राथमिक कुंजी) टेबल पर उपयोगकर्ता और उसका उपयोग FK . के रूप में करें (विदेशी कुंजी) तालिका में प्रयास (और अन्य तालिकाएँ जो किसी उपयोगकर्ता को संदर्भित करती हैं)। अगर ईमेल पता पीके है तालिका उपयोगकर्ताओं . की इसे एक UNIQUE INDEX . में बदलें और एक नए INTEGER AUTO INCREMENT . का उपयोग करें एड कॉलम userId पीके . के रूप में बजाय। संख्यात्मक स्तंभों पर अनुक्रमणिकाएँ तेज़ होती हैं और स्ट्रिंग स्तंभों पर अनुक्रमणिका की तुलना में कम स्थान का उपयोग करती हैं।