डेटा विश्लेषकों के लिए पायथन और एसक्यूएल दो सबसे महत्वपूर्ण भाषाएं हैं।
इस लेख में मैं आपको वह सब कुछ बताऊंगा जो आपको पायथन और एसक्यूएल को जोड़ने के लिए जानना आवश्यक है।
आप सीखेंगे कि रिलेशनल डेटाबेस से डेटा को सीधे अपनी मशीन लर्निंग पाइपलाइन में कैसे खींचना है, अपने पायथन एप्लिकेशन से डेटा को अपने डेटाबेस में स्टोर करना है, या जो भी अन्य उपयोग के मामले में आप आ सकते हैं।
साथ में हम कवर करेंगे:
- पायथन और एसक्यूएल का एक साथ उपयोग करना क्यों सीखें?
- अपना पायथन वातावरण और MySQL सर्वर कैसे सेट करें
- पायथन में MySQL सर्वर से कनेक्ट करना
- नया डेटाबेस बनाना
- टेबल और टेबल संबंध बनाना
- तालिकाओं को डेटा से आबाद करना
- डेटा पढ़ना
- रिकॉर्ड अपडेट करना
- रिकॉर्ड हटाना
- पायथन सूचियों से रिकॉर्ड बनाना
- भविष्य में हमारे लिए यह सब करने के लिए पुन:उपयोग करने योग्य फ़ंक्शन बनाना
यह बहुत ही उपयोगी और बहुत ही अच्छी चीज है। आइए इसमें शामिल हों!
शुरू करने से पहले एक त्वरित नोट:एक ज्यूपिटर नोटबुक है जिसमें इस ट्यूटोरियल में उपयोग किए गए सभी कोड शामिल हैं जो इस गिटहब रिपोजिटरी में उपलब्ध हैं। साथ में कोडिंग की अत्यधिक अनुशंसा की जाती है!
यहां उपयोग किया गया डेटाबेस और SQL कोड, डेटा साइंस की ओर पोस्ट की गई SQL श्रृंखला के मेरे पिछले परिचय से है (यदि आपको लेख देखने में कोई समस्या है तो मुझसे संपर्क करें और मैं आपको उन्हें मुफ्त में देखने के लिए एक लिंक भेज सकता हूं)।
यदि आप SQL और रिलेशनल डेटाबेस के पीछे की अवधारणाओं से परिचित नहीं हैं, तो मैं आपको उस श्रृंखला की ओर इंगित करूँगा (साथ ही यहाँ freeCodeCamp पर बड़ी मात्रा में बढ़िया सामग्री उपलब्ध है!)
एसक्यूएल के साथ पायथन क्यों?
डेटा विश्लेषकों और डेटा वैज्ञानिकों के लिए, पायथन के कई फायदे हैं। ओपन-सोर्स पुस्तकालयों की एक विशाल श्रृंखला इसे किसी भी डेटा विश्लेषक के लिए एक अविश्वसनीय रूप से उपयोगी उपकरण बनाती है।
हमारे पास डेटा विश्लेषण के लिए पांडा, NumPy और Vaex, विज़ुअलाइज़ेशन के लिए Matplotlib, समुद्री और बोकेह, और मशीन लर्निंग एप्लिकेशन के लिए TensorFlow, scikit-learn और PyTorch (साथ ही कई, कई और) हैं।
इसकी (अपेक्षाकृत) आसान सीखने की अवस्था और बहुमुखी प्रतिभा के साथ, इसमें कोई आश्चर्य की बात नहीं है कि पायथन सबसे तेजी से बढ़ती प्रोग्रामिंग भाषाओं में से एक है।
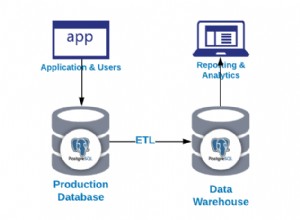
तो अगर हम डेटा विश्लेषण के लिए पायथन का उपयोग कर रहे हैं, तो यह पूछने लायक है - यह सारा डेटा कहां से आता है?
जबकि डेटासेट के लिए स्रोतों की एक विशाल विविधता है, कई मामलों में - विशेष रूप से उद्यम व्यवसायों में - डेटा को एक रिलेशनल डेटाबेस में संग्रहीत किया जा रहा है। रिलेशनल डेटाबेस सभी प्रकार के डेटा को बनाने, पढ़ने, अपडेट करने और हटाने के लिए एक अत्यंत कुशल, शक्तिशाली और व्यापक रूप से उपयोग किया जाने वाला तरीका है।
सबसे व्यापक रूप से उपयोग किए जाने वाले रिलेशनल डेटाबेस मैनेजमेंट सिस्टम (RDBMS) - Oracle, MySQL, Microsoft SQL Server, PostgreSQL, IBM DB2 - सभी डेटा तक पहुँचने और परिवर्तन करने के लिए स्ट्रक्चर्ड क्वेरी लैंग्वेज (SQL) का उपयोग करते हैं।
ध्यान दें कि प्रत्येक RDBMS SQL के थोड़े अलग स्वाद का उपयोग करता है, इसलिए एक के लिए लिखा गया SQL कोड आमतौर पर (सामान्य रूप से काफी मामूली) संशोधनों के बिना दूसरे में काम नहीं करेगा। लेकिन अवधारणाएं, संरचनाएं और संचालन काफी हद तक समान हैं।
इसका मतलब है कि एक कार्यरत डेटा विश्लेषक के लिए, एसक्यूएल की एक मजबूत समझ बेहद जरूरी है। जब आपके डेटा के साथ काम करने की बात आती है, तो पाइथन और एसक्यूएल का एक साथ उपयोग करने का तरीका जानने से आपको और भी अधिक लाभ मिलेगा।
इस लेख का शेष भाग आपको यह दिखाने के लिए समर्पित होगा कि हम यह कैसे कर सकते हैं।
आरंभ करना
आवश्यकताएं और स्थापना
इस ट्यूटोरियल के साथ कोड करने के लिए, आपको अपने स्वयं के पायथन वातावरण की स्थापना की आवश्यकता होगी।
मैं एनाकोंडा का उपयोग करता हूं, लेकिन ऐसा करने के कई तरीके हैं। अगर आपको और मदद की ज़रूरत है तो बस Google "पायथन कैसे इंस्टॉल करें"। आप जुपिटर नोटबुक के साथ कोड करने के लिए बाइंडर का भी उपयोग कर सकते हैं।
हम MySQL कम्युनिटी सर्वर का उपयोग करेंगे क्योंकि यह मुफ़्त है और उद्योग में व्यापक रूप से उपयोग किया जाता है। यदि आप Windows का उपयोग कर रहे हैं, तो यह मार्गदर्शिका आपको सेटअप करने में सहायता करेगी। यहाँ Mac और Linux उपयोगकर्ताओं के लिए भी मार्गदर्शिकाएँ दी गई हैं (हालाँकि यह Linux वितरण द्वारा भिन्न हो सकती है)।
एक बार जब आप उन्हें सेट कर लेंगे, तो हमें उन्हें एक दूसरे के साथ संवाद करने की आवश्यकता होगी।
उसके लिए, हमें MySQL Connector Python लाइब्रेरी को इंस्टॉल करना होगा। ऐसा करने के लिए, निर्देशों का पालन करें, या बस पाइप का उपयोग करें:
pip install mysql-connector-pythonहम पंडों का भी उपयोग करने जा रहे हैं, इसलिए सुनिश्चित करें कि आपने इसे भी इंस्टॉल कर लिया है।
pip install pandasलाइब्रेरी आयात करना
जैसा कि पायथन में हर परियोजना के साथ होता है, सबसे पहली चीज जो हम करना चाहते हैं वह है हमारे पुस्तकालयों का आयात करना।
प्रोजेक्ट की शुरुआत में हम जिन सभी पुस्तकालयों का उपयोग करने जा रहे हैं, उन्हें आयात करना सबसे अच्छा अभ्यास है, इसलिए हमारे कोड को पढ़ने या समीक्षा करने वाले लोग मोटे तौर पर जानते हैं कि क्या हो रहा है, इसलिए कोई आश्चर्य नहीं है।
इस ट्यूटोरियल के लिए, हम केवल दो पुस्तकालयों - MySQL कनेक्टर और पांडा का उपयोग करने जा रहे हैं।
import mysql.connector
from mysql.connector import Error
import pandas as pdहम त्रुटि फ़ंक्शन को अलग से आयात करते हैं ताकि हम अपने कार्यों के लिए उस तक आसानी से पहुंच सकें।
MySQL सर्वर से कनेक्ट करना
इस बिंदु तक हमारे पास हमारे सिस्टम पर MySQL कम्युनिटी सर्वर स्थापित होना चाहिए। अब हमें Python में कुछ कोड लिखने की आवश्यकता है जो हमें उस सर्वर से कनेक्शन स्थापित करने देता है।
def create_server_connection(host_name, user_name, user_password):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionइस तरह के कोड के लिए पुन:उपयोग करने योग्य फ़ंक्शन बनाना सर्वोत्तम अभ्यास है, ताकि हम इसे न्यूनतम प्रयास के साथ बार-बार उपयोग कर सकें। एक बार यह लिखा जाने के बाद आप भविष्य में भी अपने सभी प्रोजेक्ट्स में इसका पुन:उपयोग कर सकते हैं, इसलिए भविष्य-आप आभारी होंगे!
आइए इस लाइन से लाइन पर चलते हैं ताकि हम समझ सकें कि यहां क्या हो रहा है:
पहली पंक्ति हम फ़ंक्शन का नामकरण (create_server_connection) कर रहे हैं और उन तर्कों का नामकरण कर रहे हैं जो वह फ़ंक्शन लेगा (host_name, user_name और user_password)।
अगली पंक्ति किसी भी मौजूदा कनेक्शन को बंद कर देती है ताकि सर्वर कई खुले कनेक्शनों के साथ भ्रमित न हो।
आगे हम किसी भी संभावित त्रुटियों को संभालने के लिए एक पायथन ट्राई-सिवाय ब्लॉक का उपयोग करते हैं। पहला भाग तर्कों में उपयोगकर्ता द्वारा निर्दिष्ट विवरण का उपयोग करके mysql.connector.connect() विधि का उपयोग करके सर्वर से कनेक्शन बनाने का प्रयास करता है। यदि यह काम करता है, तो फ़ंक्शन एक खुश सा सफलता संदेश प्रिंट करता है।
ब्लॉक का अपवाद भाग उस त्रुटि को प्रिंट करता है जो MySQL सर्वर देता है, दुर्भाग्यपूर्ण परिस्थिति में कि कोई त्रुटि है।
अंत में, यदि कनेक्शन सफल होता है, तो फ़ंक्शन एक कनेक्शन ऑब्जेक्ट देता है।
हम इसे व्यवहार में फ़ंक्शन के आउटपुट को एक चर के लिए निर्दिष्ट करके उपयोग करते हैं, जो तब हमारा कनेक्शन ऑब्जेक्ट बन जाता है। फिर हम इसमें अन्य तरीके (जैसे कर्सर) लागू कर सकते हैं और अन्य उपयोगी वस्तुएँ बना सकते हैं।
connection = create_server_connection("localhost", "root", pw)यह एक सफल संदेश देना चाहिए:

नया डेटाबेस बनाना
अब जब हमने एक कनेक्शन स्थापित कर लिया है, तो हमारा अगला कदम अपने सर्वर पर एक नया डेटाबेस बनाना है।
इस ट्यूटोरियल में हम इसे केवल एक बार करेंगे, लेकिन फिर से हम इसे एक पुन:प्रयोज्य फ़ंक्शन के रूप में लिखेंगे ताकि हमारे पास एक अच्छा उपयोगी फ़ंक्शन हो, जिसे हम भविष्य की परियोजनाओं के लिए पुन:उपयोग कर सकें।
def create_database(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
print("Database created successfully")
except Error as err:
print(f"Error: '{err}'")यह फ़ंक्शन दो तर्क लेता है, कनेक्शन (हमारी कनेक्शन ऑब्जेक्ट) और क्वेरी (एक SQL क्वेरी जिसे हम अगले चरण में लिखेंगे)। यह कनेक्शन के माध्यम से सर्वर में क्वेरी निष्पादित करता है।
हम एक कर्सर ऑब्जेक्ट बनाने के लिए अपने कनेक्शन ऑब्जेक्ट पर कर्सर विधि का उपयोग करते हैं (MySQL कनेक्टर एक ऑब्जेक्ट-ओरिएंटेड प्रोग्रामिंग प्रतिमान का उपयोग करता है, इसलिए बहुत सारे ऑब्जेक्ट पैरेंट ऑब्जेक्ट्स से गुण विरासत में मिलते हैं)।
इस कर्सर ऑब्जेक्ट में कई अन्य उपयोगी विधियों के साथ-साथ एक्ज़ीक्यूट, एक्ज़ीक्यूटमैनी (जिसका उपयोग हम इस ट्यूटोरियल में करेंगे) जैसी विधियाँ हैं।
अगर यह मदद करता है, तो हम एक MySQL सर्वर टर्मिनल विंडो में ब्लिंकिंग कर्सर तक पहुंच प्रदान करने के रूप में कर्सर ऑब्जेक्ट के बारे में सोच सकते हैं।
इसके बाद हम डेटाबेस बनाने और फ़ंक्शन को कॉल करने के लिए एक क्वेरी को परिभाषित करते हैं:

इस ट्यूटोरियल में उपयोग किए गए सभी SQL प्रश्नों को SQL ट्यूटोरियल श्रृंखला के मेरे परिचय में समझाया गया है, और पूरा कोड इस GitHub रिपॉजिटरी में संबंधित ज्यूपिटर नोटबुक में पाया जा सकता है, इसलिए मैं इस बारे में स्पष्टीकरण नहीं दूंगा कि SQL कोड इसमें क्या करता है। ट्यूटोरियल।
हालाँकि, यह शायद सबसे सरल SQL क्वेरी संभव है। यदि आप अंग्रेजी पढ़ सकते हैं तो आप शायद यह पता लगा सकते हैं कि यह क्या करती है!
ऊपर दिए गए तर्कों के साथ create_database फ़ंक्शन को चलाने से हमारे सर्वर में 'स्कूल' नामक डेटाबेस बन रहा है।
हमारे डेटाबेस को 'स्कूल' क्यों कहा जाता है? शायद अब इस ट्यूटोरियल में हम क्या लागू करने जा रहे हैं, इस पर अधिक विस्तार से देखने का एक अच्छा समय होगा।
हमारा डेटाबेस
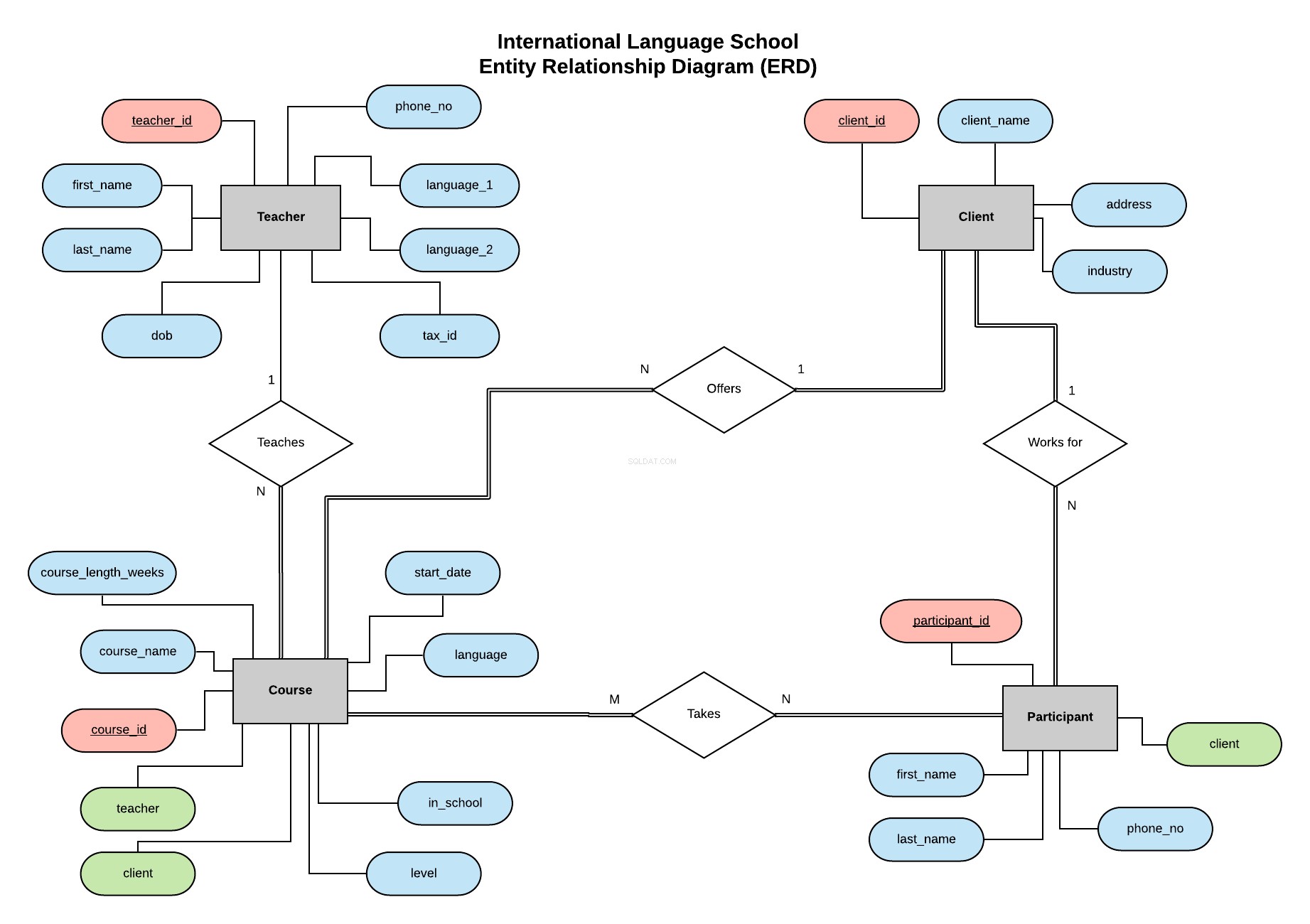
मेरी पिछली श्रृंखला में उदाहरण के बाद, हम इंटरनेशनल लैंग्वेज स्कूल के लिए डेटाबेस को लागू करने जा रहे हैं - एक काल्पनिक भाषा प्रशिक्षण स्कूल जो कॉर्पोरेट ग्राहकों को पेशेवर भाषा पाठ प्रदान करता है।
यह इकाई संबंध आरेख (ईआरडी) हमारी संस्थाओं (शिक्षक, ग्राहक, पाठ्यक्रम और प्रतिभागी) को बताता है और उनके बीच संबंधों को परिभाषित करता है।
एक ईआरडी क्या है और एक डेटाबेस बनाते समय और क्या विचार करना चाहिए, इस बारे में सारी जानकारी इस लेख में मिल सकती है।
डेटाबेस में जाने के लिए अपरिष्कृत SQL कोड, डेटाबेस आवश्यकताएँ, और डेटा सभी इस GitHub रिपॉजिटरी में समाहित हैं, लेकिन आप यह सब तब देखेंगे जब हम इस ट्यूटोरियल को भी पढ़ेंगे।
डेटाबेस से कनेक्ट करना
अब जब हमने MySQL सर्वर में एक डेटाबेस बना लिया है, तो हम इस डेटाबेस से सीधे जुड़ने के लिए अपने create_server_connection फ़ंक्शन को संशोधित कर सकते हैं।
ध्यान दें कि यह संभव है - सामान्य, वास्तव में - एक MySQL सर्वर पर कई डेटाबेस होना, इसलिए हम हमेशा और स्वचालित रूप से उस डेटाबेस से जुड़ना चाहते हैं जिसमें हम रुचि रखते हैं।
हम ऐसा ऐसा कर सकते हैं:
def create_db_connection(host_name, user_name, user_password, db_name):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password,
database=db_name
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionयह ठीक वही फ़ंक्शन है, लेकिन अब हम एक और तर्क - डेटाबेस नाम - लेते हैं और इसे कनेक्ट () विधि के तर्क के रूप में पास करते हैं।
एक क्वेरी निष्पादन फ़ंक्शन बनाना
अंतिम फ़ंक्शन जिसे हम बनाने जा रहे हैं (अभी के लिए) एक अत्यंत महत्वपूर्ण है - एक क्वेरी निष्पादन फ़ंक्शन। यह हमारे SQL प्रश्नों को लेने जा रहा है, जो पायथन में स्ट्रिंग्स के रूप में संग्रहीत हैं, और उन्हें सर्वर पर निष्पादित करने के लिए कर्सर.execute () विधि में पास करते हैं।
def execute_query(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")यह फ़ंक्शन पहले से हमारे create_database फ़ंक्शन के समान ही है, सिवाय इसके कि यह यह सुनिश्चित करने के लिए कनेक्शन.commit() विधि का उपयोग करता है कि हमारे SQL प्रश्नों में विस्तृत आदेश लागू किए गए हैं।
यह हमारा वर्कहॉर्स फंक्शन होने जा रहा है, जिसका उपयोग हम (create_db_connection के साथ) टेबल बनाने, उन टेबल्स के बीच संबंध स्थापित करने, डेटा के साथ टेबल्स को पॉप्युलेट करने और हमारे डेटाबेस में रिकॉर्ड्स को अपडेट और डिलीट करने के लिए करेंगे।
यदि आप एक SQL विशेषज्ञ हैं, तो यह फ़ंक्शन आपको किसी भी और सभी जटिल कमांडों और प्रश्नों को निष्पादित करने देगा, जो आपके आस-पास पड़े हों, सीधे एक पायथन लिपि से। यह आपके डेटा के प्रबंधन के लिए एक बहुत शक्तिशाली टूल हो सकता है।
टेबल बनाना
अब हम अपने सर्वर में SQL कमांड चलाना शुरू करने और अपने डेटाबेस का निर्माण शुरू करने के लिए पूरी तरह तैयार हैं। पहली चीज जो हम करना चाहते हैं वह है आवश्यक टेबल बनाना।
आइए अपनी शिक्षक तालिका से शुरू करें:
create_teacher_table = """
CREATE TABLE teacher (
teacher_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
language_1 VARCHAR(3) NOT NULL,
language_2 VARCHAR(3),
dob DATE,
tax_id INT UNIQUE,
phone_no VARCHAR(20)
);
"""
connection = create_db_connection("localhost", "root", pw, db) # Connect to the Database
execute_query(connection, create_teacher_table) # Execute our defined queryसबसे पहले हम अपने SQL कमांड को एक उपयुक्त नाम के साथ एक वेरिएबल को असाइन करते हैं (विस्तार से यहां समझाया गया है)।
इस मामले में हम अपनी SQL क्वेरी को स्टोर करने के लिए मल्टी-लाइन स्ट्रिंग्स के लिए पायथन के ट्रिपल कोट नोटेशन का उपयोग करते हैं, फिर हम इसे लागू करने के लिए इसे अपने execute_query फ़ंक्शन में फीड करते हैं।
ध्यान दें कि यह बहु-पंक्ति स्वरूपण विशुद्ध रूप से हमारे कोड को पढ़ने वाले मनुष्यों के लाभ के लिए है। न तो SQL और न ही पायथन 'देखभाल' अगर SQL कमांड इस तरह फैला हुआ है। जब तक वाक्य रचना सही है, दोनों भाषाएँ इसे स्वीकार करेंगी।
मनुष्यों के लाभ के लिए जो आपका कोड पढ़ेंगे, हालांकि, (भले ही वह केवल भविष्य ही हो-आप!) कोड को अधिक पठनीय और समझने योग्य बनाने के लिए ऐसा करना बहुत उपयोगी है।
एसक्यूएल में ऑपरेटरों के पूंजीकरण के लिए भी यही सच है। यह एक व्यापक रूप से उपयोग किया जाने वाला सम्मेलन है जिसकी दृढ़ता से अनुशंसा की जाती है, लेकिन कोड चलाने वाला वास्तविक सॉफ़्टवेयर केस-असंवेदनशील है और 'टेबल शिक्षक बनाएं' और 'टेबल शिक्षक बनाएं' को समान आदेशों के रूप में मानेगा।

इस कोड को चलाने से हमें सफलता के संदेश मिलते हैं। हम इसे MySQL सर्वर कमांड लाइन क्लाइंट में भी सत्यापित कर सकते हैं:
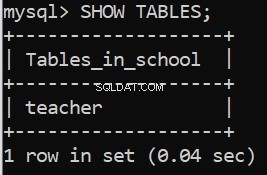
महान! अब शेष टेबल बनाते हैं।
create_client_table = """
CREATE TABLE client (
client_id INT PRIMARY KEY,
client_name VARCHAR(40) NOT NULL,
address VARCHAR(60) NOT NULL,
industry VARCHAR(20)
);
"""
create_participant_table = """
CREATE TABLE participant (
participant_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
phone_no VARCHAR(20),
client INT
);
"""
create_course_table = """
CREATE TABLE course (
course_id INT PRIMARY KEY,
course_name VARCHAR(40) NOT NULL,
language VARCHAR(3) NOT NULL,
level VARCHAR(2),
course_length_weeks INT,
start_date DATE,
in_school BOOLEAN,
teacher INT,
client INT
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, create_client_table)
execute_query(connection, create_participant_table)
execute_query(connection, create_course_table)यह हमारी चार संस्थाओं के लिए आवश्यक चार तालिकाएँ बनाता है।
अब हम उनके बीच संबंधों को परिभाषित करना चाहते हैं और प्रतिभागी और पाठ्यक्रम तालिकाओं के बीच कई-से-अनेक संबंधों को संभालने के लिए एक और तालिका बनाना चाहते हैं (अधिक विवरण के लिए यहां देखें)।
हम इसे बिल्कुल उसी तरह से करते हैं:
alter_participant = """
ALTER TABLE participant
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
alter_course = """
ALTER TABLE course
ADD FOREIGN KEY(teacher)
REFERENCES teacher(teacher_id)
ON DELETE SET NULL;
"""
alter_course_again = """
ALTER TABLE course
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
create_takescourse_table = """
CREATE TABLE takes_course (
participant_id INT,
course_id INT,
PRIMARY KEY(participant_id, course_id),
FOREIGN KEY(participant_id) REFERENCES participant(participant_id) ON DELETE CASCADE,
FOREIGN KEY(course_id) REFERENCES course(course_id) ON DELETE CASCADE
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, alter_participant)
execute_query(connection, alter_course)
execute_query(connection, alter_course_again)
execute_query(connection, create_takescourse_table)अब हमारे टेबल उपयुक्त बाधाओं, प्राथमिक कुंजी और विदेशी कुंजी संबंधों के साथ बनाए गए हैं।
तालिकाओं को पॉप्युलेट करना
अगला कदम तालिकाओं में कुछ रिकॉर्ड जोड़ना है। फिर से हम अपने मौजूदा SQL कमांड को सर्वर में फीड करने के लिए execute_query का उपयोग करते हैं। आइए फिर से शिक्षक तालिका से शुरू करते हैं।
pop_teacher = """
INSERT INTO teacher VALUES
(1, 'James', 'Smith', 'ENG', NULL, '1985-04-20', 12345, '+491774553676'),
(2, 'Stefanie', 'Martin', 'FRA', NULL, '1970-02-17', 23456, '+491234567890'),
(3, 'Steve', 'Wang', 'MAN', 'ENG', '1990-11-12', 34567, '+447840921333'),
(4, 'Friederike', 'Müller-Rossi', 'DEU', 'ITA', '1987-07-07', 45678, '+492345678901'),
(5, 'Isobel', 'Ivanova', 'RUS', 'ENG', '1963-05-30', 56789, '+491772635467'),
(6, 'Niamh', 'Murphy', 'ENG', 'IRI', '1995-09-08', 67890, '+491231231232');
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_teacher)क्या यह काम करता हैं? हम अपने MySQL कमांड लाइन क्लाइंट में दोबारा जांच सकते हैं:
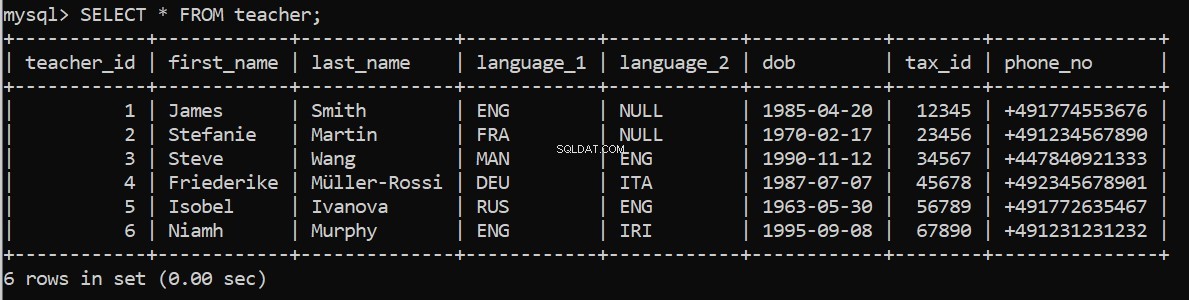
अब शेष तालिकाओं को भरने के लिए।
pop_client = """
INSERT INTO client VALUES
(101, 'Big Business Federation', '123 Falschungstraße, 10999 Berlin', 'NGO'),
(102, 'eCommerce GmbH', '27 Ersatz Allee, 10317 Berlin', 'Retail'),
(103, 'AutoMaker AG', '20 Künstlichstraße, 10023 Berlin', 'Auto'),
(104, 'Banko Bank', '12 Betrugstraße, 12345 Berlin', 'Banking'),
(105, 'WeMoveIt GmbH', '138 Arglistweg, 10065 Berlin', 'Logistics');
"""
pop_participant = """
INSERT INTO participant VALUES
(101, 'Marina', 'Berg','491635558182', 101),
(102, 'Andrea', 'Duerr', '49159555740', 101),
(103, 'Philipp', 'Probst', '49155555692', 102),
(104, 'René', 'Brandt', '4916355546', 102),
(105, 'Susanne', 'Shuster', '49155555779', 102),
(106, 'Christian', 'Schreiner', '49162555375', 101),
(107, 'Harry', 'Kim', '49177555633', 101),
(108, 'Jan', 'Nowak', '49151555824', 101),
(109, 'Pablo', 'Garcia', '49162555176', 101),
(110, 'Melanie', 'Dreschler', '49151555527', 103),
(111, 'Dieter', 'Durr', '49178555311', 103),
(112, 'Max', 'Mustermann', '49152555195', 104),
(113, 'Maxine', 'Mustermann', '49177555355', 104),
(114, 'Heiko', 'Fleischer', '49155555581', 105);
"""
pop_course = """
INSERT INTO course VALUES
(12, 'English for Logistics', 'ENG', 'A1', 10, '2020-02-01', TRUE, 1, 105),
(13, 'Beginner English', 'ENG', 'A2', 40, '2019-11-12', FALSE, 6, 101),
(14, 'Intermediate English', 'ENG', 'B2', 40, '2019-11-12', FALSE, 6, 101),
(15, 'Advanced English', 'ENG', 'C1', 40, '2019-11-12', FALSE, 6, 101),
(16, 'Mandarin für Autoindustrie', 'MAN', 'B1', 15, '2020-01-15', TRUE, 3, 103),
(17, 'Français intermédiaire', 'FRA', 'B1', 18, '2020-04-03', FALSE, 2, 101),
(18, 'Deutsch für Anfänger', 'DEU', 'A2', 8, '2020-02-14', TRUE, 4, 102),
(19, 'Intermediate English', 'ENG', 'B2', 10, '2020-03-29', FALSE, 1, 104),
(20, 'Fortgeschrittenes Russisch', 'RUS', 'C1', 4, '2020-04-08', FALSE, 5, 103);
"""
pop_takescourse = """
INSERT INTO takes_course VALUES
(101, 15),
(101, 17),
(102, 17),
(103, 18),
(104, 18),
(105, 18),
(106, 13),
(107, 13),
(108, 13),
(109, 14),
(109, 15),
(110, 16),
(110, 20),
(111, 16),
(114, 12),
(112, 19),
(113, 19);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_client)
execute_query(connection, pop_participant)
execute_query(connection, pop_course)
execute_query(connection, pop_takescourse)अद्भुत! अब हमने MySQL में संबंधों, बाधाओं और अभिलेखों के साथ एक डेटाबेस बनाया है, जिसमें पाइथन कमांड के अलावा कुछ भी नहीं है।
हम इसे समझने योग्य बनाए रखने के लिए इस चरण से गुजरे हैं। लेकिन इस बिंदु तक आप देख सकते हैं कि यह सब बहुत आसानी से एक पायथन लिपि में लिखा जा सकता है और टर्मिनल में एक कमांड में निष्पादित किया जा सकता है। शक्तिशाली सामान।
डेटा पढ़ना
अब हमारे पास काम करने के लिए एक कार्यात्मक डेटाबेस है। डेटा विश्लेषक के रूप में, आप उन संगठनों में मौजूदा डेटाबेस के संपर्क में आने की संभावना रखते हैं जहां आप काम करते हैं। यह जानना बहुत उपयोगी होगा कि उन डेटाबेस से डेटा कैसे निकाला जाए ताकि इसे आपके पायथन डेटा पाइपलाइन में फीड किया जा सके। आगे हम इसी पर काम करने जा रहे हैं।
इसके लिए हमें एक और फ़ंक्शन की आवश्यकता होगी, इस बार कर्सर.कॉमिट () के बजाय कर्सर.फ़ेचॉल () का उपयोग करना। इस फ़ंक्शन के साथ, हम डेटाबेस से डेटा पढ़ रहे हैं और कोई बदलाव नहीं करेंगे।
def read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as err:
print(f"Error: '{err}'")फिर से, हम इसे execute_query के समान तरीके से लागू करने जा रहे हैं। आइए इसे एक साधारण प्रश्न के साथ देखें कि यह कैसे काम करता है।
q1 = """
SELECT *
FROM teacher;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q1)
for result in results:
print(result)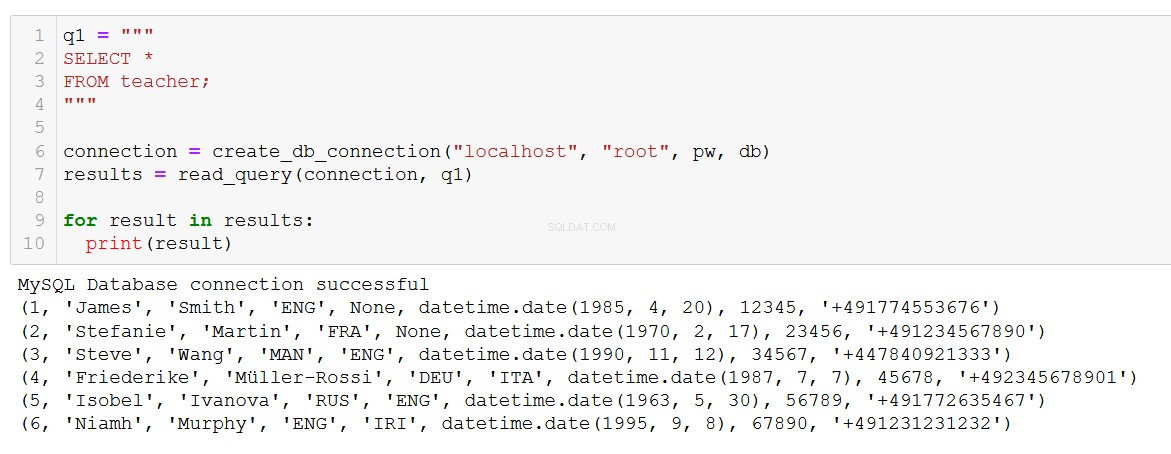
ठीक वही जो हम उम्मीद कर रहे हैं। फ़ंक्शन अधिक जटिल प्रश्नों के साथ भी काम करता है, जैसे कि पाठ्यक्रम और क्लाइंट टेबल पर जॉइन शामिल करना।
q5 = """
SELECT course.course_id, course.course_name, course.language, client.client_name, client.address
FROM course
JOIN client
ON course.client = client.client_id
WHERE course.in_school = FALSE;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q5)
for result in results:
print(result)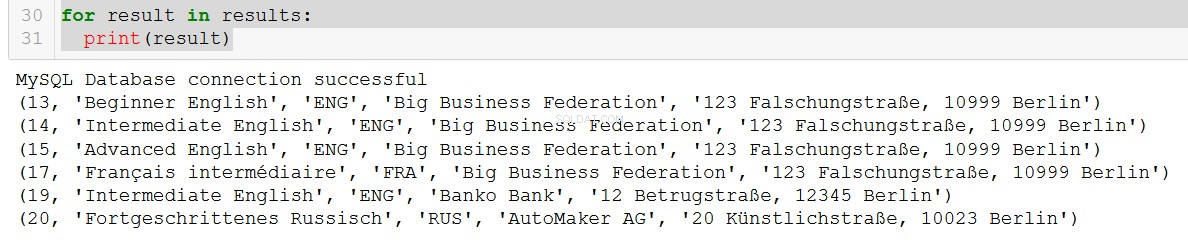
बहुत अच्छा।
पायथन में हमारे डेटा पाइपलाइनों और वर्कफ़्लो के लिए, हम इन परिणामों को विभिन्न स्वरूपों में प्राप्त करना चाहते हैं ताकि उन्हें अधिक उपयोगी या हमारे लिए हेरफेर करने के लिए तैयार किया जा सके।
आइए कुछ उदाहरणों के माध्यम से देखें कि हम यह कैसे कर सकते हैं।
आउटपुट को सूची में फ़ॉर्मेट करना
#Initialise empty list
from_db = []
# Loop over the results and append them into our list
# Returns a list of tuples
for result in results:
result = result
from_db.append(result)
आउटपुट को सूचियों की सूची में फ़ॉर्मेट करना
# Returns a list of lists
from_db = []
for result in results:
result = list(result)
from_db.append(result)
आउटपुट को पांडा डेटाफ़्रेम में फ़ॉर्मेट करना
पायथन का उपयोग करने वाले डेटा विश्लेषकों के लिए, पांडा हमारे सुंदर और भरोसेमंद पुराने दोस्त हैं। हमारे डेटाबेस से आउटपुट को डेटाफ़्रेम में बदलना बहुत आसान है, और वहाँ से संभावनाएं अनंत हैं!
# Returns a list of lists and then creates a pandas DataFrame
from_db = []
for result in results:
result = list(result)
from_db.append(result)
columns = ["course_id", "course_name", "language", "client_name", "address"]
df = pd.DataFrame(from_db, columns=columns)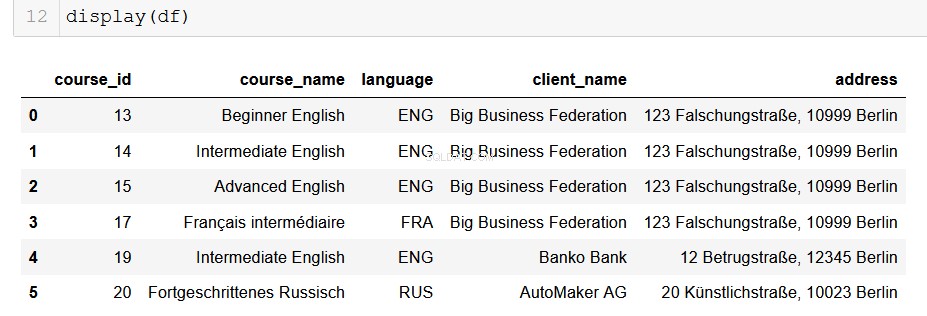
उम्मीद है कि आप यहां अपने सामने सामने आने वाली संभावनाओं को देख सकते हैं। कोड की केवल कुछ पंक्तियों के साथ, हम उन सभी डेटा को आसानी से निकाल सकते हैं जिन्हें हम रिलेशनल डेटाबेस से संभाल सकते हैं जहां यह रहता है, और इसे हमारे अत्याधुनिक डेटा एनालिटिक्स पाइपलाइनों में खींच सकते हैं। यह वास्तव में सहायक सामग्री है।
रिकॉर्ड अपडेट करना
जब हम एक डेटाबेस का रखरखाव कर रहे होते हैं, तो हमें कभी-कभी मौजूदा रिकॉर्ड में बदलाव करने की आवश्यकता होती है। इस खंड में हम यह देखने जा रहे हैं कि यह कैसे करना है।
मान लें कि ILS को सूचित किया गया है कि उसके मौजूदा ग्राहकों में से एक, बिग बिजनेस फेडरेशन, कार्यालयों को 23 Fingiertweg, 14534 बर्लिन में स्थानांतरित कर रहा है। इस मामले में, डेटाबेस व्यवस्थापक (वह हम हैं!) को कुछ बदलाव करने की आवश्यकता होगी।
शुक्र है, हम इसे SQL UPDATE स्टेटमेंट के साथ अपने execute_query फ़ंक्शन के साथ कर सकते हैं।
update = """
UPDATE client
SET address = '23 Fingiertweg, 14534 Berlin'
WHERE client_id = 101;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, update)ध्यान दें कि यहां WHERE क्लॉज बहुत महत्वपूर्ण है। यदि हम इस क्वेरी को WHERE क्लॉज के बिना चलाते हैं, तो हमारी क्लाइंट तालिका में सभी रिकॉर्ड के सभी पते 23 Fingiertweg में अपडेट हो जाएंगे। हम जो करना चाह रहे हैं, वह बहुत कुछ नहीं है।
यह भी ध्यान दें कि हमने अद्यतन क्वेरी में "WHERE client_id =101" का उपयोग किया है। "WHERE client_name ='बिग बिज़नेस फ़ेडरेशन'" या "WHERE एड्रेस ='123 Falschungstraße, 10999 बर्लिन'" या यहाँ तक कि "WHERE एड्रेस LIKE '%Falschung%'" का उपयोग करना भी संभव होता।
महत्वपूर्ण बात यह है कि WHERE क्लॉज हमें उस रिकॉर्ड (या रिकॉर्ड) को विशिष्ट रूप से पहचानने की अनुमति देता है जिसे हम अपडेट करना चाहते हैं।
रिकॉर्ड हटाना
DELETE का उपयोग करके रिकॉर्ड को हटाने के लिए हमारे execute_query फ़ंक्शन का उपयोग करना भी संभव है।
रिलेशनल डेटाबेस के साथ SQL का उपयोग करते समय, हमें DELETE ऑपरेटर का उपयोग करने में सावधानी बरतने की आवश्यकता है। यह विंडोज़ नहीं है, नहीं है 'क्या आप वाकई इसे हटाना चाहते हैं?' पॉप-अप चेतावनी, और कोई रीसाइक्लिंग बिन नहीं है। एक बार जब हम कुछ हटा देते हैं, तो वह वास्तव में चला जाता है।
इसके साथ ही, हमें कभी-कभी चीजों को हटाने की ज़रूरत होती है। तो आइए अपने पाठ्यक्रम तालिका से किसी पाठ्यक्रम को हटाकर उस पर एक नज़र डालते हैं।
सबसे पहले आइए खुद को याद दिलाएं कि हमारे पास कौन से पाठ्यक्रम हैं।
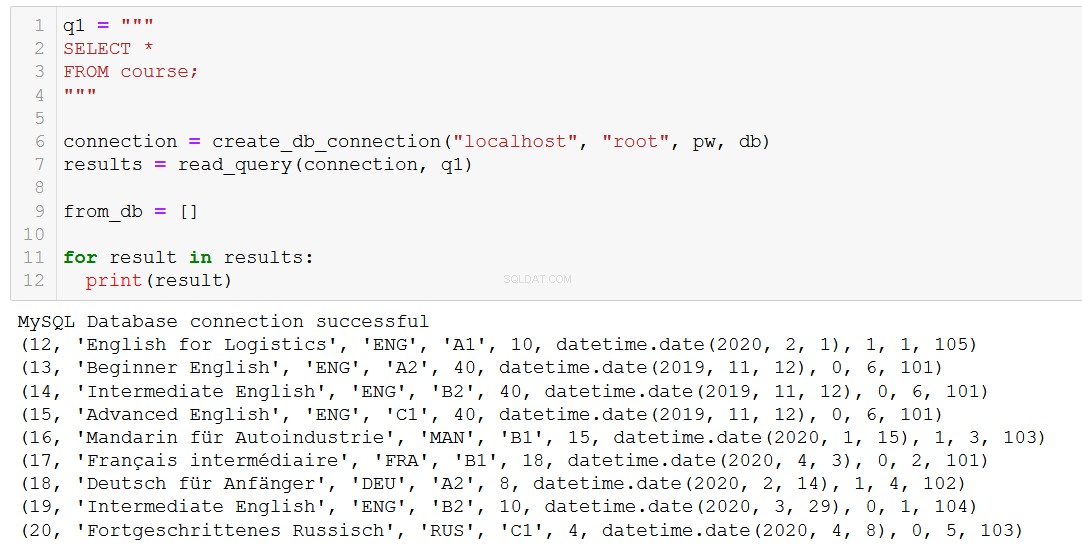
मान लें कि पाठ्यक्रम 20, 'फोर्टगेस्क्रिटेन्स रसिस' (जो आपके और मेरे लिए 'उन्नत रूसी' है), समाप्त हो रहा है, इसलिए हमें इसे अपने डेटाबेस से निकालने की आवश्यकता है।
इस स्तर तक, आप बिल्कुल भी आश्चर्यचकित नहीं होंगे कि हम यह कैसे करते हैं - SQL कमांड को एक स्ट्रिंग के रूप में सहेजें, फिर इसे हमारे वर्कहॉर्स एक्ज़ीक्यूट_क्वेरी फ़ंक्शन में फीड करें।
delete_course = """
DELETE FROM course
WHERE course_id = 20;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, delete_course)आइए यह पुष्टि करने के लिए जांच करें कि इसका अपेक्षित प्रभाव था:
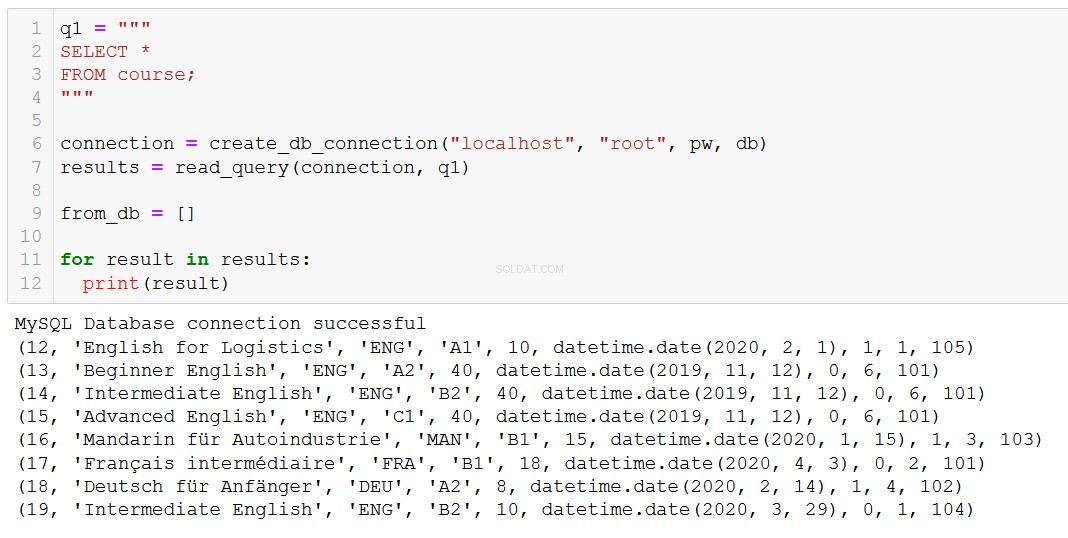
जैसा कि हमें उम्मीद थी, 'उन्नत रूसी' चला गया है।
यह DROP COLUMN का उपयोग करके संपूर्ण कॉलम और DROP TABLE कमांड का उपयोग करके संपूर्ण तालिकाओं को हटाने के साथ भी काम करता है, लेकिन हम इस ट्यूटोरियल में उन्हें कवर नहीं करेंगे।
आगे बढ़ें और उनके साथ प्रयोग करें, हालांकि - इससे कोई फर्क नहीं पड़ता कि आप किसी काल्पनिक स्कूल के डेटाबेस से कॉलम या टेबल को हटाते हैं, और उत्पादन परिवेश में जाने से पहले इन आदेशों के साथ सहज होना एक अच्छा विचार है।
ओह CRUD
इस बिंदु तक, अब हम लगातार डेटा संग्रहण के लिए चार प्रमुख कार्यों को पूरा करने में सक्षम हैं।
हमने सीखा है कि कैसे:
- बनाएं - पूरी तरह से नए डेटाबेस, टेबल और रिकॉर्ड
- पढ़ें - एक डेटाबेस से डेटा निकालें, और उस डेटा को कई प्रारूपों में संग्रहीत करें
- अपडेट करें - डेटाबेस में मौजूदा रिकॉर्ड में बदलाव करें
- हटाएं - ऐसे रिकॉर्ड हटाएं जिनकी अब आवश्यकता नहीं है
ये करने में सक्षम होने के लिए काल्पनिक रूप से उपयोगी चीजें हैं।
इससे पहले कि हम चीजों को यहां समाप्त करें, हमारे पास सीखने के लिए एक और बहुत ही उपयोगी कौशल है।
सूचियों से रिकॉर्ड बनाना
हमने अपनी तालिकाओं को पॉप्युलेट करते समय देखा कि हम अपने डेटाबेस में रिकॉर्ड डालने के लिए अपने execute_query फ़ंक्शन में SQL INSERT कमांड का उपयोग कर सकते हैं।
यह देखते हुए कि हम अपने SQL डेटाबेस में हेरफेर करने के लिए पायथन का उपयोग कर रहे हैं, यह एक पायथन डेटा संरचना (जैसे एक सूची) लेने और सीधे हमारे डेटाबेस में डालने में सक्षम होने के लिए उपयोगी होगा।
यह तब उपयोगी हो सकता है जब हम एक सोशल मीडिया ऐप पर उपयोगकर्ता गतिविधि के लॉग को स्टोर करना चाहते हैं जिसे हमने पायथन में लिखा है, या उपयोगकर्ताओं से इनपुट हमारे द्वारा बनाए गए विकी में, उदाहरण के लिए। इसके लिए जितने संभव उपयोग हैं उतने हैं जितने के बारे में आप सोच सकते हैं।
यदि हमारा डेटाबेस किसी भी बिंदु पर हमारे उपयोगकर्ताओं के लिए खुला है तो यह विधि और भी सुरक्षित है, क्योंकि यह SQL इंजेक्शन हमलों को रोकने में मदद करता है, जो हमारे पूरे डेटाबेस को नुकसान पहुंचा सकता है या नष्ट भी कर सकता है।
ऐसा करने के लिए, हम अब तक उपयोग किए गए सरल निष्पादन () विधि के बजाय एक्ज़ीक्यूटमैनी () विधि का उपयोग करके एक फ़ंक्शन लिखेंगे।
def execute_list_query(connection, sql, val):
cursor = connection.cursor()
try:
cursor.executemany(sql, val)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")अब हमारे पास फ़ंक्शन है, हमें एक SQL कमांड ('sql') और एक सूची को परिभाषित करने की आवश्यकता है जिसमें वे मान हैं जिन्हें हम डेटाबेस ('val') में दर्ज करना चाहते हैं। मानों को टुपल्स की सूची के रूप में संग्रहीत किया जाना चाहिए, जो कि पायथन में डेटा संग्रहीत करने का एक सामान्य तरीका है।
डेटाबेस में दो नए शिक्षक जोड़ने के लिए, हम कुछ इस तरह कोड लिख सकते हैं:
sql = '''
INSERT INTO teacher (teacher_id, first_name, last_name, language_1, language_2, dob, tax_id, phone_no)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
'''
val = [
(7, 'Hank', 'Dodson', 'ENG', None, '1991-12-23', 11111, '+491772345678'),
(8, 'Sue', 'Perkins', 'MAN', 'ENG', '1976-02-02', 22222, '+491443456432')
]यहां ध्यान दें कि 'एसक्यूएल' कोड में हम '%s' को हमारे मूल्य के लिए प्लेसहोल्डर के रूप में उपयोग करते हैं। अजगर में एक स्ट्रिंग के लिए '%s' प्लेसहोल्डर से समानता केवल संयोग है (और स्पष्ट रूप से, बहुत भ्रमित करने वाला), हम MySQL पायथन के साथ सभी डेटा प्रकारों (स्ट्रिंग्स, इनट्स, डेट्स, आदि) के लिए '%s' का उपयोग करना चाहते हैं। कनेक्टर।
आप स्टैक ओवरफ्लो पर कई प्रश्न देख सकते हैं जहां कोई भ्रमित हो गया है और पूर्णांक के लिए '%d' प्लेसहोल्डर का उपयोग करने का प्रयास किया है क्योंकि वे इसे पायथन में करने के लिए उपयोग किए जाते हैं। यह यहाँ काम नहीं करेगा - हमें प्रत्येक कॉलम के लिए '%s' का उपयोग करने की आवश्यकता है जिसमें हम एक मान जोड़ना चाहते हैं।
एक्ज़िक्यूमनी फ़ंक्शन तब हमारी 'वैल' सूची में प्रत्येक टपल को लेता है और प्लेसहोल्डर के स्थान पर उस कॉलम के लिए प्रासंगिक मान सम्मिलित करता है और सूची में निहित प्रत्येक टपल के लिए SQL कमांड निष्पादित करता है।
यह डेटा की कई पंक्तियों के लिए किया जा सकता है, जब तक कि उन्हें सही ढंग से स्वरूपित किया जाता है। हमारे उदाहरण में हम केवल दो नए शिक्षक जोड़ेंगे, उदाहरण के लिए, लेकिन सिद्धांत रूप में हम जितने चाहें उतने जोड़ सकते हैं।
आइए आगे बढ़ते हैं और इस क्वेरी को निष्पादित करते हैं और शिक्षकों को हमारे डेटाबेस में जोड़ते हैं।
connection = create_db_connection("localhost", "root", pw, db)
execute_list_query(connection, sql, val)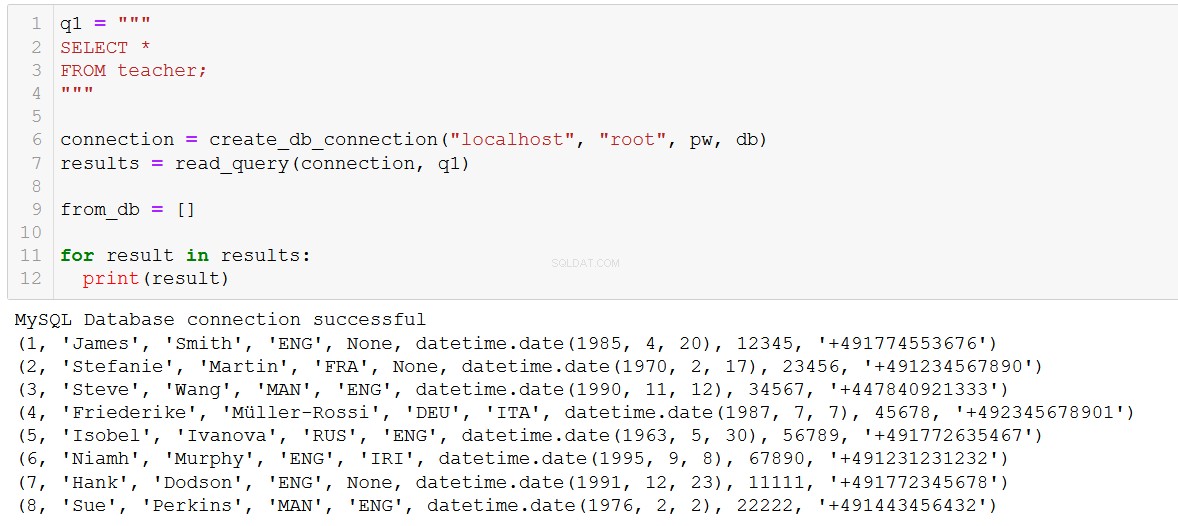
ILS, हैंक और सू में आपका स्वागत है!
This is yet another deeply useful function, allowing us to take data generated in our Python scripts and applications, and enter them directly into our database.
निष्कर्ष
We have covered a lot of ground in this tutorial.
We have learned how to use Python and MySQL Connector to create an entirely new database in MySQL Server, create tables within that database, define the relationships between those tables, and populate them with data.
We have covered how to Create, Read, Update and Delete data in our database.
We have looked at how to extract data from existing databases and load them into pandas DataFrames, ready for analysis and further work taking advantage of all the possibilities offered by the PyData stack.
Going in the other direction, we have also learned how to take data generated by our Python scripts and applications, and write those into a database where they can be safely stored for later retrieval and manipulation.
I hope this tutorial has helped you to see how we can use Python and SQL together to be able to manipulate data even more effectively!
If you'd like to see more of my projects and work, please visit my website at craigdoesdata.de. If you have any feedback on this tutorial, please contact me directly - all feedback is warmly received!