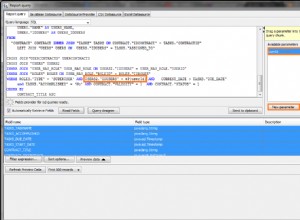
मैं निम्नलिखित अनुक्रमणिका (बी-पेड़ अनुक्रमणिका) बनाउंगा:
analytics(user_id, source, id)
transactions(analytics, status)
यह गॉर्डन के सुझाव से अलग है।
अनुक्रमणिका में स्तंभों का क्रम महत्वपूर्ण है।
आप विशिष्ट analytics.user_id . द्वारा फ़िल्टर करते हैं , इसलिए इस फ़ील्ड को अनुक्रमणिका में सबसे पहले होना चाहिए। फिर आप analytics.source के आधार पर समूह बनाते हैं . source . के आधार पर छँटाई से बचने के लिए यह सूचकांक का अगला क्षेत्र होना चाहिए। आप analytics.id . का भी संदर्भ देते हैं , इसलिए इस क्षेत्र को सूचकांक के हिस्से के रूप में रखना बेहतर है, इसे अंतिम रखें। क्या MySQL सिर्फ इंडेक्स को पढ़ने और टेबल को टच नहीं करने में सक्षम है? मुझे नहीं पता, लेकिन इसका परीक्षण करना आसान है।
transactions पर अनुक्रमणिका analytics से शुरू करना होगा , क्योंकि इसका उपयोग JOIN . में किया जाएगा . हमें status भी चाहिए ।
SELECT
analytics.source AS referrer,
COUNT(analytics.id) AS frequency,
SUM(IF(transactions.status = 'COMPLETED', 1, 0)) AS sales
FROM analytics
LEFT JOIN transactions ON analytics.id = transactions.analytics
WHERE analytics.user_id = 52094
GROUP BY analytics.source
ORDER BY frequency DESC
LIMIT 10