यहां बताया गया है कि इन दो दृष्टिकोणों को डेटाबेस में भौतिक रूप से कैसे दर्शाया जाएगा:
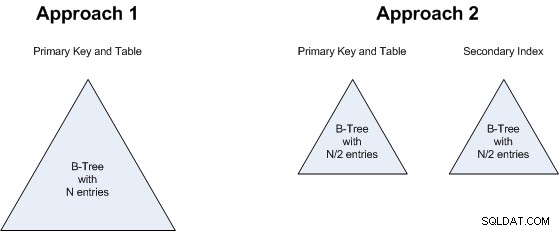
आइए दोनों दृष्टिकोणों का विश्लेषण करें...
दृष्टिकोण 1 (दोनों दिशाएँ तालिका में संग्रहीत हैं):
- प्रो:सरल प्रश्न।
- CON:केवल डालने/अपडेट करने/हटाने से डेटा दूषित हो सकता है एक दिशा।
- माइनर प्रो:दोस्ती को दोहराया नहीं जा सकता है यह सुनिश्चित करने के लिए अतिरिक्त बाधाओं की आवश्यकता नहीं है।
- आगे के विश्लेषण की आवश्यकता है:
- टाई:वन इंडेक्स कवर दोनों दिशाएं, इसलिए आपको द्वितीयक अनुक्रमणिका की आवश्यकता नहीं है।
- टाई:संग्रहण आवश्यकताएं।
- टाई:प्रदर्शन।
दृष्टिकोण 2 (तालिका में संग्रहीत केवल एक दिशा):
- CON:अधिक जटिल प्रश्न।
- PRO:विपरीत दिशा को संभालना भूलकर डेटा को दूषित नहीं कर सकता, क्योंकि कोई विपरीत दिशा नहीं है ।
- माइनर कॉन:के लिए
CHECK(UID < FriendID)की आवश्यकता है , इसलिए एक ही दोस्ती को कभी भी दो अलग-अलग तरीकों से प्रदर्शित नहीं किया जा सकता है, और कुंजी(UID, FriendID)पर है। अपना काम कर सकता है। - आगे के विश्लेषण की आवश्यकता है:
- टाई:कवर
के लिए दो इंडेक्स ज़रूरी हैं पूछताछ की दोनों दिशाएं (
{UID, FriendID}. पर समग्र अनुक्रमणिका और{FriendID, UID}. पर कंपोजिट इंडेक्स )। - टाई:संग्रहण आवश्यकताएं।
- टाई:प्रदर्शन।
- टाई:कवर
के लिए दो इंडेक्स ज़रूरी हैं पूछताछ की दोनों दिशाएं (
बिंदु 1 विशेष रुचि है। MySQL/InnoDB हमेशा क्लस्टर क्लस्टर टेबल में डेटा और सेकेंडरी इंडेक्स महंगे हो सकते हैं (देखें "क्लस्टरिंग के नुकसान" में यह लेख ), इसलिए ऐसा लग सकता है कि दृष्टिकोण 2 में द्वितीयक सूचकांक कम पंक्तियों के सभी लाभों को खा जाएगा। हालांकि , द्वितीयक अनुक्रमणिका में ठीक वही फ़ील्ड होते हैं जो प्राथमिक (केवल विपरीत क्रम में) होते हैं, इसलिए इस विशेष मामले में कोई संग्रहण ओवरहेड नहीं होता है। टेबल हीप के लिए कोई पॉइंटर भी नहीं है (चूंकि कोई टेबल हीप नहीं है), इसलिए यह शायद सस्ता स्टोरेज-वार है कि एक सामान्य हीप-आधारित इंडेक्स। और यह मानते हुए कि क्वेरी इंडेक्स के साथ कवर की गई है, सामान्य रूप से क्लस्टर टेबल में सेकेंडरी इंडेक्स से जुड़ा डबल-लुकअप नहीं होगा। तो, यह मूल रूप से एक टाई है (न तो दृष्टिकोण 1 और न ही दृष्टिकोण 2 का महत्वपूर्ण लाभ है)।
बिंदु 2 बिंदु 1 से संबंधित है:इससे कोई फर्क नहीं पड़ता कि हमारे पास एन मानों का बी-ट्री होगा या दो बी-पेड़ होंगे, प्रत्येक में एन/2 मान होंगे। तो यह भी एक टाई है:दोनों दृष्टिकोण लगभग समान मात्रा में भंडारण का उपयोग करेंगे।
बिंदु 3 . पर भी यही तर्क लागू होता है :चाहे हम एक बड़ा बी-ट्री खोजें या 2 छोटे, इससे कोई खास फर्क नहीं पड़ता, इसलिए यह भी एक टाई है।
तो, मजबूती के लिए, और कुछ अधिक भद्दे प्रश्नों के बावजूद और अतिरिक्त CHECK . की आवश्यकता के बावजूद , मैं दृष्टिकोण 2 के साथ जाऊंगा।