IN BOOLEAN MODE का उपयोग करें ।
दिनांक अनुक्रमणिका उपयोगी नहीं है। दो इंडेक्स को मिलाने का कोई तरीका नहीं है।
सावधान रहें, यदि कोई उपयोगकर्ता 30K पंक्तियों में दिखाई देने वाली किसी चीज़ की खोज करता है, तो क्वेरी धीमी हो जाएगी। इसके आसपास कोई सीधा रास्ता नहीं है।
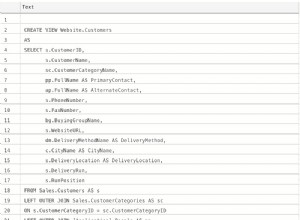
मुझे संदेह है कि आपके पास TEXT है तालिका में कॉलम? अगर ऐसा है तो उम्मीद है। आँख बंद करके SELECT * . करने के बजाय , आइए पहले आईडी खोजें और LIMIT प्राप्त करें लागू किया गया, फिर * करें ।
SELECT a.*
FROM tbl AS a
JOIN ( SELECT date, id
FROM tbl
WHERE MATCH(...) AGAINST (...)
ORDER BY date DESC
LIMIT 10 ) AS x
USING(date, id)
ORDER BY date DESC;
साथ में
PRIMARY KEY(date, id),
INDEX(id),
FULLTEXT(...)
यह सूत्रीकरण और अनुक्रमण इस तरह काम करना चाहिए:
FULLTEXTका उपयोग करें 30 हजार पंक्तियों को खोजने के लिए, PK वितरित करें।- पीके के साथ, 30K पंक्तियों को
dateके अनुसार क्रमबद्ध करें । - आखिरी 10 चुनें,
date, idवितरित करें - पीके का उपयोग करके तालिका में 10 बार वापस पहुंचें।
- फिर से क्रमित करें। (हाँ, यह आवश्यक है।)
अधिक (टिप्पणियों की अधिकता का जवाब):
मेरे सुधार के पीछे का लक्ष्य सभी को लाने से बचना है 30K . के कॉलम पंक्तियाँ। इसके बजाय, यह केवल PRIMARY KEY प्राप्त करता है , फिर उसे कम करके 10 कर देता है, फिर * . प्राप्त करता है केवल 10 पंक्तियाँ। बहुत कम सामान इधर-उधर फेंका गया।
COUNT . के बारे में एक InnoDB टेबल पर:
- INDEX(col) ऐसा बनाता है कि एक इंडेक्स स्कैन
SELECT COUNT(*)के लिए काम करता है याSELECT COUNT(col)बिनाWHERE। - बिना
INDEX(col),SELECT COUNT(*)will use the "smallest" index; butSELECT COUNT(col)` को एक टेबल की आवश्यकता होगी स्कैन करें। - टेबल स्कैन आमतौर पर होता है इंडेक्स स्कैन की तुलना में धीमा।
- समय का ध्यान रखें -- यह इस बात से काफी प्रभावित होता है कि क्या अनुक्रमणिका और/या तालिका पहले से ही RAM में संचित है।
FULLTEXT के बारे में एक और बात + है शब्दों के सामने - यह कहना कि प्रत्येक शब्द का अस्तित्व होना चाहिए, अन्यथा कोई मेल नहीं है। यह 30K पर कटौती कर सकता है।
FULLTEXT अनुक्रमणिका date, id वितरित करेगी यादृच्छिक क्रम है, पीके आदेश नहीं। वैसे भी, किसी भी आदेश को मान लेना 'गलत' है, इसलिए ORDER BY जोड़ना 'सही' है , तो ऑप्टिमाइज़र को इसे टॉस करने दें यदि यह जानता है कि यह फालतू है। और कभी-कभी अनुकूलक ORDER BY . का लाभ उठा सकता है (आपके मामले में नहीं)।
केवल ORDER BY को हटाया जा रहा है , कई मामलों में, क्वेरी को बहुत तेज़ी से चलाता है। ऐसा इसलिए है क्योंकि यह 30K पंक्तियों को लाने, कहने और उन्हें छाँटने से बचता है। इसके बजाय यह केवल "कोई भी" 10 पंक्तियों को वितरित करता है।
(मुझे पोस्टग्रेज के साथ कोई अनुभव नहीं है, इसलिए मैं उस प्रश्न का समाधान नहीं कर सकता।)