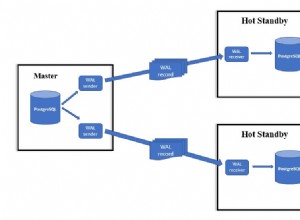
NVARCHAR2 डेटाटाइप Oracle द्वारा उन डेटाबेस के लिए पेश किया गया था जो कुछ कॉलम के लिए यूनिकोड का उपयोग करना चाहते हैं, जबकि बाकी डेटाबेस के लिए एक और कैरेक्टर सेट रखते हैं (जो VARCHAR2 का उपयोग करता है)। NVARCHAR2 एक यूनिकोड-ओनली डेटाटाइप है।
NVARCHAR2 का उपयोग करने का एक कारण यह हो सकता है कि आपका DB एक गैर-यूनिकोड वर्ण सेट का उपयोग करता है और आप अभी भी प्राथमिक वर्ण सेट को बदले बिना कुछ स्तंभों के लिए यूनिकोड डेटा संग्रहीत करने में सक्षम होना चाहते हैं। दूसरा कारण यह हो सकता है कि आप दो यूनिकोड कैरेक्टर सेट का उपयोग करना चाहते हैं (डेटा के लिए AL32UTF8 जो ज्यादातर पश्चिमी यूरोप से आता है, AL16UTF16 डेटा के लिए जो ज्यादातर एशिया से आता है) क्योंकि अलग-अलग कैरेक्टर सेट समान डेटा को समान रूप से कुशलता से स्टोर नहीं करेंगे।
आपके उदाहरण में दोनों कॉलम (यूनिकोड VARCHAR2(10 CHAR) और NVARCHAR2(10) ) एक ही डेटा को स्टोर करने में सक्षम होगा, हालांकि बाइट स्टोरेज अलग होगा। कुछ तारों को एक या दूसरे में अधिक कुशलता से संग्रहीत किया जा सकता है।
यह भी ध्यान दें कि कुछ सुविधाएँ NVARCHAR2 के साथ काम नहीं करेंगी, यह SO प्रश्न देखें:
- Oracle टेक्स्ट NVARCHAR2 के साथ काम नहीं करेगा। और क्या अनुपलब्ध हो सकता है?