सामान्य तौर पर, लोग अवांछित ई-मेल प्राप्त करना पसंद नहीं करते हैं। फिर भी, वे कभी-कभी छूट पाने के लिए या नए उत्पादों के साथ अप-टू-डेट रहने के लिए न्यूज़लेटर्स की सदस्यता लेते हैं। यह आलेख न्यूज़लेटर डेटाबेस को डिज़ाइन करने के लिए एक दृष्टिकोण प्रस्तुत करेगा।
न्यूज़लेटर ईमेल के बारे में चिंता क्यों करें?
न्यूज़लेटर ग्राहक ग्राहकों के एक अत्यंत मूल्यवान समूह का प्रतिनिधित्व करते हैं - वे हमारे उत्पादों में रुचि रखते हैं, वे हम पर भरोसा करते हैं, और वे हमारे प्रस्तावों और प्रचारों की समीक्षा करने में समय बिताते हैं। क्या अधिक है, ग्राहकों को ईमेल भेजना ऑनलाइन मार्केटिंग के सबसे सस्ते साधनों में से एक है। हालांकि, इसे सावधानी से करने की आवश्यकता है - डेटा को दैनिक रूप से अपडेट किया जाना चाहिए (क्योंकि लोग सदस्यता लेते हैं और सदस्यता समाप्त करते हैं) और उच्च गुणवत्ता वाला होना चाहिए (हम अवांछित ईमेल नहीं भेजना चाहते, क्योंकि यह ब्रांड छवि को नकारात्मक रूप से प्रभावित करता है)।
ऐसे में सवाल उठता है कि गुणवत्ता डेटा प्राप्त करने और इसे प्रतिदिन अपडेट करने की इस प्रक्रिया को कैसे प्रबंधित किया जाए। बहुत सारे विकल्प हैं...
और विजेता है...
ग्राहक विश्लेषण! आजकल, प्रतिस्पर्धा में सबसे आगे रहने का सबसे महत्वपूर्ण कारक डेटा से अंतर्दृष्टि प्राप्त करना और उस आधार पर व्यावसायिक निर्णय लेना है। क्या न्यूज़लेटर भेजने के इतिहास को देखना और उनकी तीव्रता और प्रभावशीलता का विश्लेषण करना अच्छा नहीं होगा? प्रत्येक ग्राहक के लिए? और फिर इसे क्रय डेटा के साथ शामिल करें, ग्राहक के हितों को उजागर करें, व्यक्तिगत सिफारिशें तैयार करें, और व्यक्तिगत ई-मेल का उपयोग करके इन्हें भेजें?
इस तरह के दृष्टिकोण से निश्चित रूप से हमारी रूपांतरण दर (सीआर) में वृद्धि होगी। रूपांतरण दर सबसे महत्वपूर्ण ऑनलाइन मार्केटिंग प्रमुख प्रदर्शन संकेतकों में से एक है; यह दिखाता है कि हमारी कुछ प्रचार सामग्री (विज्ञापन, समाचार पत्र, आदि) को देखने के बाद कितने लोग खरीदारी करते हैं। उच्च सीआर का अर्थ है व्यवसाय की प्रभावशीलता में वृद्धि।
अब जब हम इसमें शामिल कुछ मार्केटिंग को समझ गए हैं, तो आइए डेटा मॉडल में आते हैं!
आइए न्यूज़लेटर डेटाबेस की मॉडलिंग शुरू करें!
सही में खुदाई करने पर, हम देखते हैं कि मॉडल में दो मुख्य टेबल हैं client और newsletter टेबल।
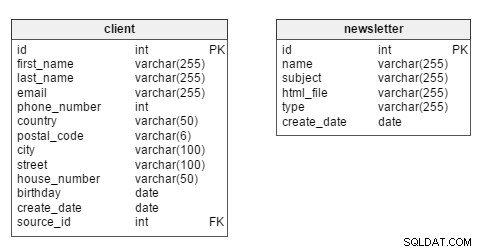
चूंकि हम अधिकतर क्लाइंट विश्लेषण में रुचि लेंगे, client टेबल मॉडल के केंद्र में रहना चाहिए। इस तालिका में, प्रत्येक क्लाइंट का अपना विशिष्ट id होता है . हम ऐसी जानकारी को क्लाइंट के first_name . के रूप में भी स्टोर करेंगे और last_name , संपर्क जानकारी (email , phone_number , सड़क का पता), birthday , create_date (जब ग्राहक का रिकॉर्ड डेटाबेस में दर्ज किया गया था) और उनका source_id - यानी चाहे वे हमारी साइट पर पंजीकृत हों या किसी व्यावसायिक भागीदार ने हमें अपना डेटा प्रदान किया हो।
newsletter टेबल प्रत्येक न्यूज़लेटर निर्माण से संबंधित डेटा संग्रहीत करता है। न्यूज़लेटर्स की पहचान उनके विशिष्ट id . के आधार पर की जा सकती है . प्रत्येक का वर्णन name . द्वारा किया गया है (उदाहरण के लिए "नई महिलाओं के कपड़ों का संग्रह - शरद ऋतु 2016"), ईमेल subject ("उसके लिए सबसे फैशनेबल कपड़े - अभी खरीदें!"), html_file (उस विशेष न्यूज़लेटर के लिए HTML कोड वाली फ़ाइल), न्यूज़लेटर type (जैसे "नया संग्रह", "जन्मदिन न्यूज़लेटर") और create_date ।
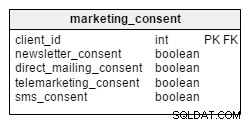
विपणन सहमति
विपणन जानकारी (डाक, टेलीफोन, ईमेल या एसएमएस द्वारा) भेजने के लिए, एक कंपनी को अपने ग्राहकों से सहमति प्राप्त करने की आवश्यकता होती है। हमारे मॉडल में, सहमति marketing_consent . यह हमारे सभी ग्राहकों के लिए विपणन सहमति के वर्तमान सेट के बारे में जानकारी रखता है। सहमति को बूलियन चर के रूप में कोडित किया जाता है - TRUE (विपणन संचार के लिए सहमत) या FALSE (सहमत नहीं है)।
जब ग्राहक प्रत्येक संचार चैनल के माध्यम से विज्ञापन प्राप्त करने के लिए सहमत होता है, तो इस बारे में जानकारी संग्रहीत करना बहुत महत्वपूर्ण है। यह रिकॉर्ड करना भी फायदेमंद होता है कि उन्होंने प्रत्येक चैनल के लिए अपनी सहमति कब वापस ली। ऐसे उद्देश्यों के लिए, consent_change टेबल डिजाइन किया गया था।
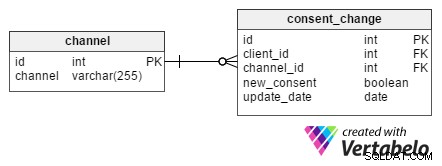
प्रत्येक परिवर्तन का एक अद्वितीय id होता है और किसी विशेष क्लाइंट को उनके client_id . द्वारा असाइन किया जाता है . जब कोई क्लाइंट न्यूज़लेटर ईमेल से निकालने का अनुरोध करता है, तो न्यूज़लेटर id channel तालिका consent_change तालिका का channel_id गुण। new_consent विशेषता एक बूलियन मान (TRUE या FALSE) है और नई मार्केटिंग सहमति का प्रतिनिधित्व करती है।
update_date कॉलम में वह तिथि होती है जब ग्राहक ने परिवर्तन का अनुरोध किया था। यह संरचना हमें किसी दिए गए दिन सभी ग्राहकों के लिए सहमति का एक सेट निकालने की अनुमति देती है। यह बेहद उपयोगी है यदि कोई ग्राहक हमारे न्यूज़लेटर से पहले ही सदस्यता समाप्त करने के बाद ई-मेल प्राप्त करने के बारे में शिकायत करता है। फ़ाइल में इस जानकारी के साथ, हम जांच सकते हैं कि सदस्यता कब समाप्त हुई और उम्मीद है कि ईमेल न्यूज़लेटर भेजे जाने के बाद यह पुष्टि की गई थी।
सेंड-आउट को क्रम में रखना
न्यूजलेटर भेजने के लिए एक आदर्श डेटाबेस मॉडल डिजाइन करना केक का एक टुकड़ा नहीं है। क्यों? खैर, स्पष्ट रूप से हमें किसी एकल न्यूज़लेटर निर्माण (अर्थात् लेआउट, ग्राफिक्स, उत्पाद, लिंक, आदि) की पहचान करने में सक्षम होने की आवश्यकता है। हम यह भी जानते हैं कि एक रचना को कई बार भेजा जा सकता है:प्रबंधक यह तय कर सकते हैं कि एक बाल्टी ई-मेल सुबह आधे ग्राहकों को और शाम को दूसरे आधे ग्राहकों को भेजी जाएगी। इसलिए यह रिकॉर्ड करना महत्वपूर्ण है कि किन ग्राहकों को कौन सा समाचार पत्र प्राप्त हुआ और कब। यही कारण है कि मॉडल के इस हिस्से में तीन टेबल होते हैं:
- द
newsletterतालिका - जिसका हमने पहले वर्णन किया था। - द
newsletter_sendoutतालिका - जो एकल प्रेषण की पहचान करती है। उदाहरण के लिए, क्रिसमस न्यूज़लेटर (id .) =“2512”) को 10 दिसंबर को शाम 6 बजे ईमेल किया गया था। यह रिकॉर्ड-कीपिंग विपणक को अलग-अलग समय पर ग्राहकों के अलग-अलग समूहों को एक ही न्यूज़लेटर भेजने की अनुमति देता है। - द
sendout_receiversतालिका - जो प्रत्येक प्रेषण के प्राप्तकर्ताओं के बारे में डेटा एकत्र करती है। प्रत्येक प्रेषण से प्रत्येक ईमेल के लिए एक रिकॉर्ड होगा। प्रत्येक पंक्ति में तीन कॉलम होते हैं:id(क्लाइंट को ईमेल भेजने की घटना की पहचान करना),client_id(हमारे डेटाबेस से क्लाइंट की पहचान करना) औरnl_sendout_id(एक न्यूज़लेटर भेजने की पहचान करना)।
यहां संपूर्ण न्यूज़लेटर मॉडल है:
इस मॉडल को बेहतर बनाने के बारे में कोई सुझाव?
एक संभावित तरीका response टेबल। यह ग्राहकों की प्रतिक्रियाओं को संग्रहीत करेगा - चाहे उन्होंने ई-मेल खोला, विज्ञापन पर क्लिक किया, या संदेश को कभी नहीं देखा क्योंकि इसे स्पैम के रूप में चिह्नित किया गया था। हमें response हमारे मॉडल के लिए तालिका और कौन सा संबंध लागू किया जाना चाहिए? अपने विचार नीचे कमेंट सेक्शन में साझा करें।