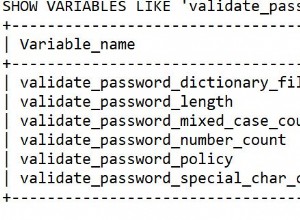
आपकी बताई गई आवश्यकता को प्राप्त करने के लिए यहां एक मॉडल दिया गया है।
समय श्रृंखला डेटा मॉडल का लिंक मजबूत>
IDEF1X नोटेशन से लिंक करें उन लोगों के लिए जो रिलेशनल मॉडलिंग स्टैंडर्ड से अपरिचित हैं।
-
5NF के लिए सामान्यीकृत; कोई डुप्लिकेट कॉलम नहीं; कोई अद्यतन विसंगतियाँ नहीं, कोई शून्य नहीं।
-
जब किसी उत्पाद की स्थिति बदल जाती है, तो बस वर्तमान दिनांक समय के साथ ProductStatus में एक पंक्ति डालें। पिछली पंक्तियों को छूने की आवश्यकता नहीं है (जो सत्य थीं, और सत्य बनी हुई हैं)। कोई डमी मान नहीं है जो रिपोर्ट टूल (आपके ऐप के अलावा) की व्याख्या करता है।
-
दिनांक समय वास्तविक दिनांक समय है जिसे उत्पाद को उस स्थिति में रखा गया था; "से", यदि आप करेंगे। "टू" आसानी से व्युत्पन्न होता है:यह उत्पाद के लिए अगली (दिनांक समय> "प्रेषक") पंक्ति का दिनांक समय है; जहां यह मौजूद नहीं है, मान वर्तमान दिनांक समय है (ISNULL का उपयोग करें)।
पहला मॉडल पूरा हो गया है; (ProductId, DateTime) प्राथमिक कुंजी के लिए विशिष्टता प्रदान करने के लिए पर्याप्त है। हालांकि, चूंकि आप कुछ क्वेरी शर्तों के लिए गति का अनुरोध करते हैं, हम भौतिक स्तर पर मॉडल को बढ़ा सकते हैं, और प्रदान कर सकते हैं:
-
एक इंडेक्स (हमारे पास पहले से ही पीके इंडेक्स है, इसलिए हम कवर किए गए प्रश्नों का समर्थन करने के लिए पहले, दूसरा इंडेक्स जोड़ने से पहले इसे बढ़ाएंगे) (जो {ProductId | DateTime | Status} की किसी भी व्यवस्था पर आधारित हैं, बिना इंडेक्स द्वारा आपूर्ति किए जा सकते हैं। डेटा पंक्तियों पर जाने के लिए)। जो Status::ProductStatus संबंध को गैर-पहचान (टूटी हुई रेखा) से पहचान प्रकार (ठोस रेखा) में बदल देता है।
-
पीके व्यवस्था का चयन इस आधार पर किया जाता है कि उत्पाद दिनांक समय स्थिति के आधार पर अधिकांश प्रश्न टाइम सीरीज़ होंगे।
-
स्थिति के आधार पर प्रश्नों की गति बढ़ाने के लिए दूसरी अनुक्रमणिका की आपूर्ति की जाती है।
-
वैकल्पिक व्यवस्था में, इसे उलट दिया जाता है; यानी, हम ज्यादातर सभी उत्पादों की वर्तमान स्थिति चाहते हैं।
-
ProductStatus के सभी प्रतिपादनों में, द्वितीयक अनुक्रमणिका (PK नहीं) में दिनांक समय स्तंभ DESCending है; सबसे नया सबसे पहले है।
मैंने आपके द्वारा अनुरोधित चर्चा प्रदान की है। बेशक, आपको उचित आकार के डेटा सेट के साथ प्रयोग करने और अपने निर्णय लेने की आवश्यकता है। अगर यहां कुछ भी है जो आपको समझ में नहीं आता है, तो कृपया पूछें, और मैं विस्तार करूंगा।
टिप्पणियों के प्रतिसाद
2 की वर्तमान स्थिति वाले सभी उत्पादों की रिपोर्ट करें
SELECT ProductId,
Description
FROM Product p,
ProductStatus ps
WHERE p.ProductId = ps.ProductId -- Join
AND StatusCode = 2 -- Request
AND DateTime = ( -- Current Status on the left ...
SELECT MAX(DateTime) -- Current Status row for outer Product
FROM ProductStatus ps_inner
WHERE p.ProductId = ps_inner.ProductId
)-
ProductIdअनुक्रमित है, प्रमुख कर्नल, दोनों तरफ -
DateTimeअनुक्रमित में, कवर किए गए क्वेरी विकल्प में दूसरा कॉलम -
StatusCodeअनुक्रमित है, कवर किए गए क्वेरी विकल्प में तीसरा स्तंभ -
चूंकि
StatusCodeइंडेक्स में DESCending है, आंतरिक क्वेरी को संतुष्ट करने के लिए केवल एक फ़ेच की आवश्यकता है -
पंक्तियों की आवश्यकता एक ही समय में, एक प्रश्न के लिए होती है; वे एक साथ करीब हैं (क्लस्टर इंडेक्स के कारण); छोटी पंक्ति के आकार के कारण लगभग हमेशा एक ही पृष्ठ पर।
यह साधारण SQL है, एक सबक्वेरी, SQL इंजन की शक्ति का उपयोग करते हुए, रिलेशनल सेट प्रोसेसिंग। यह एक सही तरीका . है , कुछ भी तेज़ नहीं है, और कोई अन्य तरीका धीमा होगा। कोई भी रिपोर्ट टूल इस कोड को कुछ ही क्लिक में तैयार करेगा, बिना टाइपिंग के।
ProductStatus में दो तिथियां
डेटटाइमफ्रॉम और डेटटाइम टू जैसे कॉलम सकल त्रुटियां हैं। आइए इसे महत्व के क्रम में लें।
-
यह एक सकल सामान्यीकरण त्रुटि है। "DateTimeTo" आसानी से अगली पंक्ति के एकल दिनांक समय से प्राप्त होता है; इसलिए यह बेमानी है, एक डुप्लिकेट कॉलम।
- सटीकता इसमें नहीं आती है:जिसे डेटाटाइप (DATE, DATETIME, SMALLDATETIME) के आधार पर आसानी से हल किया जाता है। चाहे आप एक कम सेकंड, माइक्रोसेकंड, या नैनोसेकंड प्रदर्शित करें, यह एक व्यावसायिक निर्णय है; इसका संग्रहीत डेटा से कोई लेना-देना नहीं है।
-
डेटटू कॉलम को कार्यान्वित करना 100% डुप्लिकेट है (अगली पंक्ति के डेटटाइम का)। इसमें डिस्क स्थान का दोगुना लगता है . एक बड़ी मेज के लिए, यह महत्वपूर्ण अनावश्यक अपशिष्ट होगा।
-
यह देखते हुए कि यह एक छोटी पंक्ति है, आपको दोगुने तार्किक और भौतिक I/Os की आवश्यकता होगी टेबल पढ़ने के लिए, हर एक्सेस पर।
-
और कैश स्पेस से दोगुना (या दूसरे तरीके से कहें तो, किसी भी कैशे स्थान में केवल आधी पंक्तियाँ ही फ़िट होंगी)।
-
एक डुप्लिकेट कॉलम शुरू करके, आपने त्रुटि की संभावना पेश की है (मान अब दो तरीकों से प्राप्त किया जा सकता है:डुप्लिकेट डेटटाइम टू कॉलम या अगली पंक्ति के डेटटाइम से)।
-
यह भी एक अपडेट विसंगति है . जब आप किसी भी डेटटाइम को अपडेट करते हैं तो अपडेट किया जाता है, पिछली पंक्ति का डेटटाइम टू प्राप्त किया जाना चाहिए (कोई बड़ी बात नहीं है क्योंकि यह करीब है) और अपडेट किया गया है (बड़ी बात क्योंकि यह एक अतिरिक्त क्रिया है जिसे टाला जा सकता है)।
-
"छोटा" और "कोडिंग शॉर्टकट" अप्रासंगिक हैं, SQL एक बोझिल डेटा हेरफेर भाषा है, लेकिन SQL हमारे पास है (बस उसके साथ निपटो)। जो कोई सबक्वेरी को कोड नहीं कर सकता उसे वास्तव में कोडिंग नहीं करनी चाहिए। कोई भी जो मामूली कोडिंग "कठिनाई" को कम करने के लिए कॉलम को डुप्लिकेट करता है, वास्तव में मॉडलिंग डेटाबेस नहीं होना चाहिए।
अच्छी तरह से ध्यान दें, कि यदि उच्चतम आदेश नियम (सामान्यीकरण) को बनाए रखा जाता है, तो निचले क्रम की समस्याओं का पूरा सेट समाप्त हो जाता है।
सेट के अनुसार सोचें
-
सरल SQL लिखते समय "कठिनाई" या "दर्द" का अनुभव करने वाला कोई भी व्यक्ति अपना कार्य करने में अपंग होता है। आमतौर पर डेवलपर नहीं . होता है सेट . के संदर्भ में सोच और रिलेशनल डेटाबेस सेट-ओरिएंटेड मॉडल . है ।
-
उपरोक्त प्रश्न के लिए, हमें वर्तमान दिनांक समय की आवश्यकता है; चूंकि ProductStatus एक सेट है उत्पाद राज्यों की कालानुक्रमिक क्रम में, हमें बस सेट के नवीनतम, या MAX(DateTime) की आवश्यकता है उत्पाद से संबंधित है।
-
अब आइए सेट . के संदर्भ में कथित रूप से "मुश्किल" कुछ देखें . अवधि की रिपोर्ट के लिए कि प्रत्येक उत्पाद एक विशेष स्थिति में रहा है:डेटटाइमफ्रॉम एक उपलब्ध कॉलम है, और क्षैतिज कट-ऑफ को परिभाषित करता है, एक उप सेट (हम पहले की पंक्तियों को बाहर कर सकते हैं); DateTimeTo उप सेट . में सबसे पहला है उत्पाद राज्यों की।
SELECT ProductId,
Description,
[DateFrom] = DateTime,
[DateTo] = (
SELECT MIN(DateTime) -- earliest in subset
FROM ProductStatus ps_inner
WHERE p.ProductId = ps_inner.ProductId -- our Product
AND ps_inner.DateTime > ps.DateTime -- defines subset, cutoff
)
FROM Product p,
ProductStatus ps
WHERE p.ProductId = ps.ProductId
AND StatusCode = 2 -- Request-
अगली पंक्ति प्राप्त करने . के संदर्भ में सोच रहे हैं पंक्ति-उन्मुख है, नहीं सेट-उन्मुख प्रसंस्करण। अपंग, सेट-उन्मुख डेटाबेस के साथ काम करते समय। ऑप्टिमाइज़र को वह सब करने दें जो आप सोच रहे हैं। अपने शोप्लान की जांच करें, यह खूबसूरती से अनुकूलित होता है।
-
सेट . में सोचने में असमर्थता , इस प्रकार केवल एकल-स्तरीय प्रश्नों को लिखने तक सीमित होने के कारण, इसका उचित औचित्य नहीं है:डेटाबेस में बड़े पैमाने पर दोहराव और अद्यतन विसंगतियों को लागू करना; ऑनलाइन संसाधनों और डिस्क स्थान को बर्बाद करना; आधे प्रदर्शन की गारंटी। आसानी से व्युत्पन्न डेटा प्राप्त करने के लिए सरल SQL उपश्रेणियों को लिखना सीखना बहुत सस्ता है।