सबसे पहले "टॉक्सी" एक मानक शब्द नहीं है। हमेशा अपनी शर्तों को परिभाषित करें! या कम से कम प्रासंगिक लिंक प्रदान करें।
और अब सवाल पर ही...
नहीं, आपके पास 3 टेबल होंगे।
आप बहुत हद तक सही रास्ते पर हैं, इस अपवाद के साथ कि आप इनमें से कई चरणों को "मर्ज" करने के लिए SQL की सेट-आधारित प्रकृति का उपयोग कर सकते हैं। उदाहरण के लिए, किसी आइटम 1 को टैग के साथ टैग करना:'tag1', 'tag2' और 'tag3' इस तरह से किया जा सकता है...
INSERT IGNORE INTO tagmap (item_id, tag_id)
SELECT 1, tag_id FROM tags WHERE tag_text IN ('tag1', 'tag2', 'tag3');
IGNORE यह सफल होने की अनुमति देता है, भले ही आइटम इनमें से कुछ टैग से पहले से जुड़ा हो।
यह मानता है कि सभी आवश्यक टैग पहले से ही tags . में हैं . मान लें कि tag.tag_id ऑटो-इन्क्रीमेंट है, आप यह सुनिश्चित करने के लिए कुछ ऐसा कर सकते हैं:
INSERT IGNORE INTO tags (tag_text) VALUES ('tag1'), ('tag2'), ('tag3');
कोई जादू नहीं है। यदि "आइटम किसी विशेष टैग से जुड़ा है" ज्ञान का एक टुकड़ा है जिसे आप रिकॉर्ड करना चाहते हैं, तो यह होगा डेटाबेस में किसी प्रकार का भौतिक प्रतिनिधित्व करने के लिए।
आपका मतलब आइटम को फिर से टैग करना है (टैग को स्वयं संशोधित नहीं करना)?
उन सभी टैग को हटाने के लिए जो सूची में नहीं हैं, कुछ इस तरह करें:
DELETE FROM tagmap
WHERE
item_id = 1
AND tag_id NOT IN (
SELECT tag_id FROM tags
WHERE tag_text IN ('tag1', 'tag3')
);
यह 'tag1' और 'tag3' को छोड़कर सभी टैग से आइटम को डिस्कनेक्ट कर देगा। ऊपर दिए गए INSERT को निष्पादित करें और टैग को जोड़ने और हटाने दोनों को "कवर" करने के लिए एक के बाद एक इसे DELETE करें।
आप इन सब के साथ SQL Fiddle में खेल सकते हैं। ।
सही। FK का चाइल्ड एंडपॉइंट रेफ़रेंशियल एक्शन (जैसे ON DELETE CASCADE) को ट्रिगर नहीं करेगा, केवल माता-पिता करेंगे।
BTW, आप इस स्कीमा का उपयोग कर रहे हैं क्योंकि आप tags . में अतिरिक्त फ़ील्ड चाहते हैं (tag_text के पास ), सही? यदि आप ऐसा करते हैं, तो इस अतिरिक्त डेटा को केवल इसलिए नहीं खोना क्योंकि सभी कनेक्शन चले गए हैं वांछित व्यवहार है।
लेकिन अगर आप सिर्फ tag_text चाहते थे , आप एक सरल स्कीमा का उपयोग करेंगे जहां सभी कनेक्शन हटाना टैग को हटाने जैसा ही होगा:
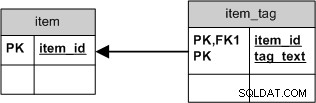
यह केवल SQL को सरल नहीं करेगा, यह बेहतर क्लस्टरिंग भी प्रदान करेगा। ।
पहली नज़र में, "टॉक्सी" ऐसा लग सकता है कि यह अंतरिक्ष की बचत कर रहा है, लेकिन व्यवहार में वास्तव में ऐसा नहीं हो सकता है, क्योंकि इसके लिए अतिरिक्त तालिकाओं और अनुक्रमणिका की आवश्यकता होती है (और टैग छोटे होते हैं)।
ऐसा कुछ करने का निर्णय लेने से पहले उपाय करें। ऊपर उल्लिखित My SQL Fiddle tagmap . में फ़ील्ड के एक बहुत ही जानबूझकर क्रम का उपयोग करता है PK, इसलिए डेटा को इस तरह की गिनती के लिए बहुत अनुकूल तरीके से क्लस्टर किया जाता है (याद रखें:InnoDB टेबल क्लस्टर किए गए हैं
) इससे पहले कि यह एक समस्या बन जाए, आपके पास वास्तव में बड़ी मात्रा में आइटम (या असामान्य रूप से उच्च प्रदर्शन की आवश्यकता) होनी चाहिए।
किसी भी स्थिति में, माप वास्तविक मात्रा में डेटा पर!