इस महीने के टी-एसक्यूएल मंगलवार के लिए, स्टीव जोन्स (@way0utwest) ने हमें अपने सबसे अच्छे या सबसे खराब ट्रिगर अनुभवों के बारे में बात करने के लिए कहा। हालांकि यह सच है कि ट्रिगर्स अक्सर परेशान होते हैं, और यहां तक कि डरते भी हैं, उनके पास कई वैध उपयोग के मामले हैं, जिनमें शामिल हैं:
- लेखा परीक्षा (2016 SP1 से पहले, जब यह सुविधा सभी संस्करणों में निःशुल्क हो गई थी)
- व्यावसायिक नियमों का प्रवर्तन और डेटा अखंडता, जब उन्हें आसानी से बाधाओं में लागू नहीं किया जा सकता है, और आप नहीं चाहते कि वे एप्लिकेशन कोड या डीएमएल प्रश्नों पर निर्भर हों
- डेटा के ऐतिहासिक संस्करणों को बनाए रखना (डेटा कैप्चर बदलने, ट्रैकिंग बदलने और अस्थायी तालिकाएं बदलने से पहले)
- किसी विशिष्ट परिवर्तन के जवाब में अलर्ट या एसिंक्रोनस प्रोसेसिंग कतारबद्ध करना
- दृश्यों में संशोधन की अनुमति देना (ट्रिगर के बजाय)
यह एक विस्तृत सूची नहीं है, बस कुछ परिदृश्यों का एक त्वरित पुनर्कथन है जो मैंने अनुभव किया है जहां ट्रिगर्स उस समय सही उत्तर थे।
जब ट्रिगर्स आवश्यक होते हैं, तो मैं हमेशा ट्रिगर्स के बजाय INSTEAD OF ट्रिगर्स के उपयोग का पता लगाना पसंद करता हूं। हां, वे थोड़े अधिक अग्रिम कार्य हैं*, लेकिन उनके कुछ महत्वपूर्ण लाभ हैं। सिद्धांत रूप में, कम से कम, किसी कार्रवाई (और उसके लॉग परिणाम) को होने से रोकने की संभावना यह सब होने देने और फिर इसे पूर्ववत करने की तुलना में बहुत अधिक कुशल लगती है।
<ब्लॉकक्वॉट क्लास =डार्क>*मैं ऐसा इसलिए कह रहा हूं क्योंकि आपको ट्रिगर के भीतर फिर से डीएमएल स्टेटमेंट को कोड करना होगा; यही कारण है कि उन्हें ट्रिगर्स से पहले नहीं कहा जाता है। यहां भेद महत्वपूर्ण है, क्योंकि कुछ सिस्टम ट्रिगर से पहले सही लागू करते हैं, जो बस पहले चलते हैं। SQL सर्वर में, INSTEAD OF ट्रिगर प्रभावी रूप से उस कथन को रद्द कर देता है जिसके कारण यह आग लगी थी।
आइए मान लें कि हमारे पास खाता नामों को संग्रहीत करने के लिए एक सरल तालिका है। इस उदाहरण में हम दो टेबल बनाएंगे, ताकि हम दो अलग-अलग ट्रिगर और क्वेरी अवधि और लॉग उपयोग पर उनके प्रभाव की तुलना कर सकें। अवधारणा यह है कि हमारे पास एक व्यवसाय नियम है:खाता नाम किसी अन्य तालिका में मौजूद नहीं है, जो "खराब" नामों का प्रतिनिधित्व करता है, और इस नियम को लागू करने के लिए ट्रिगर का उपयोग किया जाता है। यहाँ डेटाबेस है:
USE [master];
GO
CREATE DATABASE [tr] ON (name = N'tr_dat', filename = N'C:\temp\tr.mdf', size = 4096MB)
LOG ON (name = N'tr_log', filename = N'C:\temp\tr.ldf', size = 2048MB);
GO
ALTER DATABASE [tr] SET RECOVERY FULL;
GO और टेबल:
USE [tr]; GO CREATE TABLE dbo.Accounts_After ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.Accounts_Instead ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.InvalidNames ( name sysname PRIMARY KEY ); INSERT dbo.InvalidNames(name) VALUES (N'poop'),(N'hitler'),(N'boobies'),(N'cocaine');
और, अंत में, ट्रिगर्स। सादगी के लिए, हम केवल इन्सर्ट के साथ काम कर रहे हैं, और केस के बाद और केस के बजाय दोनों में, अगर कोई एक नाम हमारे नियम का उल्लंघन करता है तो हम पूरे बैच को निरस्त करने जा रहे हैं:
CREATE TRIGGER dbo.tr_Accounts_After
ON dbo.Accounts_After
AFTER INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
ROLLBACK TRANSACTION;
RETURN;
END
END
GO
CREATE TRIGGER dbo.tr_Accounts_Instead
ON dbo.Accounts_After
INSTEAD OF INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
RETURN;
END
ELSE
BEGIN
INSERT dbo.Accounts_Instead(AccountID, name, filler)
SELECT AccountID, name, filler FROM inserted;
END
END
GO अब, प्रदर्शन का परीक्षण करने के लिए, हम प्रत्येक तालिका में 100,000 नाम डालने का प्रयास करेंगे, जिसकी अनुमानित विफलता दर 10% होगी। दूसरे शब्दों में, 90,000 नाम ठीक हैं, अन्य 10,000 परीक्षण में विफल हो जाते हैं और बैच के आधार पर ट्रिगर को या तो रोलबैक या सम्मिलित नहीं करते हैं।
सबसे पहले, हमें प्रत्येक बैच से पहले कुछ सफाई करनी होगी:
TRUNCATE TABLE dbo.Accounts_Instead; TRUNCATE TABLE dbo.Accounts_After; GO CHECKPOINT; CHECKPOINT; BACKUP LOG triggers TO DISK = N'C:\temp\tr.trn' WITH INIT, COMPRESSION; GO
इससे पहले कि हम प्रत्येक बैच का मांस शुरू करें, हम लेन-देन लॉग में पंक्तियों की गणना करेंगे, और आकार और खाली स्थान को मापेंगे। फिर हम प्रत्येक नाम को उपयुक्त तालिका में सम्मिलित करने का प्रयास करते हुए, यादृच्छिक क्रम में 100,000 पंक्तियों को संसाधित करने के लिए एक कर्सर के माध्यम से जाएंगे। जब हम काम पूरा कर लेंगे, तो हम लॉग की पंक्तियों की संख्या और आकार को फिर से मापेंगे, और अवधि की जांच करेंगे।
SET NOCOUNT ON;
DECLARE @batch varchar(10) = 'After', -- or After
@d datetime2(7) = SYSUTCDATETIME(),
@n nvarchar(129),
@i int,
@err nvarchar(512);
-- measure before and again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CONVERT(int, FILEPROPERTY(name,N'SpaceUsed')))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR
SELECT name, i = ROW_NUMBER() OVER (ORDER BY NEWID())
FROM
(
SELECT DISTINCT TOP (90000) LEFT(o.name,64) + '/' + LEFT(c.name,63)
FROM sys.all_objects AS o
CROSS JOIN sys.all_columns AS c
UNION ALL
SELECT TOP (10000) N'boobies' FROM sys.all_columns
) AS x (name)
ORDER BY i;
OPEN c;
FETCH NEXT FROM c INTO @n, @i;
WHILE @@FETCH_STATUS = 0
BEGIN
BEGIN TRY
IF @batch = 'After'
INSERT dbo.Accounts_After(AccountID,name) VALUES(@i,@n);
IF @batch = 'Instead'
INSERT dbo.Accounts_Instead(AccountID,name) VALUES(@i,@n);
END TRY
BEGIN CATCH
SET @err = ERROR_MESSAGE();
END CATCH
FETCH NEXT FROM c INTO @n, @i;
END
-- measure again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT duration = DATEDIFF(MILLISECOND, @d, SYSUTCDATETIME()),
CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CAST(FILEPROPERTY(name,N'SpaceUsed') AS int))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
CLOSE c; DEALLOCATE c; परिणाम (प्रत्येक बैच के औसत 5 रन से अधिक):
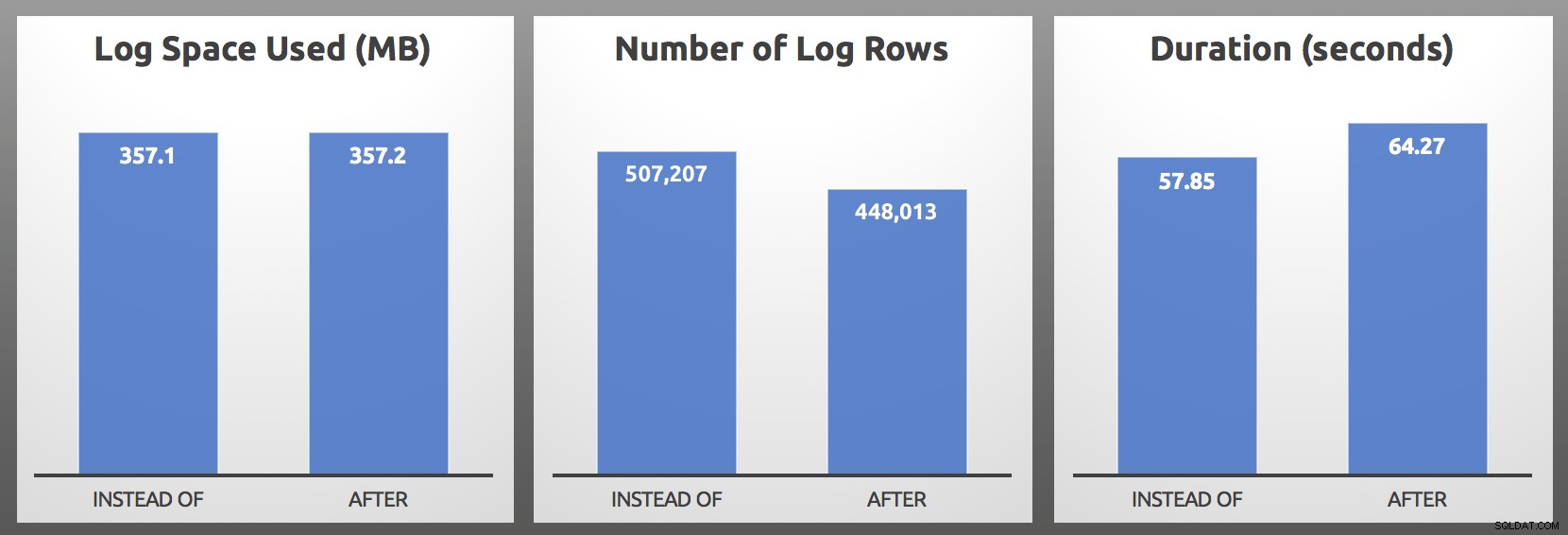 बाद बनाम INSTEAD OF :परिणाम
बाद बनाम INSTEAD OF :परिणाम
मेरे परीक्षणों में, लॉग का उपयोग आकार में लगभग समान था, INSTEAD OF ट्रिगर द्वारा उत्पन्न 10% से अधिक लॉग पंक्तियों के साथ। मैंने प्रत्येक बैच के अंत में कुछ खुदाई की:
SELECT [Operation], COUNT(*) FROM sys.fn_dblog(NULL, NULL) GROUP BY [Operation] ORDER BY [Operation];
और यहाँ एक विशिष्ट परिणाम था (मैंने प्रमुख डेल्टा पर प्रकाश डाला):
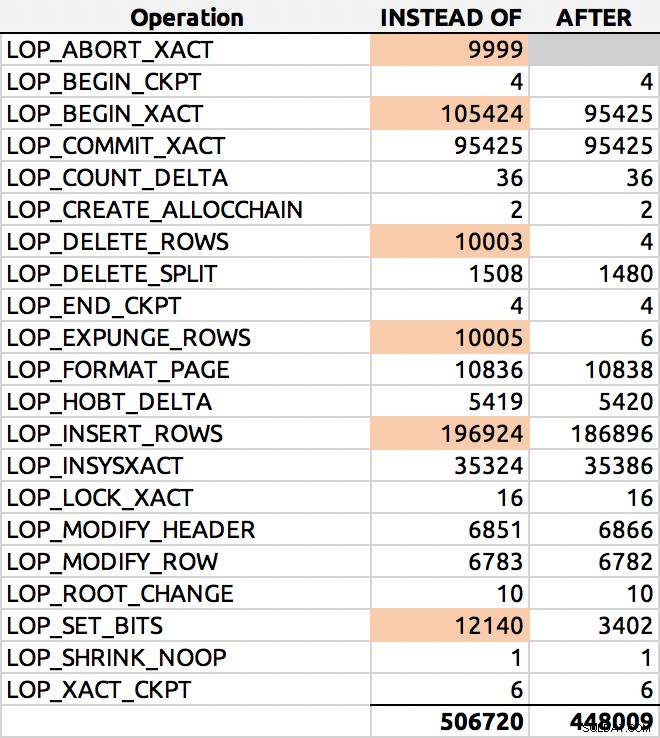 पंक्ति वितरण लॉग करें
पंक्ति वितरण लॉग करें
मैं उसमें और गहराई से दूसरी बार खुदाई करूंगा।
लेकिन जब आप इस पर सीधे उतरते हैं...
…सबसे महत्वपूर्ण मीट्रिक लगभग हमेशा अवधि होने वाली है , और मेरे मामले में INSTEAD OF ट्रिगर ने हर एक सिर से सिर के परीक्षण में कम से कम 5 सेकंड तेज प्रदर्शन किया। यदि यह सब परिचित लगता है, हाँ, मैंने इसके बारे में पहले भी बात की है, लेकिन उस समय मैंने लॉग पंक्तियों के साथ समान लक्षण नहीं देखे थे।
ध्यान दें कि यह आपकी सटीक स्कीमा या कार्यभार नहीं हो सकता है, आपके पास बहुत अलग हार्डवेयर हो सकते हैं, आपकी समरूपता अधिक हो सकती है, और आपकी विफलता दर बहुत अधिक (या कम) हो सकती है। मेरे परीक्षण एक अलग मशीन पर बहुत मेमोरी और बहुत तेज़ पीसीआई एसएसडी के साथ किए गए थे। यदि आपका लॉग धीमी ड्राइव पर है, तो लॉग उपयोग में अंतर अन्य मीट्रिक से अधिक हो सकता है और अवधियों को महत्वपूर्ण रूप से बदल सकता है। ये सभी कारक (और अधिक!) आपके परिणामों को प्रभावित कर सकते हैं, इसलिए आपको अपने परिवेश में परीक्षण करना चाहिए।
हालाँकि, मुद्दा यह है कि ट्रिगर्स के बजाय एक बेहतर फिट हो सकता है। अब अगर केवल हम INSTEAD OF DDL ट्रिगर्स प्राप्त कर सकते हैं…