एक Oracle डेवलपर जो अक्सर जल्दी या बाद में कोड में नियमित अभिव्यक्तियों का उपयोग करता है, एक ऐसी घटना का सामना कर सकता है जो वास्तव में रहस्यमय है। समस्या की जड़ की लंबी अवधि की खोज से वजन कम हो सकता है, भूख लग सकती है और विभिन्न प्रकार के मनोदैहिक विकार हो सकते हैं - यह सब regexp_replace फ़ंक्शन की मदद से रोका जा सकता है। इसमें अधिकतम 6 तर्क हो सकते हैं:
REGEXP_REPLACE (
- source_string,
- टेम्पलेट,
- प्रतिस्थापन_स्ट्रिंग,
- टेम्पलेट के साथ मिलान खोज की प्रारंभ स्थिति (डिफ़ॉल्ट 1),
- स्रोत स्ट्रिंग में टेम्पलेट की घटना की स्थिति (डिफ़ॉल्ट रूप से 0 सभी घटनाओं के बराबर होती है),
- संशोधक (अब तक यह एक काला घोड़ा है)
)
संशोधित स्रोत_स्ट्रिंग लौटाता है जिसमें टेम्पलेट की सभी घटनाओं को प्रतिस्थापन_स्ट्रिंग पैरामीटर में दिए गए मान से बदल दिया जाता है। अक्सर फ़ंक्शन के एक छोटे संस्करण का उपयोग किया जाता है, जहां पहले 3 तर्क निर्दिष्ट होते हैं, जो कई समस्याओं को हल करने के लिए पर्याप्त है। मैं भी यही करूंगा। मान लीजिए कि हमें 'MASK:लोअर केस' स्ट्रिंग में तारक के साथ सभी स्ट्रिंग वर्णों को मास्क करने की आवश्यकता है। लोअरकेस वर्णों की श्रेणी निर्दिष्ट करने के लिए, '[a-z]' पैटर्न उपयुक्त होना चाहिए।
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual उम्मीद
+------------------+ | RESULT | +------------------+ | MASK: ***** **** | +------------------+
वास्तविकता
+------------------+ | RESULT | +------------------+ | *A**: ***** **** | +------------------+
यदि इस घटना को आपके डेटाबेस में पुन:प्रस्तुत नहीं किया गया है, तो आप अब तक भाग्यशाली हैं। लेकिन अधिक बार आप कोड में खोदना शुरू करते हैं, स्ट्रिंग्स को वर्णों के एक सेट से दूसरे में परिवर्तित करते हैं और अंत में, एक निराशा आती है।
समस्या को परिभाषित करना
सवाल उठता है - अक्षर 'ए' में ऐसा क्या खास है कि इसे बदला नहीं गया है क्योंकि बाकी बड़े अक्षरों को भी बदला नहीं जाना चाहिए था। हो सकता है कि इसके अलावा अन्य सही अक्षर हों। अपरकेस वर्णों की संपूर्ण वर्णमाला को देखना आवश्यक है।
select regexp_replace('ABCDEFJHIGKLMNOPQRSTUVWXYZ', '[a-z]', '*') as alphabet from dual
+----------------------------+
| ALPHABET |
+----------------------------+
| A************************* |
+----------------------------+ हालांकि
यदि फ़ंक्शन का छठा तर्क स्पष्ट रूप से निर्दिष्ट नहीं है, उदाहरण के लिए, 'i' केस-असंवेदनशीलता है या 'c' केस-सेंसिटिविटी है जब स्रोत स्ट्रिंग की तुलना टेम्पलेट से की जाती है, तो रेगुलर एक्सप्रेशन डिफ़ॉल्ट रूप से सत्र/डेटाबेस के NLS_SORT पैरामीटर का उपयोग करता है। उदाहरण के लिए:
select value from sys.nls_session_parameters where parameter = 'NLS_SORT' +---------+ | VALUE | +---------+ | ENGLISH | +---------+
यह पैरामीटर ORDER BY में छँटाई विधि निर्दिष्ट करता है। यदि हम साधारण व्यक्तिगत वर्णों को छाँटने की बात करते हैं, तो एक निश्चित द्विआधारी संख्या (NLSSORT- कोड) उनमें से प्रत्येक से मेल खाती है और वास्तव में इन संख्याओं के मान के आधार पर छँटाई होती है।
इसे स्पष्ट करने के लिए, आइए वर्णमाला के पहले और अंतिम कुछ अक्षर, लोअरकेस और अपरकेस दोनों को लें, और उन्हें सशर्त रूप से अव्यवस्थित तालिका सेट में रखें और इसे ABC कहें। फिर, आइए इस सेट को SYMBOL फ़ील्ड द्वारा सॉर्ट करें और प्रत्येक प्रतीक के आगे HEX प्रारूप में इसका NLSSORT-कोड प्रदर्शित करें।
with ABC as (
select column_value as symbol
from table(sys.odcivarchar2list('A','B','C','X','Y','Z','a','b','c','x','y','z'))
)
select symbol,
nlssort(symbol) nls_code_hex
from ABC
order by symbol
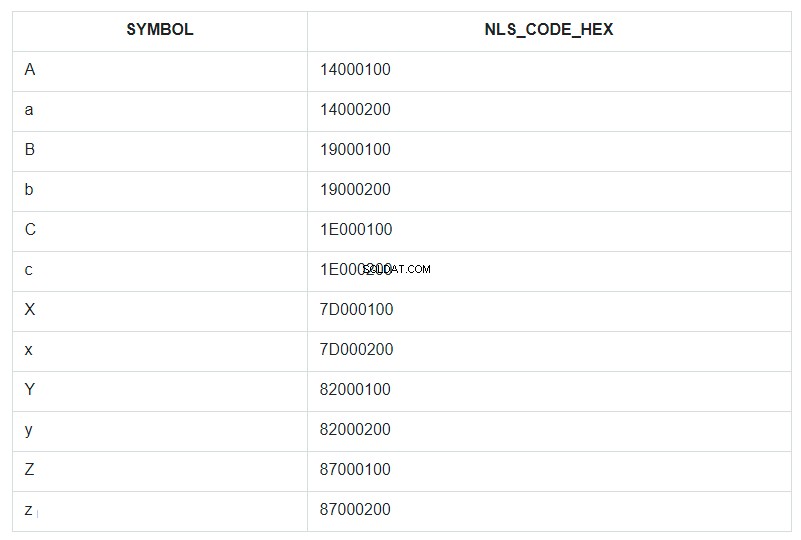
क्वेरी में, ORDER BY को SYMBOL फ़ील्ड के लिए निर्दिष्ट किया गया है, लेकिन वास्तव में, डेटाबेस में, सॉर्टिंग NLS_CODE_HEX फ़ील्ड के मानों के अनुसार होती है।
अब, टेम्प्लेट से रेंज पर वापस जाएं और तालिका को देखें - प्रतीक 'a' (कोड 14000200) और 'z' (कोड 87000200) के बीच लंबवत क्या है? कैपिटल लेटर 'ए' को छोड़कर सब कुछ। बस यही सब एक तारक से बदल दिया गया है। और 'ए' अक्षर का कोड 14000100 14000200 से 87000200 तक की रिप्लेसमेंट रेंज में शामिल नहीं है।
इलाज
केस-सेंसिटिविटी संशोधक स्पष्ट रूप से निर्दिष्ट करें
select regexp_replace('MASK: lower case', '[a-z]', '*', 1, 0, 'c') from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+
कुछ सूत्रों का कहना है कि संशोधक 'सी' डिफ़ॉल्ट रूप से सेट है, लेकिन हमने अभी देखा है कि यह बिल्कुल सच नहीं है। और अगर किसी ने इसे नहीं देखा है, तो इसके सत्र/डेटाबेस का NLS_SORT पैरामीटर सबसे अधिक BINARY पर सेट होने की संभावना है और छँटाई वास्तविक वर्णों के कोड के साथ पत्राचार में की जाती है। वास्तव में, यदि आप सत्र पैरामीटर बदलते हैं, तो समस्या हल हो जाएगी।
ALTER SESSION SET NLS_SORT=BINARY;
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+ Oracle 12c में परीक्षण किए गए।
बेझिझक अपनी टिप्पणी दें और ध्यान रखें।