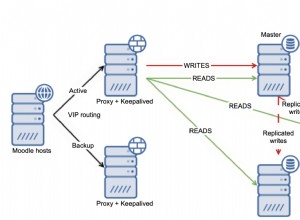
पाठ पुनर्प्राप्ति प्रणाली के लिए मूल डेटा संरचना एक उलटा अनुक्रमणिका है . यह अनिवार्य रूप से दस्तावेज़ संग्रह में पाए जाने वाले शब्दों की एक सूची है जिसमें वे होने वाले दस्तावेज़ों की सूची है। इसमें प्रत्येक दस्तावेज़ की घटना के बारे में मेटाडेटा भी हो सकता है, जैसे कि शब्द कितनी बार प्रकट होता है।
शब्दों वाले दस्तावेज़ों को खोज शब्दों से मिलान करके पूछताछ की जा सकती है। प्रासंगिकता निर्धारित करने के लिए, एक अनुमानी जिसे Cosine Ranking कहा जाता है हिट पर गणना की जाती है। यह प्रत्येक n खोज शब्दों के लिए एक घटक के साथ n-आयामी वेक्टर का निर्माण करके काम करता है। आप चाहें तो खोज शब्दों का वजन भी कर सकते हैं। यह सदिश n-आयामी स्थान में एक बिंदु देता है जो आपके खोज शब्दों से मेल खाता है।
प्रत्येक दस्तावेज़ में भारित घटनाओं के आधार पर एक समान वेक्टर का निर्माण उल्टे सूचकांक से किया जा सकता है, जिसमें प्रत्येक खोज शब्द के लिए अक्ष के साथ वेक्टर में प्रत्येक अक्ष होता है। यदि आप इन वैक्टरों के डॉट उत्पाद की गणना करते हैं तो आपको उनके बीच के कोण का कोसाइन मिलता है। 1.0 कॉस (0) के बराबर है, जो मान लेगा कि वैक्टर मूल से एक सामान्य रेखा पर कब्जा कर लेते हैं। सदिश एक साथ जितने करीब होंगे, कोण उतना ही छोटा होगा और कोज्या 1.0 के करीब होगा।
यदि आप खोज परिणामों को कोसाइन के अनुसार क्रमित करते हैं (या उन्हें mg करता है) आपको सबसे अधिक प्रासंगिक मिलता है। चतुर प्रासंगिकता एल्गोरिदम खोज शब्दों के महत्व के साथ खिलवाड़ करते हैं, उच्च प्रासंगिकता वाले शब्दों के पक्ष में डॉट उत्पाद को तिरछा करते हैं।
अगर आप थोड़ी खुदाई करना चाहते हैं, तो गीगाबाइट्स को मैनेज करना द्वारा बेल और Moffet पाठ पुनर्प्राप्ति प्रणाली की आंतरिक संरचना पर चर्चा करता है।