नोट:यह पोस्ट मूल रूप से केवल हमारी eBook, SQL Server के लिए High Performance Techniques, खंड 2 में प्रकाशित हुई थी।
सारांश:यह लेख INSTEAD OF ट्रिगर्स के कुछ आश्चर्यजनक व्यवहार की जाँच करता है और SQL Server 2014 में एक गंभीर कार्डिनैलिटी अनुमान बग का खुलासा करता है।
ट्रिगर और रो वर्जनिंग
केवल डीएमएल ट्रिगर के बाद पंक्ति संस्करण (एसक्यूएल सर्वर 2005 में आगे) का उपयोग सम्मिलित प्रदान करने के लिए करता है और हटाया एक ट्रिगर प्रक्रिया के अंदर छद्म-सारणी। अधिकांश आधिकारिक दस्तावेजों में यह बात स्पष्ट रूप से नहीं कही गई है। अधिकांश स्थानों पर, दस्तावेज़ीकरण केवल यह कहता है कि पंक्ति-संस्करण का उपयोग सम्मिलित . बनाने के लिए किया जाता है और हटाया बिना योग्यता के ट्रिगर में टेबल (नीचे उदाहरण):
पंक्ति संस्करण संसाधन उपयोग
पंक्ति संस्करण-आधारित अलगाव स्तरों को समझना
बल्क आयात करते समय ट्रिगर निष्पादन को नियंत्रित करना
संभवतः, इन प्रविष्टियों के मूल संस्करण उत्पाद में INSTEAD OF ट्रिगर्स जोड़े जाने से पहले लिखे गए थे, और कभी भी अपडेट नहीं किए गए। या तो वह, या यह एक साधारण (लेकिन दोहराया) निरीक्षण है।
वैसे भी, जिस तरह से पंक्ति-संस्करण ट्रिगर के बाद काम करता है वह काफी सहज है। ये ट्रिगर आग के बाद विचाराधीन संशोधन किए गए हैं, इसलिए यह देखना आसान है कि कैसे संशोधित पंक्तियों के संस्करणों को बनाए रखना डेटाबेस इंजन को सम्मिलित प्रदान करने में सक्षम बनाता है और हटाया छद्म टेबल। हटाया गया संशोधनों से पहले प्रभावित पंक्तियों के संस्करणों से छद्म तालिका का निर्माण किया गया है; सम्मिलित ट्रिगर प्रक्रिया शुरू होने के समय प्रभावित पंक्तियों के संस्करणों से छद्म तालिका बनाई गई है।
ट्रिगर के बजाय
ट्रिगर्स के बजाय अलग हैं क्योंकि इस प्रकार का डीएमएल ट्रिगर पूरी तरह से प्रतिस्थापित . है ट्रिगर कार्रवाई। सम्मिलित और हटाया छद्म तालिकाएं अब उन परिवर्तनों को दर्शाती हैं जो होने वाले किया गया था, क्या ट्रिगरिंग स्टेटमेंट वास्तव में निष्पादित किया गया था। इन ट्रिगर्स के लिए रो-वर्जनिंग का उपयोग नहीं किया जा सकता क्योंकि परिभाषा के अनुसार कोई संशोधन नहीं हुआ है। तो, यदि पंक्ति संस्करणों का उपयोग नहीं कर रहा है, तो SQL सर्वर इसे कैसे करता है?
इसका उत्तर यह है कि जब एक INSTEAD OF ट्रिगर मौजूद होता है तो SQL सर्वर ट्रिगरिंग DML स्टेटमेंट के लिए निष्पादन योजना को संशोधित करता है। प्रभावित तालिकाओं को सीधे संशोधित करने के बजाय, निष्पादन योजना एक छिपे हुए कार्य तालिका में परिवर्तनों के बारे में जानकारी लिखती है। इस वर्कटेबल में मूल परिवर्तन करने के लिए आवश्यक सभी डेटा, प्रत्येक पंक्ति पर प्रदर्शन करने के लिए संशोधन का प्रकार (डिलीट या इंसर्ट), साथ ही OUTPUT क्लॉज के लिए ट्रिगर में आवश्यक कोई भी जानकारी शामिल है।
बिना किसी ट्रिगर के निष्पादन योजना
यह सब क्रिया में देखने के लिए, हम पहले एक INSTEAD OF ट्रिगर मौजूद के बिना एक साधारण परीक्षण चलाएंगे:
टेबल टेस्ट बनाएं (पंक्तिबद्ध पूर्णांक शून्य नहीं है, डेटा पूर्णांक शून्य नहीं है, सीमित PK_Test_RowID प्राथमिक कुंजी क्लस्टर (पंक्तिबद्ध)); GOINSERT dbo.Test (RowID, डेटा) मान (1, 100), (2, 200), ( 3, 300);GODELETE dbo.Test;GODROP TABLE dbo.Test;
हटाने के लिए निष्पादन योजना बहुत सीधी है:
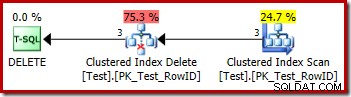
क्वालिफाई करने वाली प्रत्येक पंक्ति सीधे क्लस्टर्ड इंडेक्स डिलीट ऑपरेटर को पास कर दी जाती है, जो इसे हटा देता है। आसान।
ट्रिगर के बजाय निष्पादन योजना
आइए अब एक INSTEAD OF DELETE ट्रिगर शामिल करने के लिए परीक्षण को संशोधित करें (एक जो सरलता के लिए वही डिलीट क्रिया करता है):
टेबल टेस्ट बनाएं (पंक्तिबद्ध पूर्णांक शून्य नहीं है, डेटा पूर्णांक शून्य नहीं है, सीमित PK_Test_RowID प्राथमिक कुंजी क्लस्टर (पंक्तिबद्ध)); GOINSERT dbo.Test (RowID, डेटा) मान (1, 100), (2, 200), ( 3, 300);GOCREATE TRIGGER dbo_Test_IODON dbo.TestINSTEAD OF DELETEAS BEGIN SET NOCOUNT ON; dbo.Test से DELETE जहाँ मौजूद है ( सेलेक्ट करें * से Deleted जहाँ Deleted.RowID =dbo.Test.RowID );END;GODELETE dbo.Test;GODROP TABLE dbo.Test;
DELETE की निष्पादन योजना अब काफी भिन्न है:
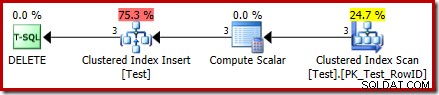
क्लस्टर्ड इंडेक्स डिलीट ऑपरेटर को क्लस्टर्ड इंडेक्स सम्मिलित करें से बदल दिया गया है . यह हिडन वर्कटेबल का इंसर्ट है, जिसे डिलीट से प्रभावित बेस टेबल के नाम पर (सार्वजनिक निष्पादन योजना प्रतिनिधित्व में) नाम दिया गया है। नामकरण तब होता है जब एक्सएमएल शो योजना आंतरिक निष्पादन योजना प्रतिनिधित्व से उत्पन्न होती है, इसलिए छिपे हुए कार्यबल को देखने का कोई दस्तावेज तरीका नहीं है।
इस परिवर्तन के परिणामस्वरूप, योजना इसलिए एक सम्मिलित करें . प्रदर्शन करती प्रतीत होती है हटाने . के लिए आधार तालिका में इससे पंक्तियाँ। यह भ्रमित करने वाला है, लेकिन यह कम से कम INSTEAD OF ट्रिगर की उपस्थिति का खुलासा करता है। इन्सर्ट ऑपरेटर को डिलीट के साथ बदलना और भी भ्रमित करने वाला हो सकता है। ट्रिगर वर्कटेबल के बजाय शायद आदर्श एक नया ग्राफिकल आइकन होगा? वैसे भी, यह वही है।
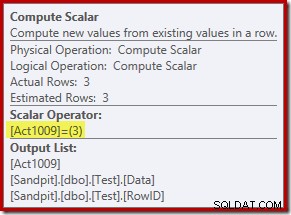
नया कंप्यूट स्केलर ऑपरेटर प्रत्येक पंक्ति पर की जाने वाली क्रिया के प्रकार को परिभाषित करता है। यह क्रिया कोड निम्नलिखित अर्थों के साथ एक पूर्णांक है:
- 3 =हटाएं
- 4 =सम्मिलित करें
- 259 =मर्ज योजना में हटाएं
- 260 =मर्ज योजना में सम्मिलित करें
इस क्वेरी के लिए, क्रिया एक स्थिर 3 है, जिसका अर्थ है कि प्रत्येक पंक्ति को हटाया जाना है :
अपडेट कार्रवाइयां
इसके अलावा, अद्यतन के बजाय निष्पादन योजना एकल अद्यतन ऑपरेटर को दो से बदल देती है एक ही छिपे हुए वर्कटेबल में क्लस्टर्ड इंडेक्स इंसर्ट - सम्मिलित . के लिए एक छद्म तालिका पंक्तियाँ, और एक हटाई गई . के लिए छद्म तालिका पंक्तियाँ। एक उदाहरण निष्पादन योजना:

एक MERGE जो UPDATE करता है, समान कारणों से एक ही बेस टेबल में दो इन्सर्ट के साथ एक एक्ज़ीक्यूशन प्लान भी तैयार करता है:

ट्रिगर निष्पादन योजना
ट्रिगर बॉडी के लिए निष्पादन योजना में कुछ दिलचस्प विशेषताएं भी हैं:
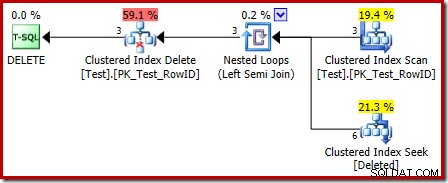
ध्यान देने वाली पहली बात यह है कि हटाए गए तालिका के लिए उपयोग किया गया ग्राफिकल आइकन ट्रिगर योजनाओं के बाद उपयोग किए गए आइकन जैसा नहीं है:
ट्रिगर योजना के बजाय में प्रतिनिधित्व एक क्लस्टर इंडेक्स सीक है। अंतर्निहित ऑब्जेक्ट वही आंतरिक वर्कटेबल है जिसे हमने पहले देखा था, हालांकि यहां इसका नाम डिलीट . है आधार तालिका नाम दिए जाने के बजाय, संभवतः ट्रिगर्स के बाद किसी प्रकार की संगति के लिए।
हटाए गए . पर तलाशी अभियान तालिका वह नहीं हो सकती है जिसकी आप अपेक्षा कर रहे थे (यदि आप RowID पर खोज की उम्मीद कर रहे थे):
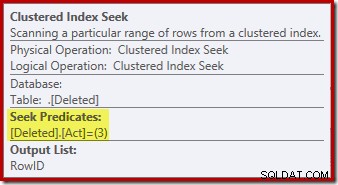
यह 'सीक' वर्कटेबल से सभी पंक्तियों को लौटाता है जिसमें 3 (डिलीट) का एक्शन कोड होता है, जो इसे डिलीट स्कैन के बिल्कुल बराबर बनाता है। ट्रिगर योजनाओं के बाद में देखा गया ऑपरेटर। सम्मिलित . दोनों के लिए पंक्तियों को होल्ड करने के लिए एक ही आंतरिक वर्कटेबल का उपयोग किया जाता है और हटाया ट्रिगर्स के बजाय छद्म-सारणी। एक सम्मिलित स्कैन के बराबर कार्रवाई कोड 4 पर एक खोज है (जो एक हटाने में संभव है ट्रिगर, लेकिन परिणाम हमेशा खाली रहेगा)। कार्रवाई पर गैर-अद्वितीय क्लस्टर इंडेक्स के अलावा आंतरिक वर्कटेबल पर कोई अनुक्रमणिका नहीं है अकेले स्तंभ। इसके अलावा, इस आंतरिक सूचकांक से जुड़े कोई आंकड़े नहीं हैं।
अब तक का विश्लेषण आपको आश्चर्यचकित कर सकता है कि RowID कॉलम के बीच जुड़ाव कहाँ किया जाता है। यह तुलना नेस्टेड लूप्स लेफ्ट सेमी जॉइन ऑपरेटर पर अवशिष्ट विधेय के रूप में होती है:
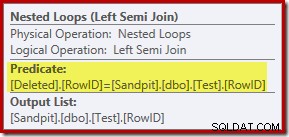
अब जब हम जानते हैं कि 'सीक' प्रभावी रूप से हटाए गए . का एक पूर्ण स्कैन है तालिका, क्वेरी ऑप्टिमाइज़र द्वारा चुनी गई निष्पादन योजना बहुत अक्षम लगती है। निष्पादन योजना का समग्र प्रवाह यह है कि परीक्षण तालिका से प्रत्येक पंक्ति की संभावित रूप से हटाए गए के पूरे सेट के साथ तुलना की जाती है पंक्तियाँ, जो एक कार्टेशियन उत्पाद की तरह लगती हैं।
बचत अनुग्रह यह है कि शामिल होना एक अर्ध-जुड़ाव है, जिसका अर्थ है कि किसी दिए गए परीक्षण पंक्ति के लिए तुलना प्रक्रिया जैसे ही पहले हटाई गई रुक जाती है पंक्ति अवशिष्ट विधेय को संतुष्ट करती है। फिर भी, रणनीति एक जिज्ञासु लगती है। शायद निष्पादन योजना बेहतर होगी यदि परीक्षण तालिका में अधिक पंक्तियाँ हों?
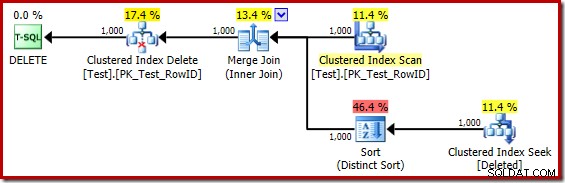
1,000 पंक्तियों के साथ परीक्षण ट्रिगर करें
बड़ी संख्या में पंक्तियों के साथ ट्रिगर का परीक्षण करने के लिए निम्न स्क्रिप्ट का उपयोग किया जा सकता है। हम 1,000 से शुरू करेंगे:
टेबल टेस्ट बनाएं (पंक्तिबद्ध पूर्णांक शून्य नहीं है, डेटा पूर्णांक शून्य नहीं है, सीमित PK_Test_RowID प्राथमिक कुंजी क्लस्टर (पंक्तिबद्ध)); GOSET सांख्यिकी एक्सएमएल बंद; GODECLARE @i पूर्णांक =1; जबकि @i <=1000BEGIN INSERT dbo.Test (RowID, डेटा) मान (@i, @i * 100); SET @i +=1;END;GOCREATE TRIGGER dbo_Test_IOD ON dbo.Test DELETE के बजाय BEGIN SET NOCOUNT ON; dbo.Test से हटाएं जहां मौजूद है ( चुनें * हटाए गए जहां से हटा दिया गया है।ट्रिगर बॉडी के लिए निष्पादन योजना अब है:
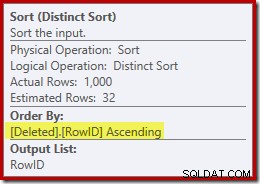
मानसिक रूप से (भ्रामक) क्लस्टर्ड इंडेक्स सीक को हटाए गए स्कैन के साथ बदलकर, योजना आम तौर पर बहुत अच्छी लगती है। ऑप्टिमाइज़र ने नेस्टेड लूप्स सेमी जॉइन के बजाय वन-टू-मैनी मर्ज जॉइन को चुना है, जो उचित लगता है। डिस्टिंक्ट सॉर्ट हालांकि एक जिज्ञासु जोड़ है:
यह प्रकार दो कार्य कर रहा है। सबसे पहले, यह मर्ज जॉइन को सॉर्ट किए गए इनपुट के साथ प्रदान कर रहा है, जो कि काफी उचित है क्योंकि आवश्यक ऑर्डर प्रदान करने के लिए आंतरिक वर्कटेबल पर कोई इंडेक्स नहीं है। दूसरी चीज जो सॉर्ट कर रही है वह है RowID पर अलग करना। यह अजीब लग सकता है, क्योंकि RowID बेस टेबल की प्राथमिक कुंजी है।
समस्या यह है कि हटाई गई . में पंक्तियाँ तालिका केवल उम्मीदवार पंक्तियाँ हैं जिन्हें मूल DELETE क्वेरी की पहचान की गई है। ट्रिगर के बाद के विपरीत, इन पंक्तियों की अभी तक बाधा या कुंजी उल्लंघनों के लिए जाँच नहीं की गई है, इसलिए क्वेरी प्रोसेसर की कोई गारंटी नहीं है कि वे वास्तव में अद्वितीय हैं।
आम तौर पर, ट्रिगर्स के INSTEAD के साथ ध्यान में रखना एक बहुत ही महत्वपूर्ण बिंदु है:इस बात की कोई गारंटी नहीं है कि प्रदान की गई पंक्तियां बेस टेबल पर किसी भी बाधा को पूरा करती हैं (नल सहित)। यह न केवल ट्रिगर लेखक को याद रखने के लिए महत्वपूर्ण है; यह क्वेरी ऑप्टिमाइज़र द्वारा किए जा सकने वाले सरलीकरण और परिवर्तनों को भी सीमित करता है।
उपरोक्त सॉर्ट गुणों में दिखाया गया एक दूसरा मुद्दा, लेकिन हाइलाइट नहीं किया गया है, यह है कि आउटपुट अनुमान केवल 32 पंक्तियां है। आंतरिक वर्कटेबल में इससे जुड़े कोई आंकड़े नहीं हैं, इसलिए अनुकूलक अनुमान करता है डिस्टिंक्ट ऑपरेशन के प्रभाव में। हम जानते हैं कि RowID मान अद्वितीय हैं, लेकिन बिना किसी कठिन जानकारी के, ऑप्टिमाइज़र खराब अनुमान लगाता है। यह समस्या हमें अगले परीक्षण में परेशान करेगी।
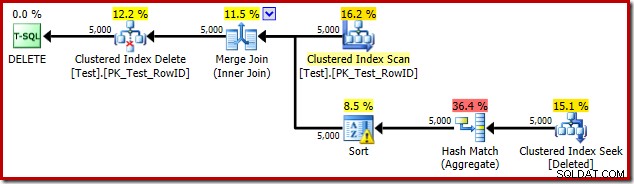
5,000 पंक्तियों के साथ परीक्षण ट्रिगर करें
अब 5,000 पंक्तियाँ उत्पन्न करने के लिए परीक्षण स्क्रिप्ट को संशोधित करें:
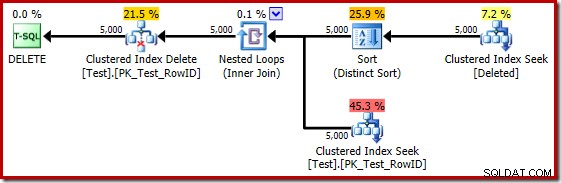
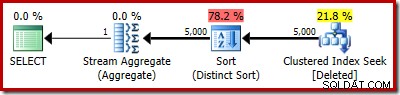
टेबल टेस्ट बनाएं (पंक्तिबद्ध पूर्णांक शून्य नहीं है, डेटा पूर्णांक शून्य नहीं है, सीमित PK_Test_RowID प्राथमिक कुंजी क्लस्टर (पंक्तिबद्ध)); GOSET सांख्यिकी एक्सएमएल बंद; GODECLARE @i पूर्णांक =1; जबकि @i <=5000BEGIN INSERT dbo.Test (RowID, डेटा) मान (@i, @i * 100); SET @i +=1;END;GOCREATE TRIGGER dbo_Test_IOD ON dbo.Test DELETE के बजाय BEGIN SET NOCOUNT ON; dbo.Test से हटाएं जहां मौजूद है ( चुनें * हटाए गए जहां से हटा दिया गया है।ट्रिगर निष्पादन योजना है:
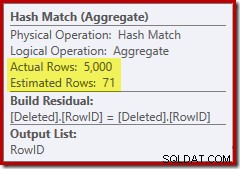
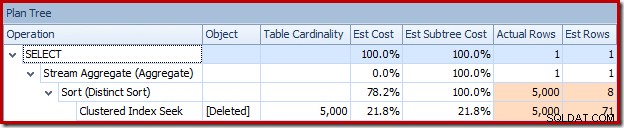
इस बार ऑप्टिमाइज़र ने अलग और सॉर्ट ऑपरेशंस को विभाजित करने का निर्णय लिया है। RowID पर विशिष्ट हैश मैच (एग्रीगेट) ऑपरेटर द्वारा किया जाता है:
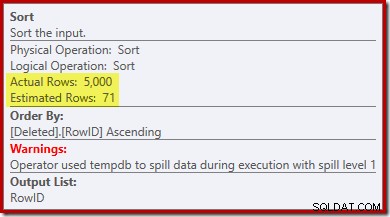
ध्यान दें कि आउटपुट के लिए ऑप्टिमाइज़र का अनुमान 71 पंक्तियाँ है। वास्तव में, सभी 5,000 पंक्तियाँ विशिष्ट बनी रहती हैं क्योंकि RowID अद्वितीय है। गलत अनुमान का मतलब है कि क्वेरी मेमोरी ग्रांट का एक अपर्याप्त अंश सॉर्ट को आवंटित किया जाता है, जो tempdb तक फैल जाता है। :
निष्पादन योजना में सॉर्ट चेतावनी देखने के लिए यह परीक्षण SQL Server 2012 या उच्चतर पर किया जाना है। पिछले संस्करणों में, योजना में स्पिल के बारे में कोई जानकारी नहीं है - इसे प्रकट करने के लिए सॉर्ट चेतावनियों पर एक प्रोफाइलर ट्रेस की आवश्यकता होगी (और आपको इसे किसी भी तरह स्रोत क्वेरी से सहसंबंधित करने की आवश्यकता होगी)।
SQL सर्वर 2014 पर 5,000 पंक्तियों के साथ परीक्षण ट्रिगर करें
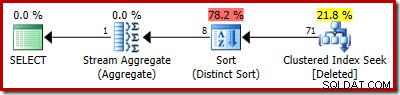
यदि पिछला परीक्षण SQL सर्वर 2014 पर दोहराया जाता है, तो डेटाबेस में संगतता स्तर 120 पर सेट किया गया है ताकि नए कार्डिनैलिटी अनुमानक (सीई) का उपयोग किया जा सके, ट्रिगर निष्पादन योजना फिर से अलग है:
कुछ मायनों में, यह निष्पादन योजना एक सुधार की तरह लगती है। (अनावश्यक) डिस्टिंक्ट सॉर्ट अभी भी मौजूद है, लेकिन समग्र रणनीति अधिक स्वाभाविक लगती है:हटाए गए में प्रत्येक विशिष्ट उम्मीदवार RowID के लिए तालिका, आधार तालिका में शामिल हों (ताकि सत्यापित करें कि उम्मीदवार पंक्ति वास्तव में मौजूद है) और फिर इसे हटा दें।
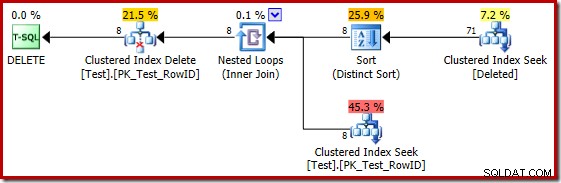
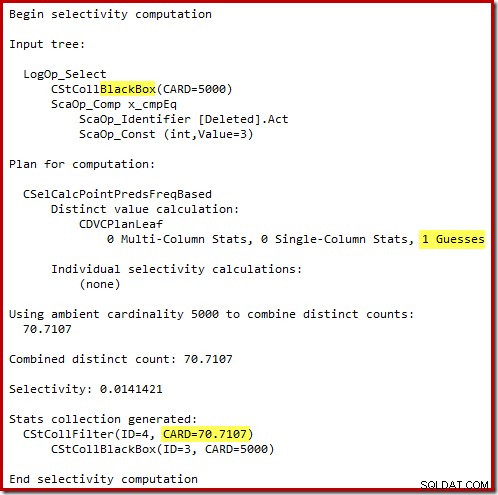
दुर्भाग्य से, 2014 की योजना SQL सर्वर 2012 की तुलना में खराब कार्डिनैलिटी अनुमानों पर आधारित है। अनुमानित प्रदर्शित करने के लिए SQL संतरी योजना एक्सप्लोरर को स्विच करना पंक्ति गणना समस्या को स्पष्ट रूप से दिखाती है:
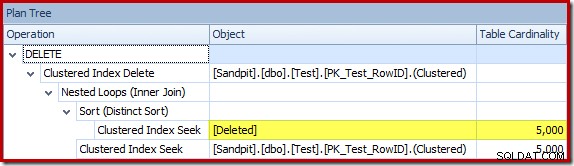
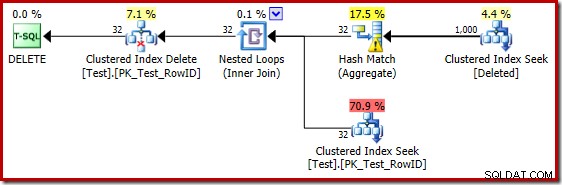
ऑप्टिमाइज़र ने शामिल होने के लिए नेस्टेड लूप्स रणनीति को चुना क्योंकि यह अपने शीर्ष इनपुट पर बहुत कम पंक्तियों की अपेक्षा करता था। क्लस्टर्ड इंडेक्स सीक में पहली समस्या उत्पन्न होती है। ऑप्टिमाइज़र जानता है कि इस बिंदु पर हटाए गए तालिका में 5,000 पंक्तियाँ हैं, जैसा कि हम प्लान ट्री व्यू पर स्विच करके और वैकल्पिक टेबल कार्डिनैलिटी कॉलम (जो मैं चाहता हूं कि डिफ़ॉल्ट रूप से शामिल किया गया था) जोड़कर देख सकते हैं:
SQL सर्वर 2012 और पहले में 'पुराना' कार्डिनैलिटी अनुमानक यह जानने के लिए पर्याप्त स्मार्ट है कि आंतरिक वर्कटेबल पर 'सीक' सभी 5,000 पंक्तियों को वापस कर देगा (इसलिए इसने मर्ज जॉइन को चुना)। नया सीई इतना स्मार्ट नहीं है। यह वर्कटेबल को 'ब्लैक बॉक्स' के रूप में देखता है और सीक ऑन एक्शन कोड =3:
के प्रभाव का अनुमान लगाता है।
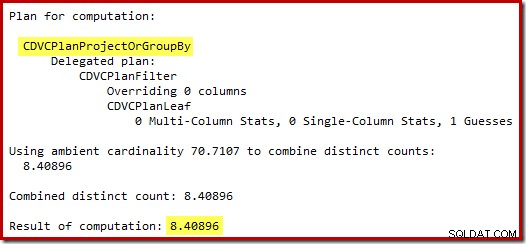
71 पंक्तियों का अनुमान (गोलाकार) एक बहुत ही दयनीय परिणाम है, लेकिन त्रुटि तब और बढ़ जाती है जब नया सीई उन 71 पंक्तियों पर अलग-अलग संचालन के लिए पंक्तियों का अनुमान लगाता है:
अपेक्षित 8 पंक्तियों के आधार पर, अनुकूलक नेस्टेड लूप्स रणनीति चुनता है। इन अनुमान त्रुटियों को देखने का दूसरा तरीका ट्रिगर बॉडी में निम्नलिखित कथन जोड़ना है (केवल परीक्षण उद्देश्यों के लिए):
हटाए गए से COUNT_BIG(DISTINCT RowID)चुनें;अनुमानित योजना अनुमान त्रुटियों को स्पष्ट रूप से दिखाती है:
वास्तविक योजना अभी भी निश्चित रूप से 5,000 पंक्तियों को दिखाती है:
या आप प्लान ट्री व्यू में एक ही समय में अनुमान बनाम वास्तविक की तुलना कर सकते हैं:
एक लाख पंक्तियां...
2014 के कार्डिनैलिटी एस्टीमेटर का उपयोग करते समय खराब अनुमान-अनुमान ऑप्टिमाइज़र को नेस्टेड लूप्स रणनीति का चयन करने का कारण बनते हैं, भले ही टेस्ट टेबल में एक लाख पंक्तियाँ हों। 2014 का नया सीई अनुमानित उस परीक्षण की योजना है:
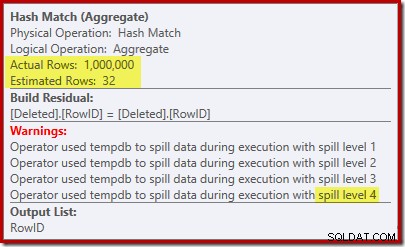
'सीक' 1,000,000 की ज्ञात कार्डिनैलिटी से 1,000 पंक्तियों का अनुमान लगाता है और विशिष्ट अनुमान 32 पंक्तियों का है। निष्पादन के बाद की योजना हैश मैच के लिए आरक्षित मेमोरी पर प्रभाव का खुलासा करती है:
केवल 32 पंक्तियों की अपेक्षा, हैश मैच वास्तविक संकट में पड़ जाता है, अंततः पूरा होने से पहले अपनी हैश तालिका को बार-बार फैलाता है।
अंतिम विचार
हालांकि यह सच है कि ट्रिगर को कभी भी ऐसा कुछ करने के लिए नहीं लिखा जाना चाहिए जिसे घोषणात्मक संदर्भात्मक अखंडता के साथ हासिल किया जा सके, यह भी सच है कि एक अच्छी तरह से लिखा गया ट्रिगर जो एक कुशल . का उपयोग करता है निष्पादन योजना एक अतिरिक्त गैर-संकुल सूचकांक बनाए रखने की लागत के प्रदर्शन में तुलनीय हो सकती है।
उपरोक्त कथन के साथ दो व्यावहारिक समस्याएं हैं। सबसे पहले (और दुनिया में सबसे अच्छी इच्छा के साथ) लोग हमेशा अच्छा ट्रिगर कोड नहीं लिखते हैं। दूसरा, सभी परिस्थितियों में क्वेरी ऑप्टिमाइज़र से एक अच्छी निष्पादन योजना प्राप्त करना कठिन हो सकता है। ट्रिगर्स की प्रकृति यह है कि उन्हें इनपुट कार्डिनैलिटी और डेटा वितरण की एक विस्तृत श्रृंखला के साथ बुलाया जाता है।
ट्रिगर के बाद भी, हटाए गए . पर अनुक्रमणिका और आंकड़ों की कमी और सम्मिलित छद्म तालिका का अर्थ है कि योजना का चयन अक्सर अनुमानों या गलत सूचना पर आधारित होता है। यहां तक कि जहां एक अच्छी योजना शुरू में चुनी जाती है, बाद में निष्पादन उसी योजना का पुन:उपयोग कर सकता है जब एक पुनर्मूल्यांकन बेहतर विकल्प होता। सीमाओं के आसपास काम करने के तरीके हैं, मुख्य रूप से अस्थायी तालिकाओं और स्पष्ट अनुक्रमणिका/सांख्यिकी के उपयोग के माध्यम से, लेकिन यहां तक कि बहुत सावधानी की आवश्यकता है (चूंकि ट्रिगर संग्रहीत प्रक्रिया का एक रूप है)।
ट्रिगर्स के बजाय, जोखिम और भी अधिक हो सकते हैं क्योंकि सम्मिलित की सामग्री और हटाया टेबल असत्यापित उम्मीदवार हैं - क्वेरी ऑप्टिमाइज़र अपनी निष्पादन योजना को सरल और परिष्कृत करने के लिए बेस टेबल पर बाधाओं का उपयोग नहीं कर सकता है। SQL सर्वर 2014 में नया कार्डिनैलिटी अनुमानक भी एक वास्तविक कदम पीछे की ओर दर्शाता है जब ट्रिगर योजनाओं के INSTEAD की बात आती है। एक खोज ऑपरेशन के प्रभाव का अनुमान लगाना कि इंजन ने खुद को पेश किया है, एक आश्चर्यजनक और अवांछित निरीक्षण है।