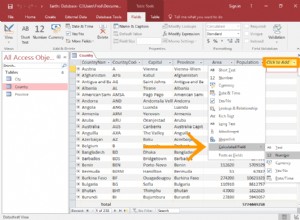
यदि आप जानते हैं कि आपको डेटा की आवश्यकता है, तो आगे बढ़ें और इसे खींचकर कोड में गिनें। हालांकि, अगर आपको केवल गिनती की आवश्यकता है, तो वास्तव में पंक्तियों को पुनर्प्राप्त करने की तुलना में डेटाबेस से गिनती खींचना काफी तेज़ है। साथ ही यह मानक अभ्यास है कि केवल वही खींचा जाए जिसकी आपको आवश्यकता है।
उदाहरण के लिए, यदि आप किसी तालिका में सभी पंक्तियों की गणना कर रहे हैं, तो अधिकांश डेटाबेस कार्यान्वयनों को किसी भी पंक्ति को देखने की आवश्यकता नहीं है। टेबल्स जानते हैं कि उनके पास कितनी पंक्तियां हैं। अगर क्वेरी में where . में फ़िल्टर हैं खंड और यह एक अनुक्रमणिका का उपयोग कर सकता है, इसे फिर से वास्तविक पंक्तियों के डेटा को देखने की आवश्यकता नहीं होगी, बस अनुक्रमणिका से पंक्तियों की गणना करता है।
और यह सब स्थानांतरित किए गए कम डेटा की गणना नहीं कर रहा है।
डेटाबेस गति के बारे में अंगूठे का एक नियम आगे बढ़ो और इसे अपने लिए आज़माएं। सामान्य नियम हमेशा एक अच्छा संकेतक नहीं होते हैं। उदाहरण के लिए, यदि तालिका 10 पंक्तियों और केवल कुछ स्तंभों की थी, तो मैं पूरी चीज़ को वैसे भी खींच सकता हूँ, जब तक कि मुझे इसकी आवश्यकता न हो, क्योंकि डेटाबेस में 2 राउंड ट्रिप क्वेरी की लागत से अधिक होगी।