उच्च उपलब्धता का निर्माण, एक बार में एक कदम
जब डेटाबेस इन्फ्रास्ट्रक्चर की बात आती है, तो हम सभी इसे चाहते हैं। हम सभी एक अत्यधिक उपलब्ध सेटअप बनाने का प्रयास करते हैं। अतिरेक कुंजी है। हम न्यूनतम स्तर पर अतिरेक को लागू करना शुरू करते हैं और स्टैक को जारी रखते हैं। यह हार्डवेयर से शुरू होता है - अनावश्यक बिजली की आपूर्ति, अनावश्यक शीतलन, हॉट-स्वैप डिस्क। नेटवर्क परत - कई एनआईसी एक साथ बंधे और विभिन्न स्विच से जुड़े जो अनावश्यक राउटर का उपयोग कर रहे हैं। भंडारण के लिए हम RAID में सेट डिस्क का उपयोग करते हैं, जो बेहतर प्रदर्शन देता है लेकिन अतिरेक भी देता है। फिर, सॉफ़्टवेयर स्तर पर, हम क्लस्टरिंग तकनीकों का उपयोग करते हैं:अतिरेक को लागू करने के लिए एक साथ काम करने वाले कई डेटाबेस नोड्स:MySQL क्लस्टर, गैलेरा क्लस्टर।
यह सब अच्छा नहीं है अगर आपके पास एक ही डेटासेंटर में सब कुछ है:जब कोई डेटासेंटर नीचे चला जाता है, या सेवाओं का हिस्सा (लेकिन महत्वपूर्ण) ऑफ़लाइन हो जाता है, या यहां तक कि अगर आप डेटासेंटर से कनेक्टिविटी खो देते हैं, तो आपकी सेवा नीचे चली जाएगी - निचले स्तरों में अतिरेक की मात्रा से कोई फर्क नहीं पड़ता। और हाँ, वे चीज़ें होती हैं।
- S3 सेवा व्यवधान ने फरवरी, 2017 में यूएस-ईस्ट-1 क्षेत्र में कहर बरपाया
- अप्रैल, 2011 में यूएस-पूर्वी क्षेत्र में EC2 और RDS सेवा व्यवधान
- EC2, EBS और RDS अगस्त, 2011 में EU-पश्चिम क्षेत्र में बाधित हो गए थे
- जून, 2009 में बिजली गुल होने से रैकस्पेस टेक्सास डीसी बंद हो गया
- यूपीएस की विफलता के कारण जनवरी, 2010 में सैकड़ों सर्वर रैकस्पेस लंदन डीसी में ऑफ़लाइन हो गए
यह किसी भी तरह से विफलताओं की पूरी सूची नहीं है, यह केवल एक त्वरित Google खोज का परिणाम है। ये उदाहरण के रूप में काम करते हैं कि यदि आप अपने सभी अंडे एक ही टोकरी में रख देते हैं तो चीजें गलत हो सकती हैं और हो सकती हैं। एक और उदाहरण तूफान सैंडी होगा, जिसके कारण यूएस-ईस्ट से यूएस-वेस्ट डीसी तक डेटा का भारी पलायन हुआ - उस समय आप यूएस-वेस्ट में उदाहरणों को शायद ही स्पिन कर सकते थे क्योंकि हर कोई उम्मीद में अपने बुनियादी ढांचे को दूसरे तट पर ले जाने के लिए दौड़ा था। कि उत्तरी वर्जीनिया डीसी मौसम से गंभीर रूप से प्रभावित होगा।
इसलिए, यदि आप एक उच्च उपलब्धता वातावरण बनाना चाहते हैं तो मल्टी-डेटासेंटर सेटअप आवश्यक हैं। इस ब्लॉग पोस्ट में, हम चर्चा करेंगे कि MySQL/MariaDB के लिए गैलेरा क्लस्टर का उपयोग करके इस तरह के बुनियादी ढांचे का निर्माण कैसे किया जाए।
गैलेरा कॉन्सेप्ट
इससे पहले कि हम विशेष समाधानों पर गौर करें, आइए दो अवधारणाओं को समझाने में कुछ समय बिताएं जो अत्यधिक उपलब्ध, मल्टी-डीसी गैलेरा सेटअप में बहुत महत्वपूर्ण हैं।
कोरम
उच्च उपलब्धता के लिए संसाधनों की आवश्यकता होती है - अर्थात्, इसे अत्यधिक उपलब्ध कराने के लिए आपको क्लस्टर में कई नोड्स की आवश्यकता होती है। एक समूह अपने कुछ सदस्यों के नुकसान को सहन कर सकता है, लेकिन केवल एक निश्चित सीमा तक। एक निश्चित विफलता दर से परे, आप एक विभाजित मस्तिष्क परिदृश्य देख रहे होंगे।
आइए 2 नोड सेटअप के साथ एक उदाहरण लें। यदि एक नोड नीचे चला जाता है, तो दूसरे को कैसे पता चलेगा कि उसका पीयर क्रैश हो गया है और यह नेटवर्क विफलता नहीं है? उस स्थिति में, दूसरा नोड भी ट्रैफ़िक की सेवा करते हुए ऊपर और चल रहा हो सकता है। ऐसे मामले को संभालने का कोई अच्छा तरीका नहीं है… यही कारण है कि दोष सहिष्णुता आमतौर पर तीन नोड्स से शुरू होती है। गैलेरा कोरम गणना का उपयोग यह निर्धारित करने के लिए करता है कि क्या यह क्लस्टर के लिए यातायात को संभालने के लिए सुरक्षित है, या यदि इसे संचालन बंद कर देना चाहिए। एक विफलता के बाद, सभी शेष नोड्स एक दूसरे से जुड़ने का प्रयास करते हैं और यह निर्धारित करते हैं कि उनमें से कितने ऊपर हैं। फिर इसकी तुलना क्लस्टर की पिछली स्थिति से की जाती है, और जब तक 50% से अधिक नोड्स ऊपर होते हैं, तब तक क्लस्टर काम करना जारी रख सकता है।
इसका परिणाम निम्न होता है:
2 नोड क्लस्टर - कोई दोष सहिष्णुता नहीं
3 नोड क्लस्टर - 1 क्रैश तक
4 नोड क्लस्टर - 1 क्रैश तक (यदि दो नोड क्रैश हो जाते हैं, तो केवल 50% क्लस्टर उपलब्ध होगा, आपको जीवित रहने के लिए 50% से अधिक नोड्स की आवश्यकता है)
5 नोड क्लस्टर - 2 क्रैश तक
6 नोड क्लस्टर - 2 क्रैश तक
आप शायद पैटर्न देखते हैं - आप चाहते हैं कि आपके क्लस्टर में विषम संख्या में नोड्स हों - उच्च उपलब्धता के संदर्भ में क्लस्टर में 5 से 6 नोड्स में जाने का कोई मतलब नहीं है। यदि आप बेहतर दोष सहनशीलता चाहते हैं, तो आपको 7 नोड्स के लिए जाना चाहिए।
सेगमेंट
आमतौर पर, गैलेरा क्लस्टर में, सभी संचार सभी से सभी पैटर्न का अनुसरण करते हैं। प्रत्येक नोड क्लस्टर में अन्य सभी नोड्स से बात करता है।
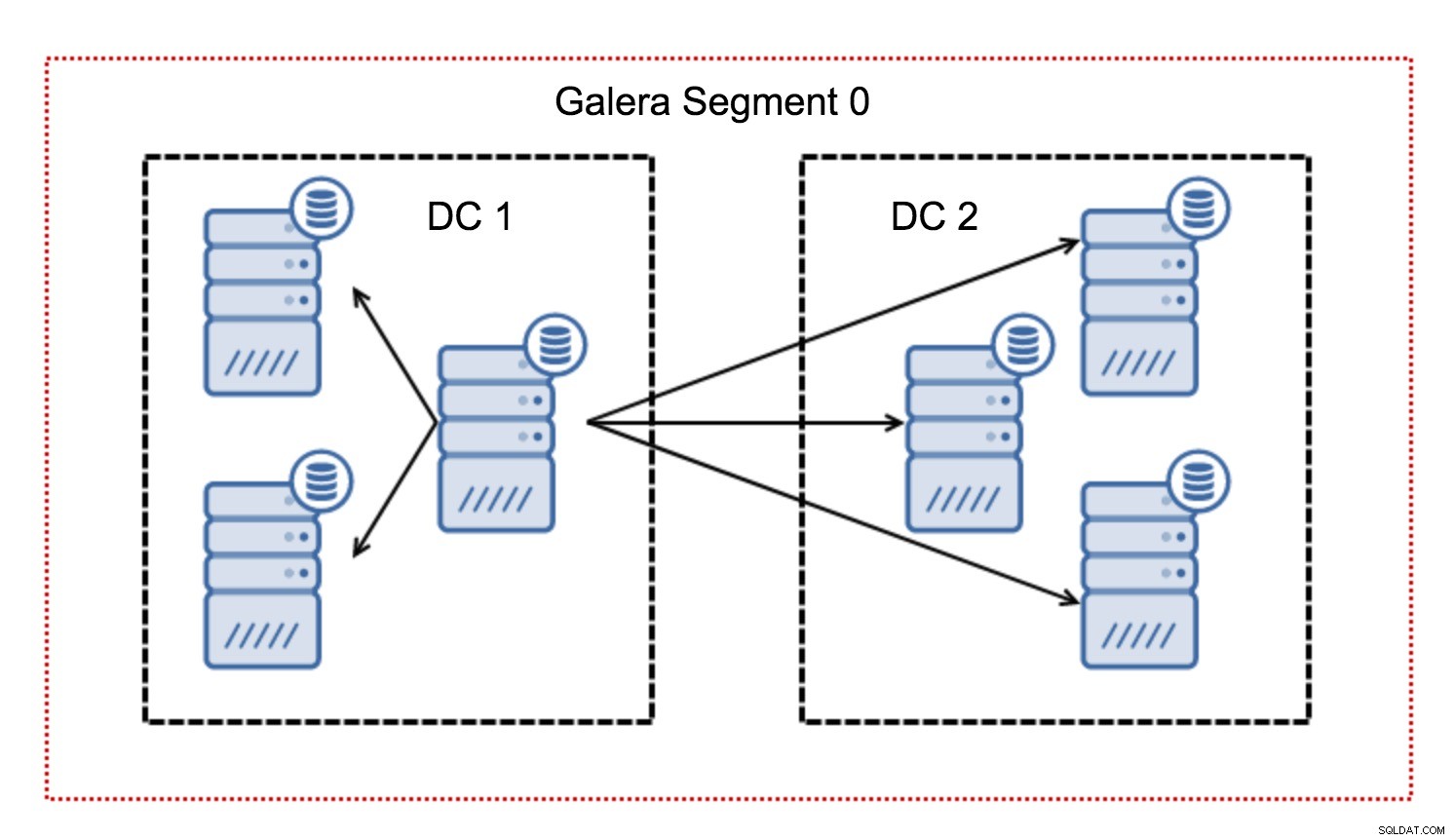
जैसा कि आप जानते हैं, गैलेरा में प्रत्येक राइटसेट को क्लस्टर के सभी नोड्स द्वारा प्रमाणित किया जाना है - इसलिए नोड पर होने वाले प्रत्येक लेखन को क्लस्टर के सभी नोड्स में स्थानांतरित किया जाना है। यह कम विलंबता वाले वातावरण में ठीक काम करता है। लेकिन अगर हम मल्टी-डीसी सेटअप के बारे में बात कर रहे हैं, तो हमें स्थानीय नेटवर्क की तुलना में बहुत अधिक विलंबता पर विचार करने की आवश्यकता है। वाइड एरिया नेटवर्क पर फैले क्लस्टर में इसे और अधिक सहने योग्य बनाने के लिए, गैलेरा ने सेगमेंट पेश किए।
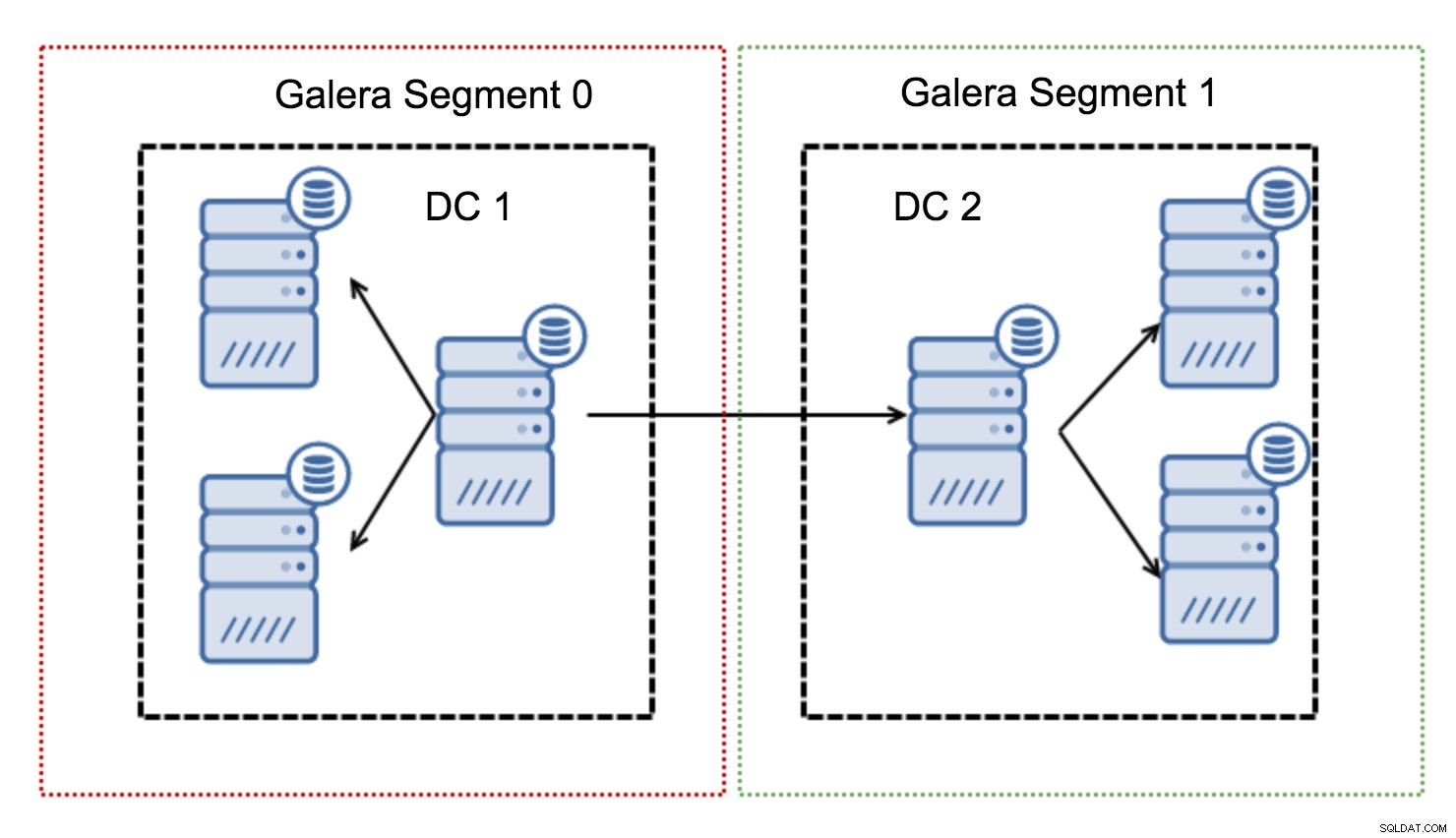
वे नोड्स (सेगमेंट) के समूह के भीतर गैलेरा ट्रैफ़िक को समाहित करके काम करते हैं। एक खंड के भीतर सभी नोड्स कार्य करते हैं जैसे कि वे एक स्थानीय नेटवर्क में थे - वे सभी संचारों में से एक मानते हैं। क्रॉस-सेगमेंट ट्रैफ़िक के लिए, चीजें अलग हैं - प्रत्येक सेगमेंट में, एक "रिले" नोड चुना जाता है, सभी क्रॉस-सेगमेंट ट्रैफ़िक उन नोड्स से होकर जाता है। जब एक रिले नोड नीचे जाता है, तो दूसरा नोड चुना जाता है। यह विलंबता को बहुत कम नहीं करता है - आखिरकार, WAN विलंबता समान रहेगी, भले ही आप एक दूरस्थ होस्ट या कई दूरस्थ होस्ट से संबंध बनाते हों, लेकिन यह देखते हुए कि WAN लिंक बैंडविड्थ में सीमित होते हैं और हो सकता है स्थानांतरित किए गए डेटा की मात्रा के लिए शुल्क, ऐसा दृष्टिकोण आपको खंडों के बीच आदान-प्रदान किए गए डेटा की मात्रा को सीमित करने की अनुमति देता है। एक और समय और लागत-बचत विकल्प यह तथ्य है कि एक ही खंड में नोड्स को प्राथमिकता दी जाती है जब एक दाता की आवश्यकता होती है - फिर से, यह WAN पर स्थानांतरित डेटा की मात्रा को सीमित करता है और, सबसे अधिक संभावना है, स्थानीय नेटवर्क के रूप में लगभग हमेशा एसएसटी को गति देता है WAN लिंक से तेज़ होगा।
अब जबकि हमें इनमें से कुछ अवधारणाएं खत्म हो गई हैं, आइए गैलेरा क्लस्टर के लिए मल्टी-डीसी सेटअप के कुछ अन्य महत्वपूर्ण पहलुओं पर नजर डालते हैं।
ऐसी समस्याएं जिनका आप सामना करने वाले हैं
WAN में फैले वातावरण में काम करते समय, कुछ ऐसे मुद्दे हैं जिन पर आपको अपने परिवेश को डिज़ाइन करते समय विचार करने की आवश्यकता है।
कोरम गणना
पिछले खंड में, हमने वर्णन किया था कि गैलेरा क्लस्टर में कोरम गणना कैसी दिखती है - संक्षेप में, आप जीवित रहने को अधिकतम करने के लिए विषम संख्या में नोड्स रखना चाहते हैं। मल्टी-डीसी सेटअप में यह सब अभी भी सही है, लेकिन मिश्रण में कुछ और तत्व जोड़े गए हैं। सबसे पहले, आपको यह तय करने की आवश्यकता है कि क्या आप चाहते हैं कि गैलेरा स्वचालित रूप से डेटासेंटर विफलता को संभाले। यह निर्धारित करेगा कि आप कितने डेटासेंटर का उपयोग करने जा रहे हैं। आइए दो डीसी की कल्पना करें - यदि आप अपने नोड्स को 50% - 50% विभाजित करेंगे, यदि एक डेटासेंटर नीचे चला जाता है, तो दूसरे के पास अपनी "प्राथमिक" स्थिति बनाए रखने के लिए 50% + 1 नोड नहीं है। यदि आप अपने नोड्स को असमान तरीके से विभाजित करते हैं, तो उनमें से अधिकांश का उपयोग "मुख्य" डेटासेंटर में करते हैं, जब वह डेटासेंटर नीचे चला जाता है, तो "बैकअप" डीसी में कोरम बनाने के लिए 50% + 1 नोड्स नहीं होंगे। आप नोड्स को अलग-अलग वज़न असाइन कर सकते हैं लेकिन परिणाम बिल्कुल वही होगा - मैन्युअल हस्तक्षेप के बिना दो डीसी के बीच स्वचालित रूप से विफल होने का कोई तरीका नहीं है। स्वचालित विफलता को लागू करने के लिए, आपको दो से अधिक DC की आवश्यकता है। फिर से, आदर्श रूप से एक विषम संख्या - तीन डेटासेंटर पूरी तरह से ठीक सेटअप है। अगला, सवाल यह है - आपके पास कितने नोड्स होने चाहिए? आप चाहते हैं कि उन्हें डेटासेंटर में समान रूप से वितरित किया जाए। बाकी केवल इस बात की बात है कि आपके सेटअप को कितने विफल नोड्स को संभालना है।
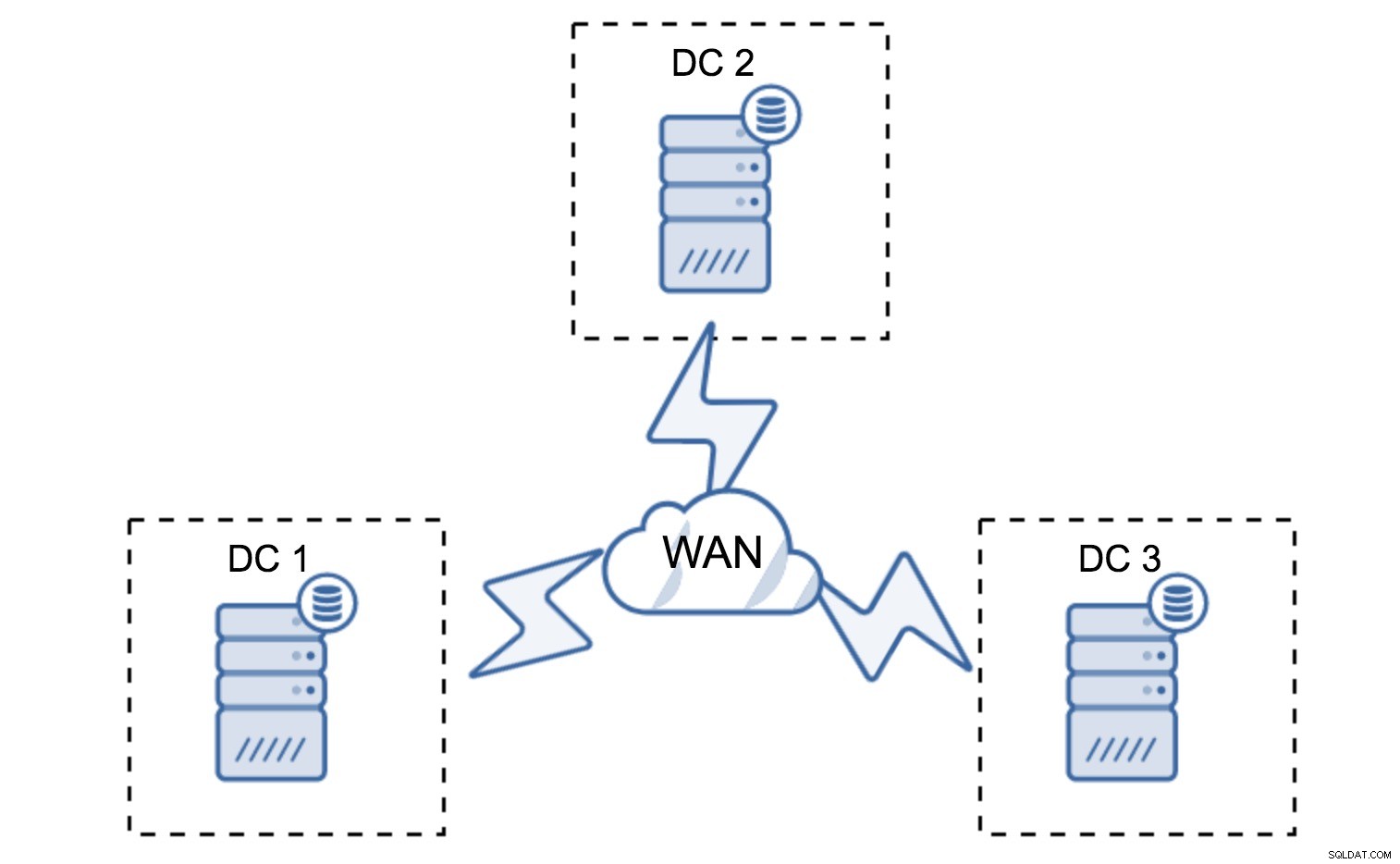
न्यूनतम सेटअप प्रति डेटासेंटर एक नोड का उपयोग करेगा - हालांकि इसमें गंभीर कमियां हैं। प्रत्येक राज्य हस्तांतरण के लिए WAN में डेटा स्थानांतरित करने की आवश्यकता होगी और इसके परिणामस्वरूप SST या उच्च लागतों को पूरा करने के लिए अधिक समय की आवश्यकता होगी।
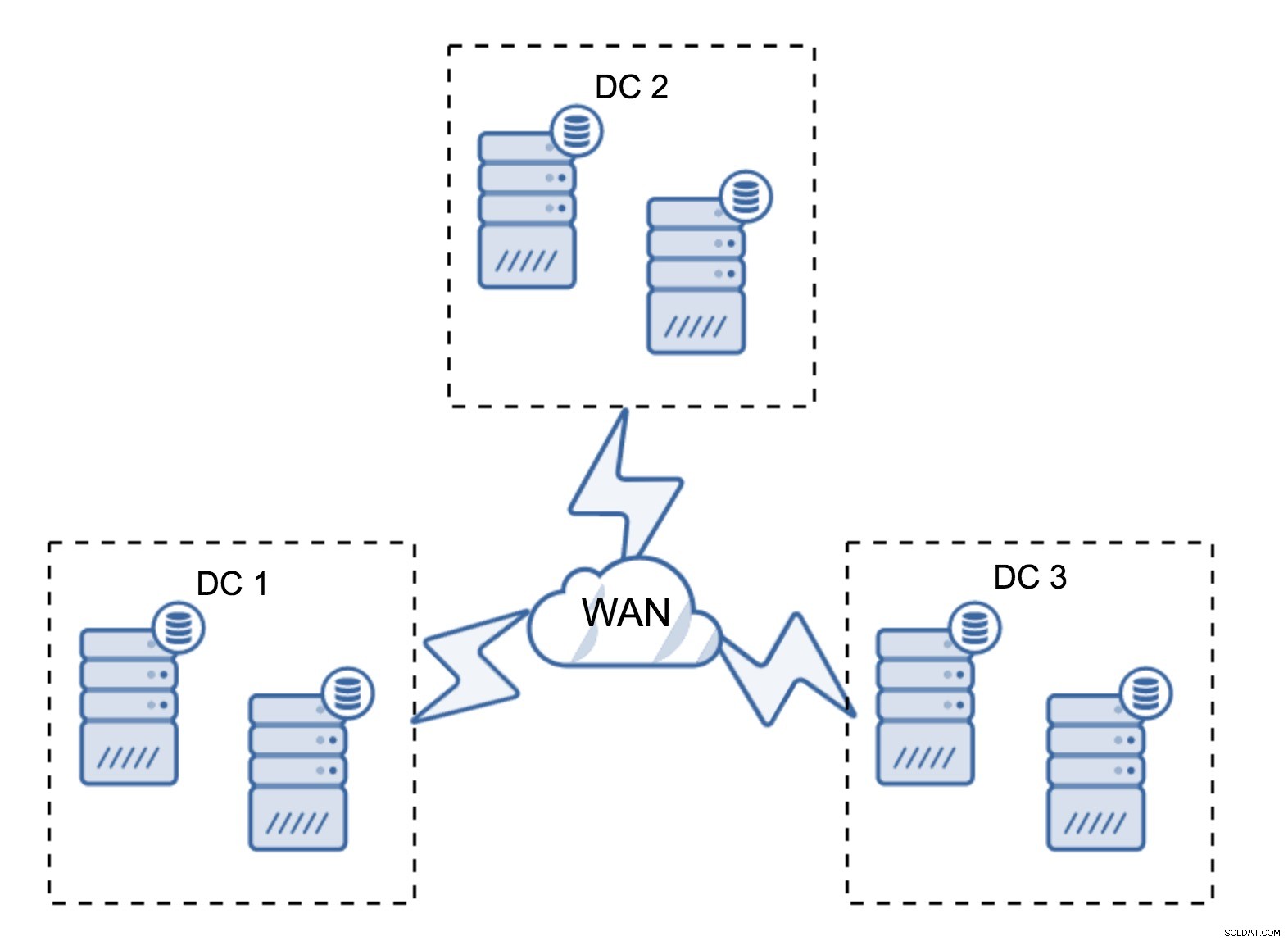
काफी विशिष्ट सेटअप में छह नोड्स, दो प्रति डेटासेंटर होना चाहिए। यह सेटअप अप्रत्याशित लगता है क्योंकि इसमें नोड्स की संख्या सम है। लेकिन, जब आप इसके बारे में सोचते हैं, तो यह इतना बड़ा मुद्दा नहीं हो सकता है:यह बहुत कम संभावना है कि तीन नोड्स एक साथ नीचे जाएंगे, और ऐसा सेटअप दो नोड्स तक के क्रैश से बच जाएगा। एक संपूर्ण डाटासेंटर ऑफ़लाइन हो सकता है और शेष दो डीसी परिचालन जारी रखेंगे। न्यूनतम सेटअप पर भी इसका बहुत बड़ा फायदा है - जब कोई नोड ऑफ़लाइन हो जाता है, तो डेटासेंटर में हमेशा एक दूसरा नोड होता है जो दाता के रूप में काम कर सकता है। अधिकांश समय, WAN का उपयोग SST के लिए नहीं किया जाएगा।
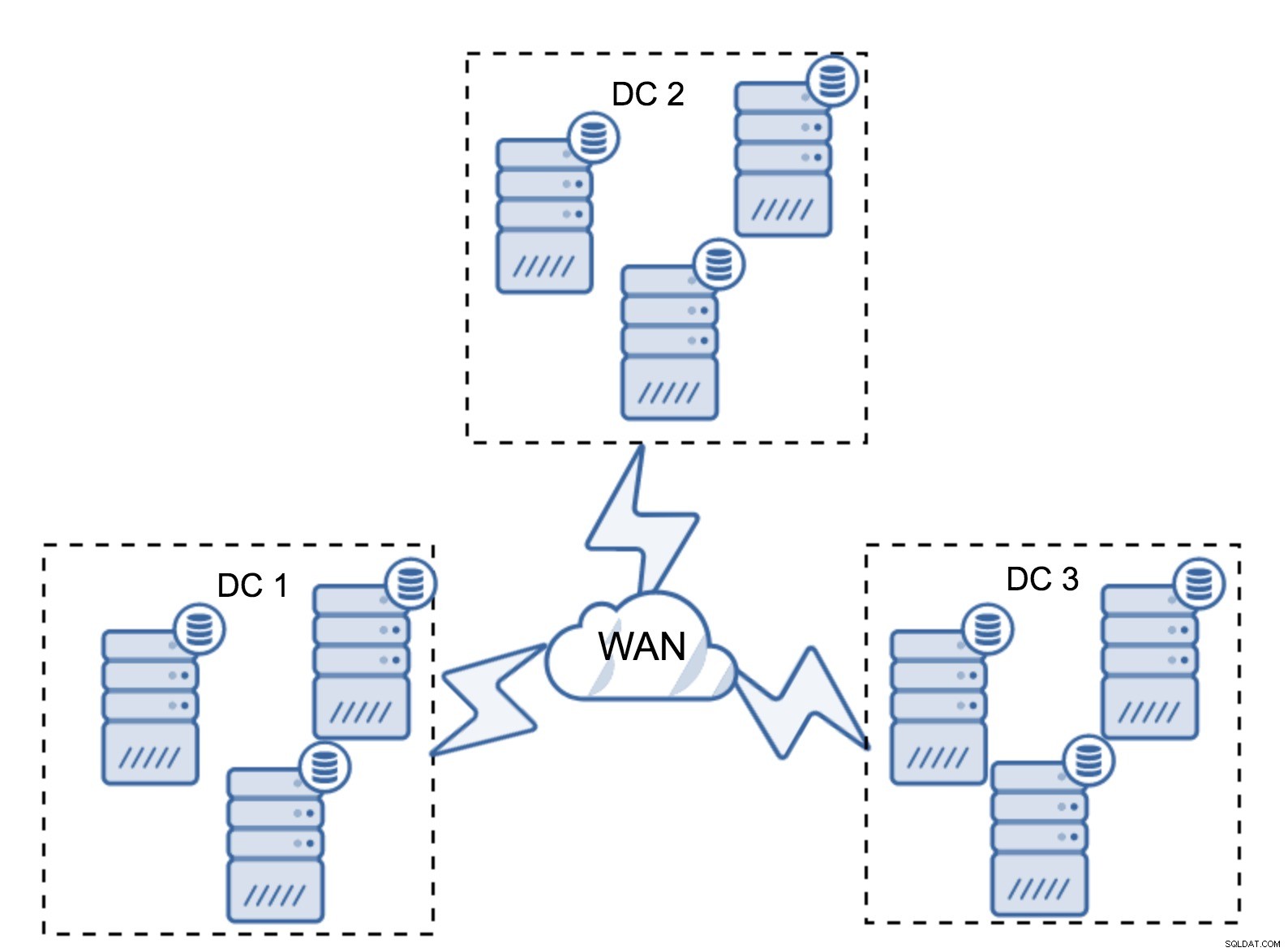
बेशक, आप नोड्स की संख्या तीन प्रति क्लस्टर, कुल नौ तक बढ़ा सकते हैं। यह आपको और भी बेहतर उत्तरजीविता देता है:अधिकतम चार नोड क्रैश हो सकते हैं और क्लस्टर अभी भी जीवित रहेगा। दूसरी ओर, आपको यह ध्यान रखना होगा कि, सेगमेंट के उपयोग के साथ भी, अधिक नोड्स का अर्थ है संचालन के उच्च ओवरहेड और आप गैलेरा क्लस्टर को केवल एक निश्चित सीमा तक ही बढ़ा सकते हैं।
ऐसा हो सकता है कि तीसरे डेटासेंटर की कोई आवश्यकता नहीं है, क्योंकि मान लीजिए, आपका एप्लिकेशन उनमें से केवल दो में स्थित है। बेशक, तीन डेटासेंटर की आवश्यकता अभी भी मान्य है, इसलिए आप इसके आसपास नहीं जाएंगे, लेकिन पूरी तरह से लोड किए गए डेटाबेस सर्वर के बजाय गैलेरा आर्बिट्रेटर (गारबड) का उपयोग करना बिल्कुल ठीक है।
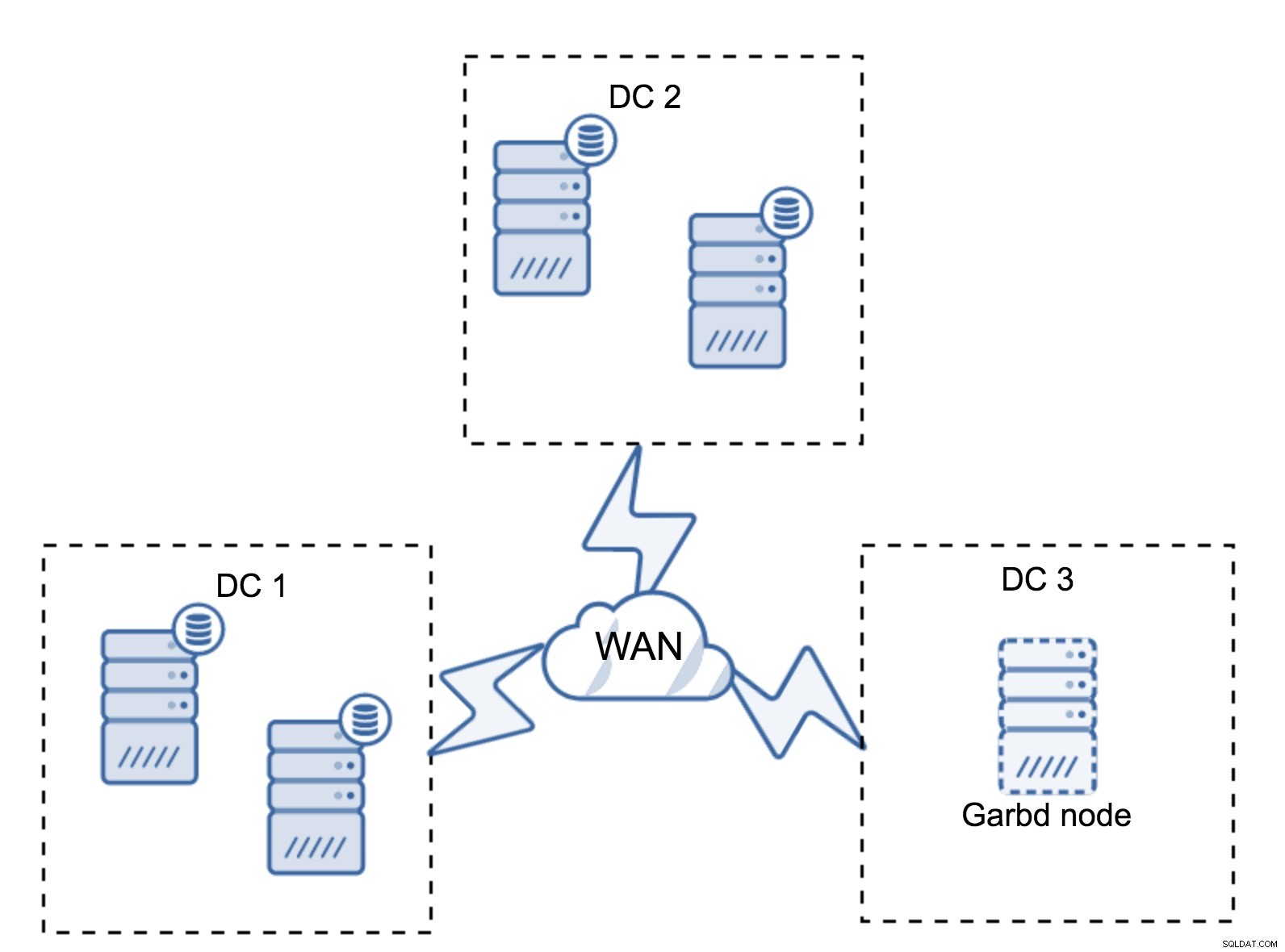
Garbd को छोटे नोड्स, यहां तक कि वर्चुअल सर्वर पर भी स्थापित किया जा सकता है। इसके लिए शक्तिशाली हार्डवेयर की आवश्यकता नहीं है, यह कोई डेटा संग्रहीत नहीं करता है और न ही कोई राइटसेट लागू करता है। लेकिन यह सभी प्रतिकृति यातायात को देखता है, और कोरम गणना में भाग लेता है। इसके लिए धन्यवाद, आप चार नोड्स जैसे सेटअप को तैनात कर सकते हैं, तीसरे में दो डीसी + गारबड - आपके पास कुल पांच नोड हैं, और ऐसा क्लस्टर दो विफलताओं को स्वीकार कर सकता है। तो इसका मतलब है कि यह किसी एक डेटासेंटर के पूर्ण शटडाउन को स्वीकार कर सकता है।
आपके लिए कौन सा विकल्प बेहतर है? सभी मामलों के लिए कोई सबसे अच्छा समाधान नहीं है, यह सब आपके बुनियादी ढांचे की आवश्यकताओं पर निर्भर करता है। सौभाग्य से, चुनने के लिए अलग-अलग विकल्प हैं:कम या ज्यादा नोड्स, पूर्ण 3 डीसी या 2 डीसी और तीसरे में गारबड - यह काफी संभावना है कि आप अपने लिए कुछ उपयुक्त पाएंगे।
नेटवर्क विलंबता
मल्टी-डीसी सेटअप के साथ काम करते समय, आपको यह ध्यान रखना होगा कि नेटवर्क विलंबता स्थानीय नेटवर्क वातावरण से आपकी अपेक्षा से काफी अधिक होगी। जब आप इसकी तुलना स्टैंडअलोन MySQL इंस्टेंस या MySQL प्रतिकृति सेटअप से करते हैं तो यह गैलेरा क्लस्टर के प्रदर्शन को गंभीरता से कम कर सकता है। आवश्यकता है कि सभी नोड्स को एक राइटसेट प्रमाणित करना होगा, इसका मतलब है कि सभी नोड्स को इसे प्राप्त करना होगा, चाहे वे कितनी भी दूर हों। अतुल्यकालिक प्रतिकृति के साथ, प्रतिबद्ध होने से पहले प्रतीक्षा करने की कोई आवश्यकता नहीं है। बेशक, प्रतिकृति में अन्य मुद्दे और कमियां हैं, लेकिन विलंबता प्रमुख नहीं है। समस्या विशेष रूप से तब दिखाई देती है जब आपके डेटाबेस में हॉट स्पॉट - पंक्तियाँ होती हैं, जिन्हें अक्सर अपडेट किया जाता है (काउंटर, कतार, आदि)। उन पंक्तियों को प्रति नेटवर्क राउंड ट्रिप में एक से अधिक बार अपडेट नहीं किया जा सकता है। दुनिया भर में फैले समूहों के लिए, इसका आसानी से मतलब यह हो सकता है कि आप एक पंक्ति को प्रति सेकंड 2-3 बार से अधिक बार अपडेट करने में सक्षम नहीं होंगे। यदि यह आपके लिए एक सीमा बन जाता है, तो इसका मतलब यह हो सकता है कि गैलेरा क्लस्टर आपके विशेष कार्यभार के लिए उपयुक्त नहीं है।
मल्टी-डीसी गैलेरा क्लस्टर में प्रॉक्सी परत
कई डेटा केंद्रों में फैले गैलेरा क्लस्टर के लिए पर्याप्त नहीं है, फिर भी आपको उन तक पहुंचने के लिए अपने आवेदन की आवश्यकता है। किसी एप्लिकेशन से डेटाबेस परत की जटिलता को छिपाने के लोकप्रिय तरीकों में से एक प्रॉक्सी का उपयोग करना है। प्रॉक्सी का उपयोग डेटाबेस में प्रवेश बिंदु के रूप में किया जाता है, वे डेटाबेस नोड्स की स्थिति को ट्रैक करते हैं और हमेशा केवल उपलब्ध नोड्स पर ट्रैफ़िक को निर्देशित करना चाहिए। इस खंड में, हम एक प्रॉक्सी लेयर डिज़ाइन का प्रस्ताव करने का प्रयास करेंगे जिसका उपयोग मल्टी-डीसी गैलेरा क्लस्टर के लिए किया जा सकता है। हम ProxySQL का उपयोग करेंगे, जो आपको डेटाबेस नोड्स को संभालने में काफी लचीलापन देता है, लेकिन जब तक यह गैलेरा नोड्स की स्थिति को ट्रैक कर सकता है, तब तक आप किसी अन्य प्रॉक्सी का उपयोग कर सकते हैं।
प्रॉक्सी का पता कहां लगाएं?
संक्षेप में, यहां दो सामान्य पैटर्न हैं:आप या तो प्रॉक्सीएसक्यूएल को एक अलग नोड्स पर तैनात कर सकते हैं या आप उन्हें एप्लिकेशन होस्ट पर तैनात कर सकते हैं। आइए इनमें से प्रत्येक सेटअप के पेशेवरों और विपक्षों पर एक नज़र डालें।
होस्ट के अलग सेट के रूप में प्रॉक्सी परत
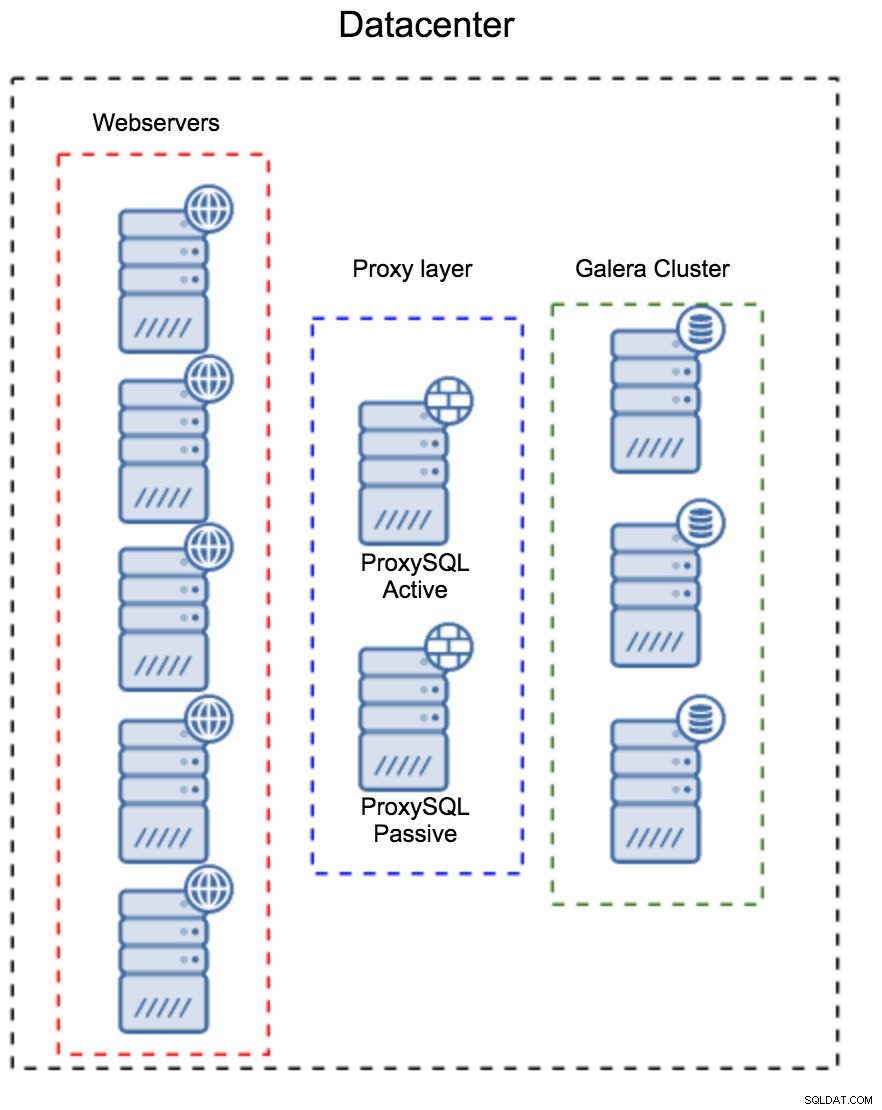
पहला पैटर्न अलग, समर्पित मेजबानों का उपयोग करके एक प्रॉक्सी परत बनाना है। आप प्रॉक्सीएसक्यूएल को कुछ मेजबानों पर तैनात कर सकते हैं, और वर्चुअल आईपी का उपयोग कर सकते हैं और उच्च उपलब्धता बनाए रखने के लिए रख सकते हैं। एक एप्लिकेशन डेटाबेस से कनेक्ट करने के लिए VIP का उपयोग करेगा, और VIP यह सुनिश्चित करेगा कि अनुरोध हमेशा उपलब्ध ProxySQL पर भेजे जाएंगे। इस सेटअप के साथ मुख्य समस्या यह है कि आप प्रॉक्सीएसक्यूएल इंस्टेंस में से अधिकांश का उपयोग करते हैं - सभी स्टैंडबाय नोड्स का उपयोग ट्रैफ़िक को रूट करने के लिए नहीं किया जाता है। यह आपको आम तौर पर उपयोग किए जाने वाले हार्डवेयर से अधिक शक्तिशाली हार्डवेयर का उपयोग करने के लिए मजबूर कर सकता है। दूसरी ओर, सेटअप को बनाए रखना आसान है - आपको सभी प्रॉक्सीएसक्यूएल नोड्स पर कॉन्फ़िगरेशन परिवर्तन लागू करना होगा, लेकिन उनमें से कुछ ही मुट्ठी भर होंगे। आप नोड्स को सिंक करने के लिए क्लस्टरकंट्रोल के विकल्प का भी उपयोग कर सकते हैं। इस तरह के सेटअप को आपके द्वारा उपयोग किए जाने वाले प्रत्येक डेटासेंटर पर डुप्लिकेट करना होगा।
एप्लिकेशन इंस्टेंस पर स्थापित प्रॉक्सी
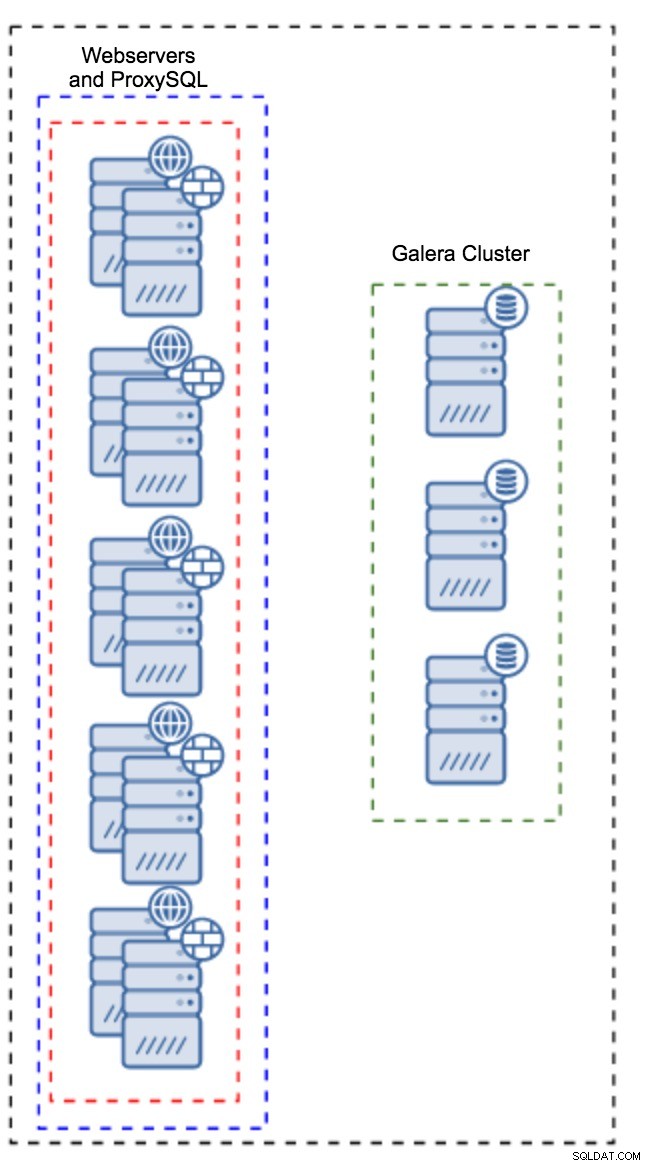
मेजबानों का एक अलग सेट होने के बजाय, प्रॉक्सीएसक्यूएल को एप्लिकेशन होस्ट पर भी स्थापित किया जा सकता है। एप्लिकेशन लोकलहोस्ट पर सीधे प्रॉक्सीएसक्यूएल से कनेक्ट होगा, यह टीसीपी कनेक्शन के ओवरहेड को कम करने के लिए यूनिक्स सॉकेट का भी उपयोग कर सकता है। इस तरह के सेटअप का मुख्य लाभ यह है कि आपके पास बड़ी संख्या में ProxySQL इंस्टेंस हैं, और लोड समान रूप से उन पर वितरित किया जाता है। यदि कोई नीचे जाता है, तो केवल वह एप्लिकेशन होस्ट प्रभावित होगा। शेष नोड्स काम करना जारी रखेंगे। सामना करने के लिए सबसे गंभीर समस्या कॉन्फ़िगरेशन प्रबंधन है। बड़ी संख्या में ProxySQL नोड्स के साथ, उनके कॉन्फ़िगरेशन को सिंक में रखने की एक स्वचालित विधि के साथ आना महत्वपूर्ण है। आप ClusterControl, या कठपुतली जैसे कॉन्फ़िगरेशन प्रबंधन टूल का उपयोग कर सकते हैं।
गैलेरा को WAN परिवेश में ट्यून करना
गैलेरा डिफॉल्ट्स को स्थानीय नेटवर्क के लिए डिज़ाइन किया गया है और यदि आप इसे WAN वातावरण में उपयोग करना चाहते हैं, तो कुछ ट्यूनिंग की आवश्यकता होती है। आइए कुछ बुनियादी ट्वीक्स पर चर्चा करें जो आप कर सकते हैं। कृपया ध्यान रखें कि सटीक ट्यूनिंग के लिए उत्पादन डेटा और ट्रैफ़िक की आवश्यकता होती है - आप केवल कुछ बदलाव नहीं कर सकते हैं और मान सकते हैं कि वे अच्छे हैं, आपको उचित बेंचमार्किंग करनी चाहिए।
ऑपरेटिंग सिस्टम कॉन्फ़िगरेशन
आइए ऑपरेटिंग सिस्टम कॉन्फ़िगरेशन के साथ शुरू करें। यहां प्रस्तावित सभी संशोधन WAN से संबंधित नहीं हैं, लेकिन खुद को यह याद दिलाना हमेशा अच्छा होता है कि किसी भी MySQL स्थापना के लिए एक अच्छा प्रारंभिक बिंदु क्या है।
vm.swappiness = 1स्वैपनेस नियंत्रित करता है कि ऑपरेटिंग सिस्टम स्वैप का कितना आक्रामक उपयोग करेगा। इसे शून्य पर सेट नहीं किया जाना चाहिए क्योंकि हाल के कर्नेल में, यह OS को स्वैप का उपयोग करने से बिल्कुल भी रोकता है और यह गंभीर प्रदर्शन समस्याओं का कारण बन सकता है।
/sys/block/*/queue/scheduler = deadline/noopब्लॉक डिवाइस के लिए शेड्यूलर, जिसका उपयोग MySQL करता है, को या तो समय सीमा या noop पर सेट किया जाना चाहिए। सटीक विकल्प बेंचमार्क पर निर्भर करता है लेकिन दोनों सेटिंग्स को समान प्रदर्शन प्रदान करना चाहिए, डिफ़ॉल्ट शेड्यूलर, CFQ से बेहतर।
MySQL के लिए, आपको कर्नेल के आधार पर EXT4 या XFS का उपयोग करने पर विचार करना चाहिए (उन फाइल सिस्टम का प्रदर्शन एक कर्नेल संस्करण से दूसरे में बदलता है)। अपने लिए बेहतर विकल्प खोजने के लिए कुछ बेंचमार्क करें।
इसके अतिरिक्त, आप sysctl नेटवर्क सेटिंग्स को देखना चाह सकते हैं। हम उनके बारे में विस्तार से चर्चा नहीं करेंगे (आप यहां प्रलेखन पा सकते हैं) लेकिन सामान्य विचार बफ़र्स, बैकलॉग और टाइमआउट को बढ़ाना है, जिससे स्टालों और अस्थिर WAN लिंक को समायोजित करना आसान हो सके।
net.core.optmem_max = 40960
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.rmem_default = 16777216
net.core.wmem_default = 16777216
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 87380 16777216
net.core.netdev_max_backlog = 50000
net.ipv4.tcp_max_syn_backlog = 30000
net.ipv4.tcp_congestion_control = htcp
net.ipv4.tcp_mtu_probing = 1
net.ipv4.tcp_max_tw_buckets = 2000000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_slow_start_after_idle = 0OS ट्यूनिंग के अलावा आपको Galera नेटवर्क से संबंधित सेटिंग्स में बदलाव करने पर विचार करना चाहिए।
evs.suspect_timeout
evs.inactive_timeoutआप इन चरों के डिफ़ॉल्ट मानों को बदलने पर विचार कर सकते हैं। दोनों टाइमआउट नियंत्रित करते हैं कि कैसे क्लस्टर विफल नोड्स को बेदखल करता है। संदिग्ध टाइमआउट तब होता है जब सभी नोड्स निष्क्रिय सदस्य तक नहीं पहुंच सकते। निष्क्रिय टाइमआउट एक कठिन सीमा को परिभाषित करता है कि नोड कितने समय तक क्लस्टर में रह सकता है यदि यह प्रतिक्रिया नहीं दे रहा है। आमतौर पर आप पाएंगे कि डिफ़ॉल्ट मान अच्छी तरह से काम करते हैं। लेकिन कुछ मामलों में, खासकर यदि आप अपना गैलेरा क्लस्टर WAN (उदाहरण के लिए, AWS क्षेत्रों के बीच) पर चलाते हैं, तो उन चरों को बढ़ाने से अधिक स्थिर प्रदर्शन हो सकता है। हम दोनों को PT1M पर सेट करने का सुझाव देंगे, ताकि इस बात की संभावना कम हो जाए कि WAN लिंक अस्थिरता एक नोड को क्लस्टर से बाहर कर देगी।
evs.send_window
evs.user_send_windowये चर, evs.send_window और evs.user_send_window , परिभाषित करें कि एक ही समय में प्रतिकृति के माध्यम से कितने पैकेट भेजे जा सकते हैं (evs.send_window ) और उनमें से कितने में डेटा हो सकता है (evs.user_send_window ) उच्च विलंबता कनेक्शन के लिए, उन मानों को उल्लेखनीय रूप से बढ़ाना उचित हो सकता है (उदाहरण के लिए 512 या 1024)।
evs.inactive_check_periodउपरोक्त चर को भी बदला जा सकता है। evs.inactive_check_period , डिफ़ॉल्ट रूप से, एक सेकंड पर सेट होता है, जो कि WAN सेटअप के लिए बहुत अधिक हो सकता है। हम इसे PT30S पर सेट करने का सुझाव देंगे।
gcs.fc_factor
gcs.fc_limitयहां हम उन अवसरों को कम करना चाहते हैं जिनसे प्रवाह नियंत्रण शुरू हो जाएगा, इसलिए हम gcs.fc_factor सेट करने का सुझाव देंगे। 1 तक और बढ़ाएँ gcs.fc_limit करने के लिए, उदाहरण के लिए, 260।
gcs.max_packet_sizeचूंकि हम WAN लिंक के साथ काम कर रहे हैं, जहां विलंबता काफी अधिक है, हम पैकेट का आकार बढ़ाना चाहते हैं। एक अच्छा शुरुआती बिंदु 2097152 होगा।
जैसा कि हमने पहले उल्लेख किया है, इन मापदंडों को कैसे सेट किया जाए, इस पर एक सरल नुस्खा देना लगभग असंभव है क्योंकि यह बहुत सारे कारकों पर निर्भर करता है - आपको अपने उत्पादन डेटा के जितना संभव हो सके, डेटा का उपयोग करके अपने स्वयं के बेंचमार्क करना होगा। कह सकते हैं कि आपका सिस्टम ट्यून है। ऐसा कहने के बाद, उन सेटिंग्स को आपको अधिक सटीक ट्यूनिंग के लिए एक प्रारंभिक बिंदु देना चाहिए।
अभी के लिए बस इतना ही। गैलेरा WAN वातावरण में बहुत अच्छी तरह से काम करता है, इसलिए इसे आज़माएं और हमें बताएं कि आप कैसे आगे बढ़ते हैं।