अगर किराने का सामान ऑनलाइन ऑर्डर करने का कोई तरीका है, तो इसका इस्तेमाल क्यों न करें? यह लेख किराने की दुकान के वितरण प्रणाली के पीछे के डेटा मॉडल की जांच करता है।
हम अभी भी बगीचे से कुछ लेने और फिर इसे तुरंत तैयार करने से एक विशेष भावना प्राप्त करते हैं - लेकिन यह ऐसा कुछ नहीं है जिसे हम अक्सर कर सकते हैं। आज की तेज रफ्तार इसकी इजाजत नहीं देती। वास्तव में, कभी-कभी यह हमें अपनी किराने का सामान "पिक" करने के लिए स्टोर पर जाने की अनुमति भी नहीं देता है। इसलिए यह समझ में आता है कि अपने आप को कुछ समय बचाएं और एक ऐप का उपयोग करके ऑर्डर करें कि हमें क्या चाहिए। हमारा ऑर्डर हमारे घर पर ही दिखाई देगा। हो सकता है कि हमें वह विशेष ताज़ा एहसास न मिले, लेकिन हमारी मेज पर खाना होगा।
इस तरह के एक आवेदन के पीछे डेटा मॉडल आज के लेख का विषय है।
किराने की डिलीवरी डेटा मॉडल के लिए हमें क्या चाहिए?
इस मॉडल का विचार यह है कि एक एप्लिकेशन (वेब, मोबाइल, या दोनों) पंजीकृत ग्राहकों को एक ऑर्डर (हमारे स्टोर से उत्पादों से बना) बनाने की अनुमति देगा। फिर यह ऑर्डर ग्राहक को डिलीवर किया जाएगा। हम स्पष्ट रूप से इसका समर्थन करने के लिए ग्राहक डेटा और सभी उपलब्ध उत्पादों की सूची संग्रहीत करेंगे।
ग्राहक कई ऑर्डर दे सकते हैं जिनमें अलग-अलग मात्रा में अलग-अलग आइटम शामिल हैं। जब ग्राहक का आदेश प्राप्त होता है, तो स्टोर के कर्मचारियों को सूचित किया जाना चाहिए ताकि वे आवश्यक वस्तुओं को ढूंढ और पैक कर सकें। (इसके लिए एक या अधिक कंटेनरों की आवश्यकता हो सकती है।) अंत में, कंटेनरों को एक साथ या अलग से वितरित किया जाएगा।
ऐप में ही, ग्राहक और कर्मचारी डिलीवरी के बाद नोट डालने और दूसरे पक्ष को रेट करने में सक्षम होना चाहिए।
डेटा मॉडल
डेटा मॉडल में तीन विषय क्षेत्र होते हैं:
Items & unitsCustomers & employeesOrders
हम प्रत्येक विषय क्षेत्र को सूचीबद्ध क्रम में प्रस्तुत करेंगे।
अनुभाग 1:आइटम और इकाइयां
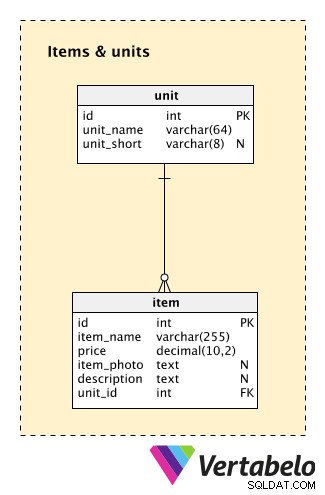
हम Items & units विषय क्षेत्र। हालांकि यह हमारे मॉडल का एक छोटा सा हिस्सा है, लेकिन इसमें दो बहुत ही महत्वपूर्ण टेबल हैं।
unit तालिका उन इकाइयों के बारे में जानकारी संग्रहीत करती है जिन्हें हम अपनी सूची में किसी भी आइटम को असाइन करेंगे। इस तालिका में प्रत्येक मान के लिए, हम दो अद्वितीय मान संग्रहीत करेंगे:unit_name (जैसे "किलोग्राम") और unit_short (जैसे "किलो")। ध्यान दें कि unit_short unit_name . का संक्षिप्त नाम है ।
इस विषय क्षेत्र में दूसरी तालिका है item . यह उन सभी वस्तुओं को सूचीबद्ध करता है जो हमारे पास सूची में हैं। प्रत्येक आइटम के लिए, हम स्टोर करेंगे:
item_name- उस आइटम के लिए हम जिस UNIQUE नाम का उपयोग करेंगे।price- उस वस्तु की वर्तमान कीमत।item_photo- इस आइटम की एक तस्वीर का लिंक।description- वस्तु का अतिरिक्त पाठ्य विवरण।unit_id- संदर्भunitशब्दकोश और उस वस्तु को मापने के लिए प्रयुक्त इकाई को दर्शाता है।
कृपया ध्यान दें कि मैंने यहां कुछ चीजें छोड़ी हैं। सबसे महत्वपूर्ण एक ध्वज है जो दर्शाता है कि वर्तमान में बिक्री के लिए एक सूची वस्तु की पेशकश की जा रही है या नहीं। हमारे पास यह क्यों नहीं है? इसके लिए कम से कम एक अतिरिक्त फ़ील्ड (ध्वज) के साथ-साथ एक अन्य तालिका (प्रत्येक आइटम के लिए ऐतिहासिक परिवर्तनों को संग्रहीत करने के लिए) की आवश्यकता होगी। चीजों को सरल रखने के लिए, मैंने मान लिया कि हमारे पास इन्वेंट्री में मौजूद सभी आइटम भी बेचने के लिए उपलब्ध हैं।
दूसरी महत्वपूर्ण बात जो मैंने छोड़ी है वह है वेयरहाउस की स्थिति पर नज़र रखना। मेरी धारणा यह है कि हम एक केंद्रीय गोदाम से सब कुछ शिप करते हैं और हमारे पास हमेशा उपलब्ध आइटम होंगे। अगर हमारे पास कोई आइटम नहीं है, तो हम बस ग्राहक को सूचित करेंगे और बदले में उन्हें एक समान आइटम की पेशकश करेंगे।
अनुभाग 2:ग्राहक और कर्मचारी

Customers & employees विषय क्षेत्र में ग्राहक और कर्मचारी डेटा संग्रहीत करने के लिए आवश्यक सभी तालिकाएँ होती हैं। हम इस जानकारी का उपयोग अपने मॉडल के मध्य भाग में करेंगे।
employee तालिका में सभी प्रासंगिक कर्मचारियों (जैसे किराना पैकर और डिलीवरी करने वाले लोग) की एक सूची है। प्रत्येक कर्मचारी के लिए, हम उनका first_name स्टोर करेंगे और last_name और एक अद्वितीय employee_code मूल्य। हालांकि आईडी कॉलम भी अद्वितीय है (और इस तालिका की प्राथमिक कुंजी), कर्मचारी पहचानकर्ता के रूप में एक और, वास्तविक दुनिया मूल्य (उदाहरण के लिए एक वैट संख्या) का उपयोग करना बेहतर है। इस प्रकार हमारे पास employee_code है फ़ील्ड.
ध्यान दें कि मैंने कर्मचारी लॉगिन विवरण, कर्मचारी भूमिकाएं और भूमिका इतिहास को ट्रैक करने का एक तरीका शामिल नहीं किया है। जैसा कि इस लेख में बताया गया है, इन्हें आसानी से जोड़ा जा सकता है।
अब हम अपने मॉडल में ग्राहकों को जोड़ेंगे। इसमें दो और टेबल लगेंगे।
ग्राहकों को भौगोलिक रूप से विभाजित किया जाएगा, इसलिए हमें एक city शब्दकोश। प्रत्येक शहर के लिए जहां हम किराने की डिलीवरी की पेशकश करते हैं, हम city_name . को स्टोर करेंगे और postal_code . ये सभी मिलकर इस तालिका की वैकल्पिक कुंजी बनाते हैं।
ग्राहक निश्चित रूप से इस मॉडल का सबसे महत्वपूर्ण हिस्सा हैं; वे ही हैं जो पूरी प्रक्रिया शुरू करते हैं। हम अपने ग्राहकों की पूरी सूची customer टेबल। प्रत्येक ग्राहक के लिए, हम निम्नलिखित स्टोर करेंगे:
first_name- ग्राहक का पहला नाम।last_name- ग्राहक का उपनाम।user_name- अपना खाता सेट करते समय ग्राहक द्वारा चुना गया उपयोगकर्ता नाम।password- वह पासवर्ड जिसे ग्राहक ने अपना खाता सेट करते समय चुना था।time_inserted- वह क्षण जब यह रिकॉर्ड डेटाबेस में डाला गया था।confirmation_code- एक कोड जो पंजीकरण कोड के दौरान उत्पन्न हुआ था। इस कोड का उपयोग उनके ईमेल पते को सत्यापित करने के लिए किया जाएगा।time_confirmed- जब ईमेल की पुष्टि हुई।contact_email- ग्राहक का ईमेल पता, जिसका उपयोग पुष्टिकरण ईमेल के रूप में भी किया जाता है।contact_phone- ग्राहक का फोन नंबर।city_id-cityजहां ग्राहक रहता है।address- ग्राहक के घर का पता।delivery_city_id-cityजहां ग्राहक का ऑर्डर डिलीवर किया जाना चाहिए।delivery_address- पसंदीदा वितरण पता। ध्यान दें कि यह ग्राहक के घर के पते के समान (लेकिन होना जरूरी नहीं) हो सकता है।
अनुभाग 3:आदेश
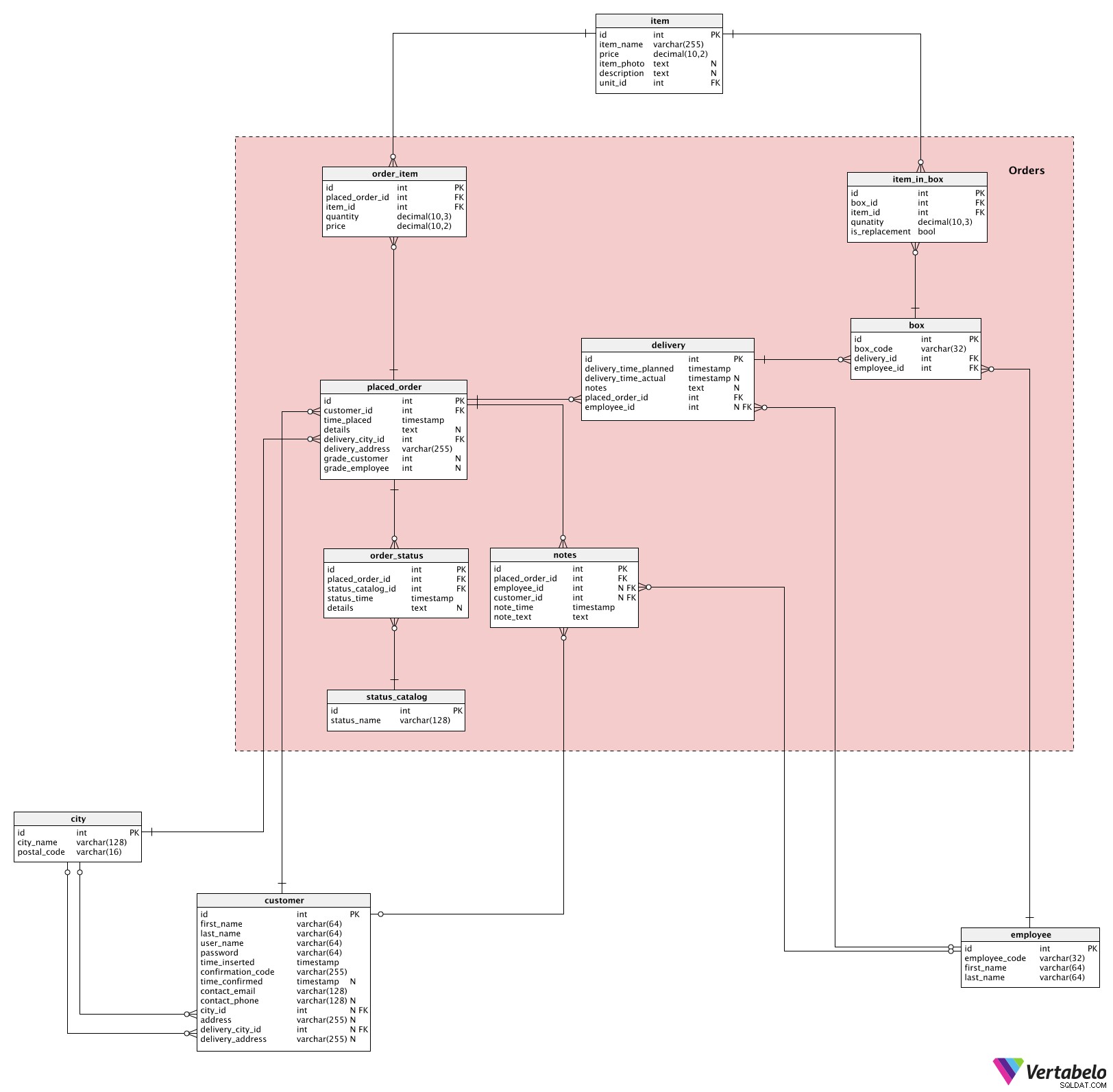
इस मॉडल का केंद्रीय और सबसे महत्वपूर्ण हिस्सा है Orders विषय क्षेत्र। यहां हम ऑर्डर देने के लिए और ग्राहकों को आइटम डिलीवर होने तक ट्रैक करने के लिए आवश्यक सभी टेबल पाएंगे।
पूरी प्रक्रिया तब शुरू होती है जब कोई ग्राहक ऑर्डर देता है। अब तक दिए गए प्रत्येक आदेश की सूची placed_order टेबल। मैंने जानबूझकर इस नाम का उपयोग किया है न कि "आदेश" क्योंकि आदेश एक SQL आरक्षित कीवर्ड है। प्रत्येक ऑर्डर के लिए, हम स्टोर करेंगे:
customer_id-customerजिसने यह आदेश दिया है।time_placed- टाइमस्टैम्प जब यह आदेश दिया गया था।description- उस आदेश से संबंधित सभी विवरण, असंरचित पाठ्य प्रारूप में।delivery_city_id-cityजहां यह आदेश दिया जाना चाहिए।delivery_address- वह पता जहां यह आदेश दिया जाना चाहिए।grade_customer&grade_employee- एक आदेश पूरा होने के बाद कर्मचारी और ग्राहक द्वारा दिए गए ग्रेड। उस क्षण तक, इस विशेषता में एक NULL मान होता है। एक ग्राहक का ग्रेड दर्शाता है कि वे हमारी सेवा से कितने खुश थे; एक कर्मचारी का ग्रेड हमें इस बारे में जानकारी देता है कि अगली बार ग्राहक द्वारा ऑर्डर देने पर क्या उम्मीद की जाए।
ऑर्डर देने की प्रक्रिया के दौरान, ग्राहक एक या अधिक आइटम का चयन करेगा। प्रत्येक आइटम के लिए, वे एक वांछित मात्रा निर्धारित करेंगे। प्रत्येक आदेश से संबंधित सभी मदों की सूची order_item टेबल। इस तालिका में प्रत्येक रिकॉर्ड के लिए, हम संबंधित ऑर्डर के लिए आईडी स्टोर करेंगे (placed_order_id ), आइटम (item_id ), वांछित मात्रा, और price जब यह आदेश दिया गया था।
क्या . के अलावा वे डिलीवर करना चाहते हैं, ग्राहक अपनी वांछित डिलीवरी समय . को भी परिभाषित करेंगे . प्रत्येक आदेश के लिए, हम delivery टेबल। यह delivery_time_planned . रिकॉर्ड करेगा और अतिरिक्त टेक्स्ट नोट्स डालें। placed_order_id यह रिकॉर्ड डालने पर विशेषता भी परिभाषित की जाएगी। शेष दो विशेषताओं को तब परिभाषित किया जाएगा जब हम उस डिलीवरी को किसी कर्मचारी (employee_id) को सौंपेंगे। ) और जब ऑर्डर दिया गया था (delivery_time_actual )।
हालांकि ऐसा लग सकता है कि हमारे पास प्रति ऑर्डर केवल एक डिलीवरी होगी, ऐसा हमेशा नहीं हो सकता है। हमें प्रति ऑर्डर दो या अधिक डिलीवरी करने की आवश्यकता हो सकती है, और यही मुख्य कारण है कि मैंने डिलीवरी डेटा को एक नई तालिका में रखना चुना।
जब हम किसी ऑर्डर को प्रोसेस करना शुरू करते हैं, तो कर्मचारी आइटम को एक या अधिक बॉक्स में पैक करेंगे। प्रत्येक box इसके box_code . द्वारा UNIQUELY परिभाषित किया जाएगा और एक डिलीवरी को सौंपा जाएगा (delivery_id ) हम उस बॉक्स को तैयार करने वाले कर्मचारी की आईडी भी स्टोर करेंगे।
प्रत्येक बॉक्स में एक या अधिक आइटम होंगे। इसलिए, item_in_box तालिका में, हमें संदर्भों को box तालिका (box_id ) और item तालिका (item_id ), साथ ही उस बॉक्स में रखी गई मात्रा। अंतिम विशेषता, is_replacement , इंगित करता है कि कोई आइटम किसी अन्य आइटम के लिए प्रतिस्थापन है या नहीं। हम उम्मीद कर सकते हैं कि एक कर्मचारी एक बॉक्स में प्रतिस्थापन आइटम डालने से पहले एक ग्राहक से संपर्क करेगा। उस कार्रवाई का एक परिणाम यह हो सकता है कि ग्राहक प्रतिस्थापन वस्तु से सहमत हो; दूसरा पूरे आदेश को रद्द करना हो सकता है।
मॉडल में शेष तीन तालिकाएं स्थितियों और टिप्पणियों से निकटता से संबंधित हैं।
सबसे पहले, हम सभी संभावित स्थितियों को status_catalog . प्रत्येक स्थिति को उसके status_name . द्वारा विशिष्ट रूप से परिभाषित किया जाता है . हम "ऑर्डर बनाया गया", "ऑर्डर दिया गया", "पैक किए गए आइटम", "ट्रांज़िट में" और "डिलीवर" जैसी स्थितियों की अपेक्षा कर सकते हैं।
आदेश को या तो स्वचालित रूप से (प्रक्रिया के कुछ भाग पूर्ण होने के बाद) या, कुछ मामलों में, मैन्युअल रूप से (उदाहरण के लिए, यदि आदेश में कोई समस्या है) स्थितियाँ असाइन की जाएंगी। सभी उपलब्ध ऑर्डर स्थितियां order_status टेबल। दो तालिकाओं से विदेशी कुंजियों के अलावा (status_catalog और placed_order ), जब यह स्थिति असाइन की गई थी, तब हम वास्तविक टाइमस्टैम्प संग्रहीत करेंगे (status_time ) और कोई अतिरिक्त description पाठ्य प्रारूप में।
इस मॉडल में अंतिम तालिका notes टेबल। इस तालिका के पीछे विचार किसी दिए गए आदेश से संबंधित सभी अतिरिक्त टिप्पणियों को सम्मिलित करना है (placed_order_id ) टिप्पणियां कर्मचारियों या ग्राहकों द्वारा डाली जा सकती हैं। प्रत्येक रिकॉर्ड के लिए, employee_id . में से केवल एक या customer_id फ़ील्ड में एक मान होगा; दूसरा NULL होगा। जब यह नोट सिस्टम में डाला गया था तब हम उस पल को सहेज लेंगे (note_time ) और note_text ।
किराने के वितरण डेटा मॉडल में आप क्या परिवर्तन करेंगे?
आज हमने एक डेटा मॉडल पर चर्चा की जो वेब और मोबाइल ग्रॉसरी डिलीवरी ऐप को सपोर्ट कर सकता है - ग्राहक और कर्मचारी दोनों के दृष्टिकोण से। जैसा कि इस लेख में पहले ही उल्लेख किया गया है, इस मॉडल को बेहतर बनाने के कई तरीके हैं। अपने सुझाव जोड़ने के लिए स्वतंत्र महसूस करें। हमें बताएं कि आप इस मॉडल में क्या जोड़ेंगे या इसमें से क्या हटाएंगे। या हो सकता है कि आप इस संरचना को पूरी तरह से अलग तरीके से व्यवस्थित करें। हमें कमेंट सेक्शन में बताएं!