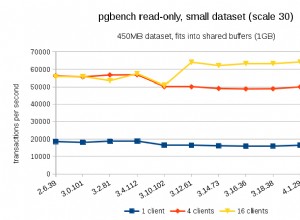
मैं mssql के बारे में अधिक जानता हूं कि MySQL, लेकिन मुझे नहीं लगता कि आप जिस संख्या में शामिल हो रहे हैं या पंक्तियों की संख्या के बारे में बात कर रहे हैं, आपको सही इंडेक्स के साथ बहुत सारी समस्याएं पैदा करनी चाहिए। क्या आपने यह देखने के लिए क्वेरी योजना का विश्लेषण किया है कि कहीं आप में कोई कमी तो नहीं है?
https://dev.mysql.com/doc/refman/5.0 /hi/explain.html
कहा जा रहा है, एक बार जब आप अपनी अनुक्रमणिका से संतुष्ट हो जाते हैं और अन्य सभी रास्ते समाप्त कर लेते हैं, तो डी-सामान्यीकरण सही उत्तर हो सकता है। यदि आपके पास केवल एक या दो प्रश्न हैं जो समस्याएँ हैं, तो एक मैन्युअल दृष्टिकोण संभवतः उपयुक्त है, जबकि डेटा क्यूब विकसित करने के लिए एक प्लेटफ़ॉर्म बनाने के लिए किसी प्रकार का डेटा वेयरहाउसिंग टूल बेहतर हो सकता है।
यहाँ एक साइट है जो मुझे मिली है जो इस विषय को छूती है:
https://www.meansandends.com /mysql-data-warehouse/?link_body%2Fbody=%7Bincl%3AAggregation%7D
यदि आप एक बार में कुछ ही कर रहे हैं (और मैं आपकी OLTP तालिकाओं को प्रतिस्थापित नहीं कर रहा हूँ, केवल रिपोर्टिंग उद्देश्यों के लिए एक नया बना रहा हूँ) तो यहाँ एक सरल तकनीक है जिसका उपयोग आप सामान्यीकरण प्रश्नों को सरल रखने के लिए कर सकते हैं। मान लें कि आपके आवेदन में यह प्रश्न है:
select a.name, b.address from tbla a
join tblb b on b.fk_a_id = a.id where a.id=1
आप एक असामान्य तालिका बना सकते हैं और लगभग एक ही क्वेरी के साथ पॉप्युलेट कर सकते हैं:
create table tbl_ab (a_id, a_name, b_address);
-- (types elided)
ध्यान दें कि अंडरस्कोर आपके द्वारा उपयोग किए जाने वाले टेबल एलियास से मेल खाते हैं
insert tbl_ab select a.id, a.name, b.address from tbla a
join tblb b on b.fk_a_id = a.id
-- no where clause because you want everything
फिर नई असामान्य तालिका का उपयोग करने के लिए अपने ऐप को ठीक करने के लिए, बिंदुओं को अंडरस्कोर के लिए स्विच करें।
select a_name as name, b_address as address
from tbl_ab where a_id = 1;
बड़े प्रश्नों के लिए यह बहुत समय बचा सकता है और यह स्पष्ट करता है कि डेटा कहां से आया है, और आप अपने पास पहले से मौजूद प्रश्नों का पुन:उपयोग कर सकते हैं।
याद रखें, मैं केवल अंतिम उपाय के रूप में इसकी वकालत कर रहा हूं। मुझे यकीन है कि कुछ इंडेक्स हैं जो आपकी मदद करेंगे। और जब आप डी-नॉर्मलाइज़ करते हैं, तो अपने डिस्क पर अतिरिक्त स्थान का हिसाब देना न भूलें, और यह पता लगाएं कि आप नई टेबल को पॉप्युलेट करने के लिए क्वेरी कब चलाएंगे। यह शायद रात में होना चाहिए, या जब भी गतिविधि कम हो। और उस तालिका का डेटा, निश्चित रूप से, कभी भी अद्यतित नहीं होगा।
[फिर भी एक और संपादन] यह न भूलें कि आपके द्वारा बनाई गई नई तालिकाओं को भी अनुक्रमित करने की आवश्यकता है! अच्छी बात यह है कि आप अपने दिल की सामग्री को अनुक्रमित कर सकते हैं और अपडेट लॉक विवाद के बारे में चिंता न करें, क्योंकि आपके बल्क इंसर्ट के अलावा तालिका में केवल चयन दिखाई देंगे।