अपडेट करें:2 सितंबर, 2021 (मूल रूप से 26 जुलाई 2012 को प्रकाशित।)
हमारे पसंदीदा डेटाबेस प्लेटफॉर्म के कुछ प्रमुख संस्करणों के दौरान बहुत सी चीजें बदल जाती हैं। SQL सर्वर 2016 हमारे लिए STRING_SPLIT लाया है, जो एक मूल फ़ंक्शन है जो हमारे द्वारा पहले आवश्यक कई कस्टम समाधानों की आवश्यकता को समाप्त करता है। यह तेज़ भी है, लेकिन यह सही नहीं है। उदाहरण के लिए, यह केवल एकल-वर्ण सीमांकक का समर्थन करता है, और यह इनपुट तत्वों के क्रम को इंगित करने के लिए कुछ भी वापस नहीं करता है। मैंने इस फ़ंक्शन के बारे में कई लेख लिखे हैं (और STRING_AGG, जो SQL सर्वर 2017 में आया था) जब से यह पोस्ट लिखा गया था:
- प्रदर्शन आश्चर्य और अनुमान :STRING_SPLIT() SQL सर्वर 2016 में
- STRING_SPLIT() :फ़ॉलो-अप #1 SQL सर्वर 2016 में
- STRING_SPLIT() :फॉलो-अप #2
- एसक्यूएल सर्वर स्प्लिट स्ट्रिंग रिप्लेसमेंट कोड STRING_SPLIT के साथ
- स्ट्रिंग विभाजन / संयोजन विधियों की तुलना करना
- SQL सर्वर के नए STRING_AGG और STRING_SPLIT फ़ंक्शन के साथ पुरानी समस्याओं का समाधान करें
- SQL सर्वर के STRING_SPLIT फ़ंक्शन में एकल-वर्ण सीमांकक से निपटना
- कृपया STRING_SPLIT सुधारों में सहायता करें
- SQL सर्वर में STRING_SPLIT को बेहतर बनाने का एक तरीका - और आप मदद कर सकते हैं
मैं वंश और ऐतिहासिक प्रासंगिकता के लिए नीचे दी गई सामग्री को यहां छोड़ने जा रहा हूं, और इसलिए भी कि कुछ परीक्षण पद्धति बंटवारे के तार के अलावा अन्य समस्याओं के लिए प्रासंगिक है, लेकिन कृपया उपरोक्त कुछ संदर्भ देखें कि आपको कैसे विभाजित किया जाना चाहिए SQL सर्वर के आधुनिक, समर्थित संस्करणों में स्ट्रिंग्स - साथ ही यह पोस्ट, जो बताती है कि विभाजन स्ट्रिंग शायद एक समस्या नहीं है जिसे आप डेटाबेस को पहले स्थान पर हल करना चाहते हैं, नया फ़ंक्शन या नहीं।
- स्प्लिटिंग स्ट्रिंग्स :अब कम टी-एसक्यूएल के साथ
मुझे पता है कि बहुत से लोग "स्प्लिट स्ट्रिंग्स" समस्या से ऊब चुके हैं, लेकिन यह अभी भी लगभग दैनिक मंच पर और स्टैक ओवरफ्लो जैसी क्यू एंड ए साइटों पर आता है। यह वह समस्या है जहां लोग इस तरह से एक स्ट्रिंग में गुजरना चाहते हैं:
EXEC dbo.UpdateProfile @UserID =1, @FavoriteTeams =N'Patriots,Red Sox,Bruins';
प्रक्रिया के अंदर, वे कुछ इस तरह करना चाहते हैं:
INSERT dbo.UserTeams(UserID, TeamID) dbo.Teams से @UserID, TeamID चुनें, जहां TeamName IN (@FavoriteTeams);
यह काम नहीं करता है क्योंकि @ पसंदीदा टीम एक एकल स्ट्रिंग है, और उपरोक्त का अनुवाद इस प्रकार है:
INSERT dbo.UserTeams(UserID, TeamID) dbo.Teams से @UserID, TeamID चुनें जहां TeamName IN (N'Patriots,Red Sox,Bruins');
इसलिए SQL सर्वर पैट्रियट्स, रेड सोक्स, ब्रुइन्स नामक एक टीम को खोजने का प्रयास करने जा रहा है। , और मेरा अनुमान है कि ऐसी कोई टीम नहीं है। वे वास्तव में यहां जो चाहते हैं वह इसके बराबर है:
INSERT dbo.UserTeams(UserID, TeamID) dbo.Teams से @UserID, TeamID चुनें जहां TeamName IN (N'Patriots', N'Red Sox', N'Bruins');
लेकिन चूंकि SQL सर्वर में कोई सरणी प्रकार नहीं है, इस तरह से चर की व्याख्या बिल्कुल नहीं की जाती है - यह अभी भी एक साधारण, एकल स्ट्रिंग है जिसमें कुछ अल्पविराम होते हैं। संदिग्ध स्कीमा डिज़ाइन एक तरफ, इस मामले में अल्पविराम से अलग की गई सूची को अलग-अलग मूल्यों में "विभाजित" करने की आवश्यकता है - और यही वह प्रश्न है जो अक्सर "नई" बहस और सबसे अच्छे समाधान के बारे में टिप्पणी करता है ताकि इसे प्राप्त किया जा सके।
उत्तर लगभग हमेशा प्रतीत होता है कि आपको सीएलआर का उपयोग करना चाहिए। यदि आप सीएलआर का उपयोग नहीं कर सकते हैं - और मुझे पता है कि आप में से कई ऐसे हैं जो कॉर्पोरेट नीति, नुकीले बालों वाले बॉस, या हठ के कारण नहीं कर सकते हैं - तो आप मौजूद कई कामकाज में से एक का उपयोग करते हैं। और कई समाधान मौजूद हैं।
लेकिन आपको किसका उपयोग करना चाहिए?
मैं कुछ समाधानों के प्रदर्शन की तुलना करने जा रहा हूँ - और उस प्रश्न पर ध्यान केंद्रित करूँगा जो हर कोई हमेशा पूछता है:"कौन सा सबसे तेज़ है?" मैं संभावित तरीकों के *सभी* के बारे में चर्चा नहीं करने जा रहा हूं, क्योंकि कई को इस तथ्य के कारण पहले ही समाप्त कर दिया गया है कि वे बस स्केल नहीं करते हैं। और मैं भविष्य में अन्य मेट्रिक्स पर प्रभाव की जांच करने के लिए इस पर फिर से जा सकता हूं, लेकिन अभी के लिए मैं केवल अवधि पर ध्यान केंद्रित करने जा रहा हूं। यहां वे दावेदार हैं जिनकी मैं तुलना करने जा रहा हूं (SQL Server 2012, 11.00.2316 का उपयोग करके, Windows 7 VM पर 4 CPU और 8 GB RAM के साथ):
सीएलआर
यदि आप सीएलआर का उपयोग करना चाहते हैं, तो आपको निश्चित रूप से अपने स्वयं के लिखने के बारे में सोचने से पहले साथी एमवीपी एडम मचानिक से कोड उधार लेना चाहिए (मैंने पहिया का पुन:आविष्कार करने से पहले ब्लॉग किया है, और यह इस तरह के मुफ्त कोड स्निपेट पर भी लागू होता है)। उन्होंने एक स्ट्रिंग को कुशलतापूर्वक पार्स करने के लिए इस सीएलआर फ़ंक्शन को ठीक करने में काफी समय बिताया। यदि आप वर्तमान में सीएलआर फ़ंक्शन का उपयोग कर रहे हैं और यह नहीं है, तो मैं दृढ़ता से अनुशंसा करता हूं कि आप इसे तैनात करें और तुलना करें - मैंने इसे बहुत सरल, वीबी-आधारित सीएलआर रूटीन के खिलाफ परीक्षण किया जो कार्यात्मक रूप से समकक्ष था, लेकिन वीबी दृष्टिकोण ने लगभग तीन गुना खराब प्रदर्शन किया एडम की तुलना में।
तो मैंने एडम के कार्य को लिया, कोड को एक डीएलएल (सीएससी का उपयोग करके) में संकलित किया, और उस फ़ाइल को सर्वर पर तैनात किया। फिर मैंने अपने डेटाबेस में निम्नलिखित असेंबली और फ़ंक्शन को जोड़ा:
PERMISSION_SET =SAFE के साथ 'c:\DLLs\CLRUtilities.dll' से असेंबली CLRUटिलिटीज बनाएं; GO CREATE FUNCTION dbo.SplitStrings_CLR( @List NVARCHAR (MAX), @Delimiter NVARCHAR (255)) आइटम NVHAR ( NVARCHAR (255) लौटाता है। ) )बाहरी नाम CLRUtilities.UserDefinedFunctions.SplitString_Multi;GO
XML
यह वह विशिष्ट कार्य है जिसका उपयोग मैं एकबारगी परिदृश्यों के लिए करता हूं जहां मुझे पता है कि इनपुट "सुरक्षित" है, लेकिन यह वह नहीं है जिसकी मैं उत्पादन वातावरण के लिए अनुशंसा करता हूं (नीचे उस पर अधिक)।
CREATE FUNCTION dbo.SplitStrings_XML(@List NVARCHAR(MAX), @Delimiter NVARCHAR(255)) SCHEMABINDINGAS RETURN के साथ टेबल लौटाता है ( आइटम चुनें =y.i.value ('(./text())[1]', 'nvarchar( 4000)') से ( SELECT x =CONVERT(XML, '' + REPLACE(@List, @Delimiter, '') + '').query('. ')) एक क्रॉस लागू के रूप में x.nodes('i') AS y(i) );GO एक्सएमएल दृष्टिकोण के साथ एक बहुत मजबूत चेतावनी को सवारी करना पड़ता है:इसका उपयोग केवल तभी किया जा सकता है जब आप गारंटी दे सकते हैं कि आपकी इनपुट स्ट्रिंग में कोई अवैध एक्सएमएल वर्ण नहीं है। <,> या &के साथ एक नाम और फ़ंक्शन उड़ जाएगा। तो प्रदर्शन के बावजूद, यदि आप इस दृष्टिकोण का उपयोग करने जा रहे हैं, तो सीमाओं से अवगत रहें - इसे सामान्य स्ट्रिंग स्प्लिटर के लिए व्यवहार्य विकल्प नहीं माना जाना चाहिए। मैं इसे इस राउंड-अप में शामिल कर रहा हूं क्योंकि आपके पास एक ऐसा मामला हो सकता है जहां आप कर सकते हैं इनपुट पर भरोसा करें - उदाहरण के लिए पूर्णांकों या GUID की अल्पविराम से अलग की गई सूचियों के लिए इसका उपयोग करना संभव है।
संख्या तालिका
यह समाधान एक नंबर तालिका का उपयोग करता है, जिसे आपको स्वयं बनाना और पॉप्युलेट करना होगा। (हम उम्र के लिए एक अंतर्निहित संस्करण का अनुरोध कर रहे हैं।) संख्या तालिका में पर्याप्त पंक्तियां होनी चाहिए जो आपके द्वारा विभाजित की जाने वाली सबसे लंबी स्ट्रिंग की लंबाई से अधिक हो। इस मामले में हम 1,000,000 पंक्तियों का उपयोग करेंगे:
नोकाउंट चालू करें; DECLARE @UpperLimit INT =1000000; एन एएस के साथ (सेलेक्ट x =ROW_NUMBER() ओवर (एस 1 द्वारा ऑर्डर करें। n जहां x 1 और @UpperLimit के बीच; GOCREATE UNIQUE CLUSTERED INDEX n ऑन dbo.Numbers(Number) with (DATA_COMPRESSION =PAGE);GO
(डेटा संपीड़न का उपयोग करने से आवश्यक पृष्ठों की संख्या में भारी कमी आएगी, लेकिन स्पष्ट रूप से आपको इस विकल्प का उपयोग केवल तभी करना चाहिए जब आप एंटरप्राइज़ संस्करण चला रहे हों। इस मामले में संपीड़ित डेटा के लिए 1,360 पृष्ठों की आवश्यकता होती है, बनाम 2,102 पृष्ठों को बिना संपीड़न के - लगभग 35% बचत। )
CREATE FUNCTION dbo.SplitStrings_Numbers(@List NVARCHAR(MAX), @Delimiter NVARCHAR(255)) SCHEMABINDINGAS RETURN के साथ टेबल लौटाएं ( आइटम का चयन करें =सबस्ट्रिंग(@सूची, संख्या, CHARINDEX(@Delimiter, @List + @Delimiter, @List + @Delimiter) ) - संख्या) dbo.Numbers से जहां नंबर <=CONVERT(INT, LEN(@List)) और SubSTRING(@Delimiter + @List, Number, LEN(@Delimiter)) =@Delimiter);GO
सामान्य तालिका अभिव्यक्ति
यह समाधान पिछले भाग के "शेष" से स्ट्रिंग के प्रत्येक भाग को निकालने के लिए एक पुनरावर्ती CTE का उपयोग करता है। स्थानीय चर के साथ एक पुनरावर्ती सीटीई के रूप में, आप देखेंगे कि यह एक बहु-कथन तालिका-मूल्यवान फ़ंक्शन होना चाहिए, अन्य सभी इनलाइन के विपरीत।
CREATE FUNCTION dbo.SplitStrings_CTE(@List NVARCHAR(MAX), @Delimiter NVARCHAR(255))SCHEMABINDINGASBEGIN DECLARE @ll INT =LEN(@List) + 1, @ के साथ @आइटम टेबल (आइटम NVARCHAR(4000)) रिटर्न एलडी आईएनटी =एलईएन(@Delimiter); एक AS के साथ (चुनें [प्रारंभ] =1, [अंत] =COALESCE(NULLIF(CHARINDEX(@Delimiter, @List, 1), 0), @ll), [मान] =सबस्ट्रिंग (@List, 1, COALESCE( NULLIF(CHARINDEX(@Delimiter, @List, 1), 0), @ll) - 1) यूनियन ऑल सेलेक्ट [स्टार्ट] =कन्वर्ट (INT, [end]) + @ld, [end] =COALESCE(NULLIF(CHARINDEX) (@Delimiter, @List, [end] + @ld), 0), @ll), [value] =सबस्ट्रिंग (@List, [end] + @ld, COALESCE(NULLIF(CHARINDEX(@Delimiter, @List, [अंत] + @ld), 0), @ll)-[end]-@ld) जहां से [अंत] <@ll ) INSERT @Items SELECT [value] फ्रॉम A WHERE LEN([value])> 0 विकल्प (अधिकतम सुधार 0); वापसी;ENDGO
जेफ मोडन का स्प्लिटर जेफ मोडन के स्प्लिटर पर आधारित एक फंक्शन जिसमें छोटे बदलावों के साथ लंबी स्ट्रिंग्स का समर्थन किया जाता है
SQLServerCentral पर, जेफ मोडन ने एक स्प्लिटर फ़ंक्शन प्रस्तुत किया जो CLR के प्रदर्शन को टक्कर देता था, इसलिए मैंने इस राउंड-अप में समान दृष्टिकोण का उपयोग करके भिन्नता को शामिल करना उचित समझा। अपनी सबसे लंबी स्ट्रिंग (500,000 वर्ण) को संभालने के लिए मुझे उनके कार्य में कुछ मामूली बदलाव करने पड़े, और नामकरण परंपराओं को भी समान बनाया:
CREATE FUNCTION dbo.SplitStrings_Moden(@List NVARCHAR(MAX), @Delimiter NVARCHAR(255)) E1(N) AS के साथ SCHEMABINDING ASRETURN के साथ तालिका लौटाता है (चुनें 1 यूनियन सभी का चयन करें 1 यूनियन सभी का चयन करें 1 यूनियन सभी का चयन करें चुनें 1 यूनियन सभी चुनें 1 यूनियन सभी चुनें 1 यूनियन सभी चुनें 1 यूनियन सभी चुनें 1 यूनियन सभी चुनें 1), ई 2 (एन) एएस (ई 1 ए, ई 1 बी से 1 चुनें), ई 4 (एन) एएस (ई 2 से 1 चुनें) a, E2 b), E42(N) AS (E4 a, E2 b से 1 चुनें), cteTally (N) AS (चुनें 0 यूनियन ऑल सेलेक्ट टॉप (DATALENGTH(ISNULL(@List,1))) ROW_NUMBER() ओवर (ऑर्डर बाय (चुनें NULL)) E42 से), cteStart(N1) AS (सेलेक्ट t.N+1 CteTally t WHERE (सबस्ट्रिंग(@List,t.N,1) =@Delimiter या t.N =0)) सेलेक्ट आइटम =सबस्ट्रिंग(@सूची, s.N1, ISNULL(NULLIF(CHARINDEX(@Delimiter,@List,s.N1),0)-s.N1,8000)) cteStart s से;
एक तरफ, जेफ़ मोडेन के समाधान का उपयोग करने वालों के लिए, आप ऊपर दी गई संख्या तालिका का उपयोग करने पर विचार कर सकते हैं, और जेफ के कार्य पर थोड़ी भिन्नता के साथ प्रयोग कर सकते हैं:
CREATE FUNCTION dbo.SplitStrings_Moden2(@List NVARCHAR(MAX), @Delimiter NVARCHAR(255)) CteTally(N) AS के साथ SCHEMABINDING ASRETURN टेबल के साथ रिटर्न्स (शीर्ष चुनें (DATALENGTH(ISNULL(@List,1))+1) नंबर -1 से dbo.Numbers BY नंबर), cteStart(N1) AS (चुनें t.N+1 cteTally से जहां (सबस्ट्रिंग(@सूची,t.N,1) =@Delimiter या t.N =0)) आइटम का चयन करें =SUBSTRING(@List, s.N1, ISNULL(NULLIF(CHARINDEX(@Delimiter, @List, s.N1), 0) - s.N1, 8000)) cteStart AS s से;
(यह थोड़ा कम CPU के लिए थोड़ा अधिक पढ़ता है, इसलिए यह इस पर निर्भर करता है कि आपका सिस्टम पहले से ही CPU- या I/O-बाउंड है या नहीं।)
स्वच्छता जांच
बस यह सुनिश्चित करने के लिए कि हम सही रास्ते पर हैं, हम यह सत्यापित कर सकते हैं कि सभी पांच फ़ंक्शन अपेक्षित परिणाम लौटाते हैं:
DECLARE @s NVARCHAR(MAX) =N'Patriots,Red Sox,Bruins'; dbo.SplitStrings_CLR (@s, N',') से आइटम का चयन करें; dbo.SplitStrings_XML (@s, N',') से आइटम का चयन करें; dbo.SplitStrings_CTE (@s, N',') से; dbo से आइटम चुनें। स्प्लिटस्ट्रिंग्स_मोडेन (@s, N',');
और वास्तव में, ये वे परिणाम हैं जो हम सभी पांच मामलों में देखते हैं…

टेस्ट डेटा
अब जब हम जानते हैं कि फ़ंक्शन अपेक्षा के अनुरूप व्यवहार करते हैं, तो हम मज़ेदार भाग पर पहुँच सकते हैं:लंबाई में भिन्न स्ट्रिंग्स की विभिन्न संख्याओं के विरुद्ध प्रदर्शन का परीक्षण करना। लेकिन पहले हमें एक टेबल चाहिए। मैंने निम्नलिखित सरल वस्तु बनाई:
टेबल बनाएं dbo.strings(string_type TINYINT, string_value NVARCHAR(MAX)); dbo.strings(string_type);पर क्लस्टर्ड इंडेक्स सेंट बनाएं
मैंने इस तालिका को अलग-अलग लंबाई के स्ट्रिंग्स के एक सेट के साथ पॉप्युलेट किया, यह सुनिश्चित करते हुए कि डेटा का लगभग एक ही सेट प्रत्येक परीक्षण के लिए उपयोग किया जाएगा - पहली 10,000 पंक्तियाँ जहाँ स्ट्रिंग 50 वर्ण लंबी है, फिर 1,000 पंक्तियाँ जहाँ स्ट्रिंग 500 वर्ण लंबी है , 100 पंक्तियाँ जहाँ स्ट्रिंग 5,000 वर्ण लंबी है, 10 पंक्तियाँ जहाँ स्ट्रिंग 50,000 वर्ण लंबी है, और इसी तरह 500,000 वर्णों की 1 पंक्ति तक। मैंने यह दोनों कार्यों द्वारा संसाधित किए जा रहे समग्र डेटा की समान मात्रा की तुलना करने के साथ-साथ अपने परीक्षण समय को कुछ हद तक अनुमानित रखने की कोशिश करने के लिए किया था।
मैं एक #temp तालिका का उपयोग करता हूं ताकि मैं प्रत्येक बैच को एक विशिष्ट संख्या में निष्पादित करने के लिए बस GO
सेट पर NOCOUNT ON;GOCREATE TABLE #x(s NVARCHAR(MAX)); INSERT #x SELECT N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,';GOINSERT dbo.strings SELECT 1, s from #x; GO 10000INSERT dbo.strings SELECT 2, REPLICATE(s,10) #x से; GO 1000INSERT dbo.strings SELECT 3, REPLICATE(s,100) from #x;GO 100INSERT dbo .स्ट्रिंग्स 4 चुनें, #x से रेप्लिकेट (एस, 1000); GO 10INSERT dbo.strings चुनें 5, REPLICATE(s,10000) #x से;GODROP TABLE #x;GO - फिर पीछे वाले कॉमा को साफ करने के लिए, क्योंकि कुछ दृष्टिकोण पिछली खाली स्ट्रिंग को एक मान्य तत्व के रूप में मानते हैं:UPDATE dbo.strings SET string_value =SUBSTRING(string_value, 1, LEN(string_value)-1) + 'x';
इस तालिका को बनाने और पॉप्युलेट करने में मेरी मशीन पर लगभग 20 सेकंड लगे, और तालिका लगभग 6 एमबी डेटा (लगभग 500,000 वर्ण 2 बाइट्स, या 1 एमबी प्रति स्ट्रिंग_टाइप, प्लस पंक्ति और इंडेक्स ओवरहेड) का प्रतिनिधित्व करती है। एक बड़ी तालिका नहीं है, लेकिन यह कार्यों के बीच प्रदर्शन में किसी भी अंतर को उजागर करने के लिए पर्याप्त बड़ी होनी चाहिए।
परीक्षा
जगह में कार्यों के साथ, और तालिका को चबाने के लिए बड़े तारों के साथ ठीक से भर दिया गया है, हम अंत में कुछ वास्तविक परीक्षण चला सकते हैं यह देखने के लिए कि वास्तविक डेटा के खिलाफ विभिन्न कार्य कैसे प्रदर्शन करते हैं। नेटवर्क ओवरहेड में फैक्टरिंग के बिना प्रदर्शन को मापने के लिए, मैंने एसक्यूएल सेंट्री प्लान एक्सप्लोरर का उपयोग किया, परीक्षणों के प्रत्येक सेट को 10 बार चला रहा था, अवधि मीट्रिक एकत्र कर रहा था, और औसत।
पहले परीक्षण ने प्रत्येक स्ट्रिंग से आइटम को एक सेट के रूप में खींचा:
DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE; घोषणा @string_type टिन्यिनट =; - ऊपर से 1-5 चुनें t. dbo.strings से dbo.strings के रूप में लागू करें dbo.SplitStrings_(s.string_value, ',') AS t WHERE s.string_type =@string_type;
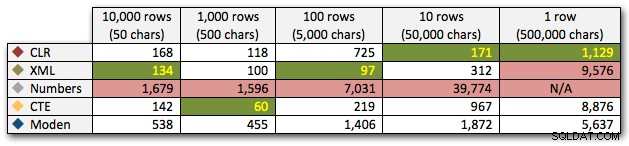
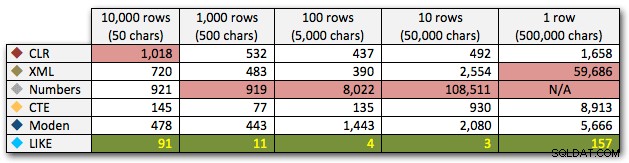
परिणाम बताते हैं कि जैसे-जैसे तार बड़े होते जाते हैं, सीएलआर का लाभ वास्तव में चमकता है। निचले सिरे पर, परिणाम मिश्रित थे, लेकिन फिर से XML पद्धति के आगे एक तारांकन चिह्न होना चाहिए, क्योंकि इसका उपयोग XML-सुरक्षित इनपुट पर निर्भर होने पर निर्भर करता है। इस विशिष्ट उपयोग के मामले में, Numbers तालिका ने लगातार सबसे खराब प्रदर्शन किया:
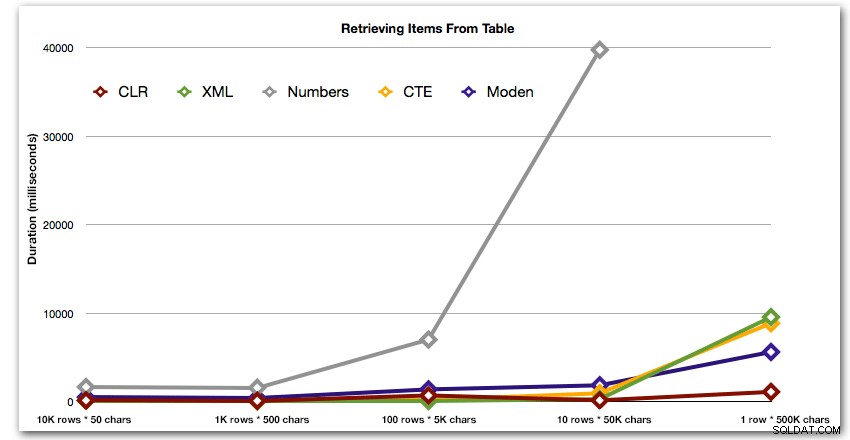
अवधि, मिलीसेकंड में
50,000 वर्णों की 10 पंक्तियों के विरुद्ध संख्या तालिका के लिए 40-सेकंड के अतिशयोक्तिपूर्ण प्रदर्शन के बाद, मैंने इसे अंतिम परीक्षण के लिए दौड़ से हटा दिया। इस परीक्षण में चार सर्वोत्तम विधियों के सापेक्ष प्रदर्शन को बेहतर ढंग से दिखाने के लिए, मैंने ग्राफ़ से Numbers परिणामों को पूरी तरह से हटा दिया है:
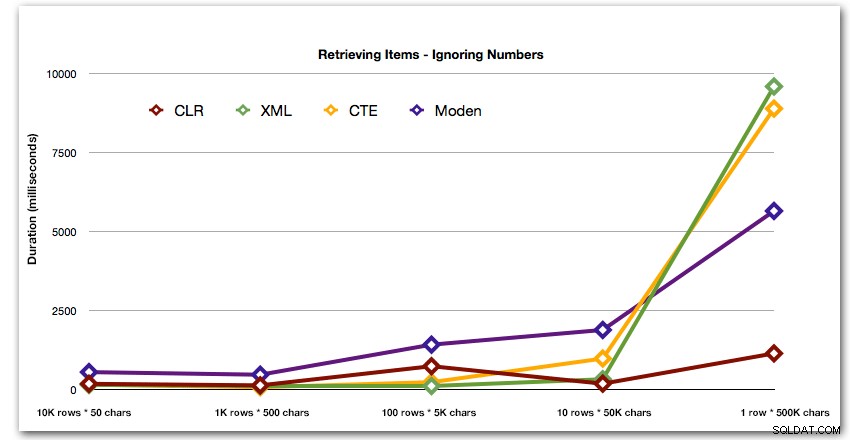
इसके बाद, आइए तुलना करते हैं जब हम अल्पविराम से अलग किए गए मान के विरुद्ध खोज करते हैं (उदाहरण के लिए उन पंक्तियों को वापस करें जहां स्ट्रिंग्स में से एक 'फू' है)। फिर से हम ऊपर दिए गए पांच कार्यों का उपयोग करेंगे, लेकिन हम परिणाम की तुलना रनटाइम पर की गई खोज के साथ विभाजन से परेशान करने के बजाय LIKE का उपयोग करके करेंगे।
DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE; DECLARE @i INT =, @search NVARCHAR(32) =N'foo';;s(st, sv) AS के साथ (चयन string_type, string_value dbo.strings से जहां string_type =@i) सेलेक्ट s.string_type, s.string_value से क्रॉस लागू dbo.SplitStrings_(s.sv, ',') जहां पर टी.आइटम =@खोज; dbo.strings से s.string_type चुनें जहां string_type =@i और ',' + string_value + ',' LIKE '%,' + @search + ',%';
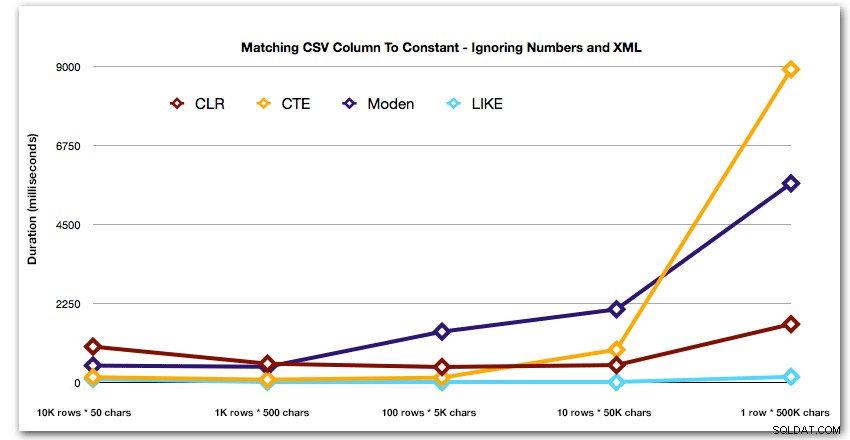
इन परिणामों से पता चलता है कि, छोटे तारों के लिए, सीएलआर वास्तव में सबसे धीमा था, और सबसे अच्छा समाधान डेटा को विभाजित करने के लिए परेशान किए बिना, LIKE का उपयोग करके स्कैन करना होगा। फिर से मैंने नंबर टेबल सॉल्यूशन को 5वें दृष्टिकोण से हटा दिया, जब यह स्पष्ट था कि जैसे-जैसे स्ट्रिंग का आकार बढ़ता जाएगा, इसकी अवधि तेजी से बढ़ेगी:
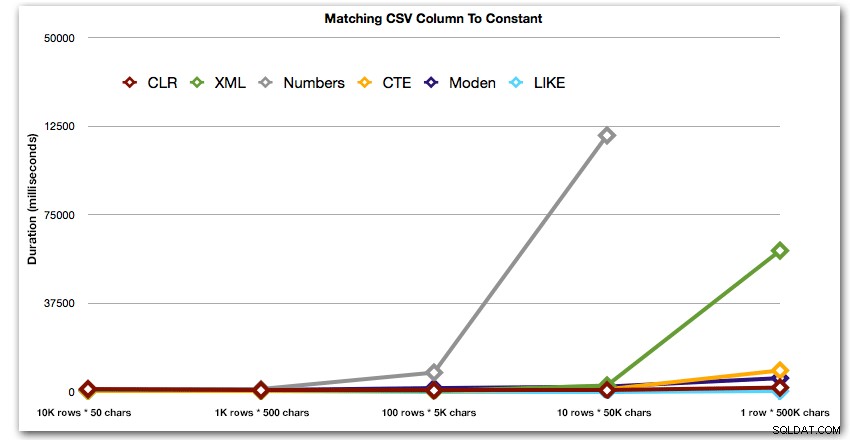
अवधि, मिलीसेकंड में
और शीर्ष 4 परिणामों के पैटर्न को बेहतर ढंग से प्रदर्शित करने के लिए, मैंने ग्राफ़ से Numbers और XML समाधान हटा दिए हैं:
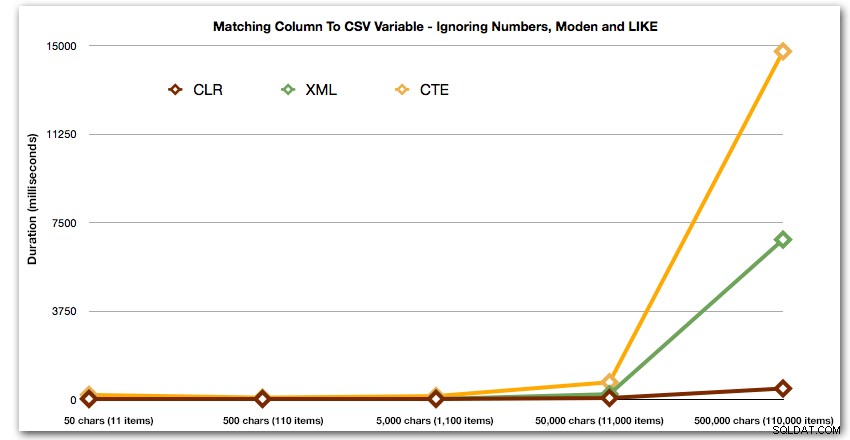
इसके बाद, आइए इस पोस्ट की शुरुआत से उपयोग के मामले की प्रतिकृति को देखें, जहां हम एक तालिका में सभी पंक्तियों को खोजने की कोशिश कर रहे हैं जो सूची में मौजूद हैं। जैसा कि ऊपर बनाई गई तालिका में डेटा के साथ है, हम ' 50 से 500,000 वर्णों की लंबाई में अलग-अलग तार बनाने जा रहे हैं, उन्हें एक चर में संग्रहीत करें, और फिर सूची में मौजूदा के लिए एक सामान्य कैटलॉग दृश्य की जाँच करें।
DECLARE @i INT =, -- मान 1-5, यील्डिंग स्ट्रिंग्स 50 - 500,000 वर्ण @x NVARCHAR(MAX) =N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge ,बेकन,'; सेट @x =प्रतिकृति(@x, शक्ति(10, @i-1)); SET @x =सबस्ट्रिंग (@x, 1, LEN(@x)-1) + 'x'; सी चुनें। [ऑब्जेक्ट_आईडी] sys.all_columns से जहां सी मौजूद है (डीबीओ से चुनें। स्प्लिटस्ट्रिंग्स_(@x, एन',') एएस एक्स जहां आइटम =सी.नाम) सी द्वारा आदेश। [object_id]; चुनें [object_id] sys.all_columns से जहां N',' + @x + ',' LIKE N'%,' + name + ',%' ऑर्डर द्वारा [object_id];
इन परिणामों से पता चलता है कि, इस पैटर्न के लिए, कई विधियों में उनकी अवधि तेजी से बढ़ती है क्योंकि स्ट्रिंग का आकार बढ़ता है। निचले सिरे पर, एक्सएमएल सीएलआर के साथ अच्छी गति रखता है, लेकिन यह जल्दी खराब भी हो जाता है। सीएलआर यहां लगातार स्पष्ट विजेता है:
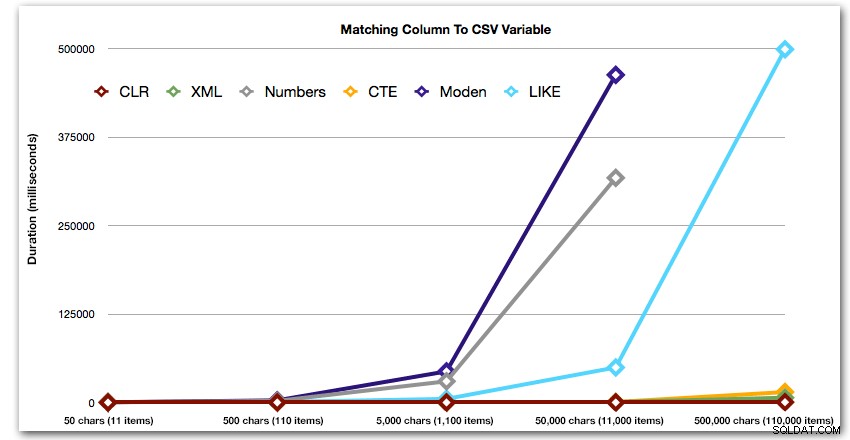
अवधि, मिलीसेकंड में
और फिर उन विधियों के बिना जो अवधि के संदर्भ में ऊपर की ओर विस्फोट करती हैं:
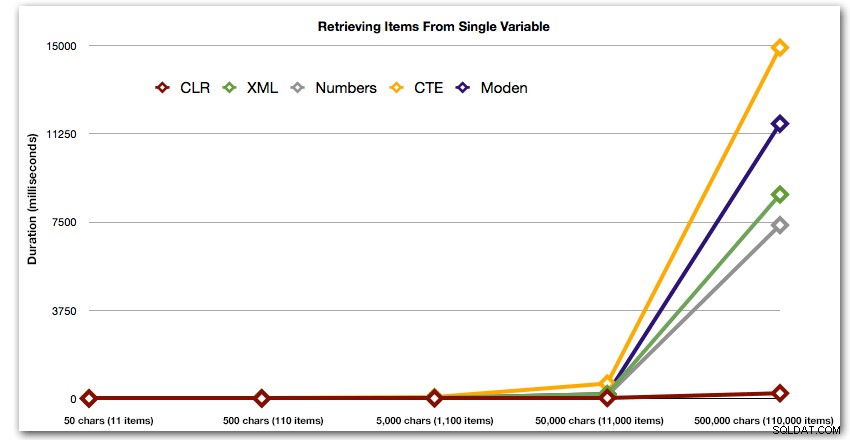
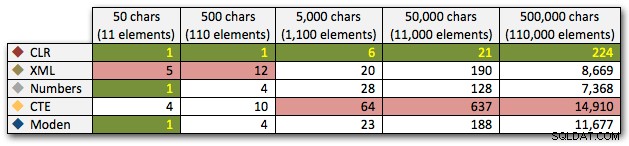
अंत में, आइए तालिका से डेटा पढ़ने की लागत को अनदेखा करते हुए, अलग-अलग लंबाई के एकल चर से डेटा पुनर्प्राप्त करने की लागत की तुलना करें। फिर से हम 50 - 500,000 वर्णों से अलग-अलग लंबाई के तार उत्पन्न करेंगे, और फिर मानों को एक सेट के रूप में वापस कर देंगे:
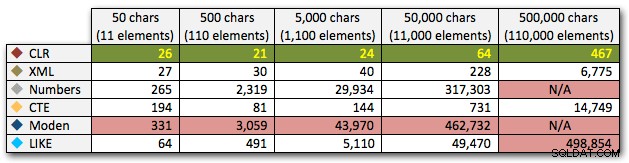
DECLARE @i INT =, -- मान 1-5, यील्डिंग स्ट्रिंग्स 50 - 500,000 वर्ण @x NVARCHAR(MAX) =N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge ,बेकन,'; सेट @x =प्रतिकृति(@x, शक्ति(10, @i-1)); SET @x =सबस्ट्रिंग (@x, 1, LEN(@x)-1) + 'x'; dbo.SplitStrings_(@x, N',') से आइटम चुनें;
इन परिणामों से यह भी पता चलता है कि सीएलआर अवधि के मामले में काफी सपाट है, सेट में 110,000 आइटम तक, जबकि अन्य तरीके 11,000 आइटम के बाद कुछ समय तक अच्छी गति रखते हैं:
अवधि, मिलीसेकंड में
निष्कर्ष
लगभग सभी मामलों में, सीएलआर समाधान स्पष्ट रूप से अन्य दृष्टिकोणों से बेहतर प्रदर्शन करता है - कुछ मामलों में यह एक शानदार जीत है, विशेष रूप से स्ट्रिंग आकार में वृद्धि के रूप में; कुछ अन्य में, यह एक फोटो फिनिश है जो किसी भी तरह से गिर सकता है। पहले परीक्षण में हमने देखा कि एक्सएमएल और सीटीई ने निचले सिरे पर सीएलआर का प्रदर्शन किया है, इसलिए यदि यह एक विशिष्ट उपयोग मामला है *और* तो आप सुनिश्चित हैं कि आपके तार 1 - 10,000 वर्ण श्रेणी में हैं, उनमें से एक दृष्टिकोण हो सकता है एक बेहतर विकल्प हो। यदि आपके स्ट्रिंग आकार उससे कम अनुमानित हैं, तो सीएलआर शायद अभी भी आपकी सबसे अच्छी शर्त है - आप कम अंत में कुछ मिलीसेकंड खो देते हैं, लेकिन आप उच्च अंत में बहुत कुछ हासिल करते हैं। यहां वे विकल्प दिए गए हैं जो मैं कार्य के आधार पर करूंगा, दूसरे स्थान पर उन मामलों के लिए हाइलाइट किया जाएगा जहां सीएलआर एक विकल्प नहीं है। ध्यान दें कि एक्सएमएल मेरी पसंदीदा विधि है, अगर मुझे पता है कि इनपुट एक्सएमएल-सुरक्षित है; अगर आपको अपने इनपुट पर कम विश्वास है तो ये जरूरी नहीं कि आपके सर्वोत्तम विकल्प हों।
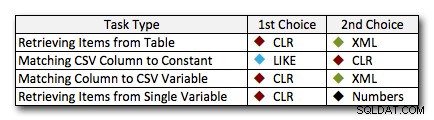
एकमात्र वास्तविक अपवाद जहां सीएलआर बोर्ड भर में मेरी पसंद नहीं है, वह मामला है जहां आप वास्तव में एक तालिका में अल्पविराम से अलग सूचियों को संग्रहीत कर रहे हैं, और फिर उन पंक्तियों को ढूंढ रहे हैं जहां एक परिभाषित इकाई उस सूची में है। उस विशिष्ट मामले में, मैं शायद पहले स्कीमा को फिर से डिज़ाइन करने और ठीक से सामान्य करने की अनुशंसा करता हूं, ताकि विभाजन के लिए सीएलआर का उपयोग न करने के बहाने के रूप में इसका उपयोग करने के बजाय उन मानों को अलग से संग्रहीत किया जा सके।
यदि आप अन्य कारणों से सीएलआर का उपयोग नहीं कर सकते हैं, तो इन परीक्षणों से कोई स्पष्ट "दूसरा स्थान" प्रकट नहीं होता है; ऊपर दिए गए मेरे उत्तर समग्र पैमाने पर आधारित थे न कि किसी विशिष्ट स्ट्रिंग आकार पर। यहां प्रत्येक समाधान कम से कम एक परिदृश्य में उपविजेता था - इसलिए जब आप इसका उपयोग कर सकते हैं तो सीएलआर स्पष्ट रूप से पसंद है, जब आप नहीं कर सकते हैं तो आपको क्या उपयोग करना चाहिए "यह निर्भर करता है" उत्तर - आपको इसके आधार पर निर्णय लेने की आवश्यकता होगी आपके उपयोग के मामले और उपरोक्त परीक्षण (या अपने स्वयं के परीक्षण बनाकर) आपके लिए कौन सा विकल्प बेहतर है।
Addendum :पहले स्थान पर बंटवारे का एक विकल्प
उपरोक्त दृष्टिकोणों को आपके मौजूदा एप्लिकेशन में किसी भी बदलाव की आवश्यकता नहीं है, यह मानते हुए कि वे पहले से ही अल्पविराम से अलग स्ट्रिंग को जोड़ रहे हैं और इसे निपटने के लिए डेटाबेस पर फेंक रहे हैं। एक विकल्प जिस पर आपको विचार करना चाहिए, यदि या तो सीएलआर एक विकल्प नहीं है और/या आप एप्लिकेशन को संशोधित कर सकते हैं, तो वह टेबल-वैल्यूड पैरामीटर्स (टीवीपी) का उपयोग कर रहा है। उपरोक्त संदर्भ में टीवीपी का उपयोग करने का एक त्वरित उदाहरण यहां दिया गया है। सबसे पहले, सिंगल स्ट्रिंग कॉलम के साथ एक टेबल टाइप बनाएं:
CREATE TYPE dbo.Items as TABLE(आइटम NVARCHAR(4000));
तब संग्रहीत प्रक्रिया इस टीवीपी को इनपुट के रूप में ले सकती है, और सामग्री में शामिल हो सकती है (या इसे अन्य तरीकों से उपयोग कर सकती है - यह सिर्फ एक उदाहरण है):
CREATE PROCEDURE dbo.UpdateProfile @UserID INT, @TeamNames dbo.Items READONLYASBEGIN SET NOCOUNT ON; INSERT dbo.UserTeams(UserID, TeamID) dbo से t.TeamID चुनें।अब आपके सी # कोड में, उदाहरण के लिए, अल्पविराम से अलग स्ट्रिंग बनाने के बजाय, डेटाटेबल को पॉप्युलेट करें (या जो भी संगत संग्रह पहले से ही आपके मूल्यों का सेट हो सकता है उसका उपयोग करें):
DataTable tvp =new DataTable();tvp.Columns.Add(new DataColumn("Item")); // एक संग्रह से एक लूप में, संभवतः:tvp.Rows.Add(someThing.someValue); (कनेक्शनऑब्जेक्ट) { SqlCommand cmd =new SqlCommand ("dbo.UpdateProfile", कनेक्शनऑब्जेक्ट) का उपयोग करके; cmd.CommandType =CommandType.StoreedProcedure; SqlParameter tvparam =cmd.Parameters.AddWithValue("@TeamNames", tvp); tvparam.SqlDbType =SqlDbType.Structured; // अन्य पैरामीटर, उदा। userId cmd.ExecuteNonQuery();}आप इसे किसी अनुवर्ती पोस्ट का प्रीक्वल मान सकते हैं।
बेशक यह JSON और अन्य API के साथ अच्छी तरह से नहीं खेलता है - अक्सर इसका कारण अल्पविराम से अलग की गई स्ट्रिंग को पहली बार SQL सर्वर में पास किया जा रहा है।



