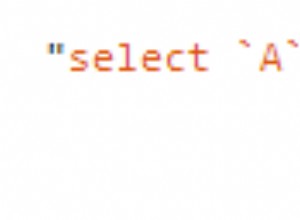
ऐसा प्रतीत होता है कि डेटा को BINARY . में संग्रहीत करना कॉलम खराब प्रदर्शन करने के लिए बाध्य दृष्टिकोण है। अच्छा प्रदर्शन पाने का एकमात्र तेज़ तरीका BINARY . की सामग्री को विभाजित करना है एकाधिक BIGINT . में कॉलम कॉलम, प्रत्येक में मूल डेटा का 8-बाइट सबस्ट्रिंग होता है।
मेरे मामले में (32 बाइट्स) इसका मतलब होगा 4 BIGINT . का उपयोग करना कॉलम और इस फ़ंक्शन का उपयोग करना:
CREATE FUNCTION HAMMINGDISTANCE(
A0 BIGINT, A1 BIGINT, A2 BIGINT, A3 BIGINT,
B0 BIGINT, B1 BIGINT, B2 BIGINT, B3 BIGINT
)
RETURNS INT DETERMINISTIC
RETURN
BIT_COUNT(A0 ^ B0) +
BIT_COUNT(A1 ^ B1) +
BIT_COUNT(A2 ^ B2) +
BIT_COUNT(A3 ^ B3);
इस दृष्टिकोण का उपयोग करना, मेरे परीक्षण में, BINARY . का उपयोग करने की तुलना में 100 गुना तेज है दृष्टिकोण।
एफडब्ल्यूआईडब्ल्यू, यह वह कोड है जिसे मैं समस्या की व्याख्या करते समय संकेत दे रहा था। एक ही चीज़ को पूरा करने के बेहतर तरीकों का स्वागत है (मैं विशेष रूप से बाइनरी> हेक्स> दशमलव रूपांतरण पसंद नहीं करता):
CREATE FUNCTION HAMMINGDISTANCE(A BINARY(32), B BINARY(32))
RETURNS INT DETERMINISTIC
RETURN
BIT_COUNT(
CONV(HEX(SUBSTRING(A, 1, 8)), 16, 10) ^
CONV(HEX(SUBSTRING(B, 1, 8)), 16, 10)
) +
BIT_COUNT(
CONV(HEX(SUBSTRING(A, 9, 8)), 16, 10) ^
CONV(HEX(SUBSTRING(B, 9, 8)), 16, 10)
) +
BIT_COUNT(
CONV(HEX(SUBSTRING(A, 17, 8)), 16, 10) ^
CONV(HEX(SUBSTRING(B, 17, 8)), 16, 10)
) +
BIT_COUNT(
CONV(HEX(SUBSTRING(A, 25, 8)), 16, 10) ^
CONV(HEX(SUBSTRING(B, 25, 8)), 16, 10)
);