"पूर्ण तालिका स्कैन हमेशा खराब नहीं होते हैं। अनुक्रमणिका हमेशा अच्छी नहीं होती हैं।"
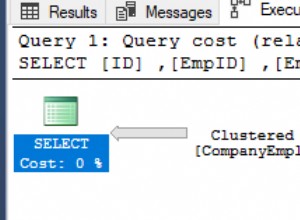
एक इंडेक्स-आधारित एक्सेस विधि पूर्ण स्कैन की तुलना में पंक्तियों को पढ़ने में कम कुशल होती है जब आप इसे काम की प्रति यूनिट (आमतौर पर प्रति लॉजिकल रीड) तक पहुंचने वाली पंक्तियों के संदर्भ में मापते हैं। हालांकि कई टूल एक पूर्ण तालिका स्कैन को अक्षमता के संकेत के रूप में व्याख्यायित करेंगे।
एक उदाहरण लें जहां आप एक चालान तालिका से कुछ सौ चालान पढ़ रहे हैं और एक छोटी लुकअप तालिका में भुगतान विधि देख रहे हैं। प्रत्येक इनवॉइस के लिए लुकअप टेबल की जांच के लिए एक इंडेक्स का उपयोग करने का मतलब शायद तीन या चार लॉजिकल आईओ प्रति चालान है। हालांकि, इनवॉइस डेटा से हैश जॉइन की तैयारी में लुकअप टेबल के एक पूर्ण स्कैन के लिए शायद केवल कुछ तार्किक रीड्स की आवश्यकता होगी, और हैश जॉइन लगभग बिना किसी लागत के मेमोरी में कम हो जाएगा।
हालांकि कई टूल इसे देखेंगे और "पूर्ण तालिका स्कैन" देखेंगे, और आपको इंडेक्स का उपयोग करने का प्रयास करने के लिए कहेंगे। अगर आप ऐसा करते हैं तो हो सकता है कि आपने अभी-अभी अपना कोड डी-ट्यून किया हो।
संयोग से, उपरोक्त उदाहरण के अनुसार, अनुक्रमित पर निर्भरता, "बफर कैश हिट अनुपात" को बढ़ने का कारण बनती है। यही कारण है कि बीसीएचआर सिस्टम दक्षता के भविष्यवक्ता के रूप में ज्यादातर बकवास है।