MongoDB जादुई रूप से तेज़ नहीं है। यदि आप समान डेटा संग्रहीत करते हैं, मूल रूप से एक ही फैशन में व्यवस्थित होते हैं, और इसे ठीक उसी तरह एक्सेस करते हैं, तो आपको वास्तव में अपने परिणामों के बेतहाशा भिन्न होने की उम्मीद नहीं करनी चाहिए। आखिरकार, MySQL और MongoDB दोनों GPL हैं, इसलिए यदि Mongo में कुछ जादुई रूप से बेहतर IO कोड होता, तो MySQL टीम इसे अपने कोडबेस में शामिल कर सकती थी।
लोग वास्तविक दुनिया MongoDB प्रदर्शन को बड़े पैमाने पर देख रहे हैं क्योंकि MongoDB आपको एक अलग तरीके से क्वेरी करने की अनुमति देता है जो आपके कार्यभार के लिए अधिक समझदार है।
उदाहरण के लिए, एक ऐसे डिज़ाइन पर विचार करें जो एक सामान्य तरीके से एक जटिल इकाई के बारे में बहुत सारी जानकारी रखता है। यह डेटा को सामान्य रूप में संग्रहीत करने के लिए MySQL (या किसी भी संबंधपरक डीबी) में दर्जनों तालिकाओं का आसानी से उपयोग कर सकता है, तालिकाओं के बीच संबंधपरक अखंडता सुनिश्चित करने के लिए आवश्यक कई अनुक्रमणिका के साथ।
अब दस्तावेज़ स्टोर के साथ उसी डिज़ाइन पर विचार करें। यदि वे सभी संबंधित तालिकाएँ मुख्य तालिका के अधीनस्थ हैं (और वे अक्सर होती हैं), तो आप डेटा को इस तरह से मॉडल करने में सक्षम हो सकते हैं कि पूरी इकाई एक ही दस्तावेज़ में संग्रहीत हो। MongoDB में आप इसे एकल दस्तावेज़ के रूप में, एकल संग्रह में संग्रहीत कर सकते हैं। यहीं से MongoDB बेहतर प्रदर्शन को सक्षम करना शुरू करता है।
MongoDB में, पूरी इकाई को पुनः प्राप्त करने के लिए, आपको निम्न कार्य करना होगा:
- संग्रह पर एक इंडेक्स लुकअप (यह मानते हुए कि इकाई आईडी द्वारा प्राप्त की गई है)
- एक डेटाबेस पृष्ठ (वास्तविक बाइनरी जोंस दस्तावेज़) की सामग्री को पुनः प्राप्त करें
तो एक बी-पेड़ लुकअप, और एक बाइनरी पेज पढ़ा। लॉग (एन) + 1 आईओ। अगर इंडेक्स पूरी तरह से मेमोरी में रह सकते हैं, तो 1 IO.
MySQL में 20 टेबल के साथ, आपको निम्न प्रदर्शन करना होगा:
- रूट टेबल पर एक इंडेक्स लुकअप (फिर से, यह मानते हुए कि इकाई आईडी द्वारा लाई गई है)
- एक संकुल अनुक्रमणिका के साथ, हम मान सकते हैं कि मूल पंक्ति के मान अनुक्रमणिका में हैं
- इकाई के pk मान के लिए 20+ रेंज लुकअप (उम्मीद है कि एक इंडेक्स पर)
- शायद ये क्लस्टर इंडेक्स नहीं हैं, इसलिए जब हम यह पता लगा लेते हैं कि उपयुक्त चाइल्ड रो क्या हैं, तो वही 20+ डेटा लुकअप।
तो MySQL के लिए कुल, यहां तक कि यह मानते हुए कि सभी अनुक्रमणिका स्मृति में हैं (जो कठिन है क्योंकि उनमें से 20 गुना अधिक हैं) लगभग 20 रेंज लुकअप हैं।
इन रेंज लुकअप में यादृच्छिक आईओ शामिल होने की संभावना है - अलग-अलग टेबल निश्चित रूप से डिस्क पर अलग-अलग स्पॉट्स में रहेंगे, और यह संभव है कि एक ही टेबल में एक ही टेबल में एक ही रेंज में अलग-अलग पंक्तियां सन्निहित न हों (इस पर निर्भर करता है कि इकाई कैसी रही है) अद्यतन, आदि)।
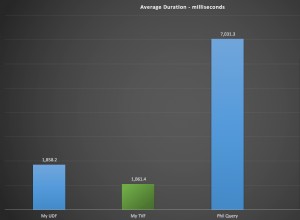
तो इस उदाहरण के लिए, अंतिम मिलान लगभग 20 गुना है MongoDB की तुलना में MySQL प्रति लॉजिकल एक्सेस के साथ अधिक IO।
इस प्रकार MongoDB कुछ उपयोग के मामलों में प्रदर्शन को बढ़ावा दे सकता है ।