अर्ध-पहचानकर्ता, या अप्रत्यक्ष पहचानकर्ता, व्यक्तिगत गुण हैं जो किसी व्यक्ति के बारे में सत्य हैं, लेकिन जरूरी नहीं कि अद्वितीय हों। उदाहरण किसी की उम्र या जन्म तिथि, जाति, वेतन, शैक्षिक प्राप्ति, व्यवसाय, वैवाहिक स्थिति और ज़िप कोड हैं। किसी व्यक्ति का पूरा कानूनी नाम, ईमेल पता, फ़ोन नंबर, राष्ट्रीय आईडी, पासपोर्ट या क्रेडिट कार्ड नंबर आदि जैसे प्रत्यक्ष, विशिष्ट पहचानकर्ताओं के साथ इनकी तुलना करें।
अधिकांश उपभोक्ता पहले से ही अपनी अनूठी, व्यक्तिगत रूप से पहचान योग्य जानकारी (पीआईआई) साझा करने के जोखिमों से अवगत हैं। डेटा सुरक्षा उद्योग आमतौर पर उन प्रत्यक्ष पहचानकर्ताओं पर भी केंद्रित होता है। लेकिन सिर्फ लिंग, जन्मतिथि और ज़िप कोड के साथ, अमेरिका की 80-90% आबादी की पहचान की जा सकती है।
यदि पर्याप्त अप्रत्यक्ष पहचानकर्ता बने रहें और समान मूल्यों वाले सुपरसेट आबादी में शामिल हों, तो लगभग किसी को भी अन्यथा नकाबपोश डेटा सेट से फिर से पहचाना जा सकता है।
छात्र डेटा गोपनीयता के संबंध में संरक्षित स्वास्थ्य सूचना (पीएचआई) और एफईआरपीए कानून से संबंधित एचआईपीएए विशेषज्ञ निर्धारण विधि नियम इन चिंताओं पर विचार करता है और यह आवश्यक है कि डेटासेट में पुन:पहचान की सांख्यिकीय रूप से कम संभावना हो (आज 20% से नीचे मानक है)। अनुसंधान और/या विपणन उद्देश्यों के लिए स्वास्थ्य देखभाल और शैक्षिक डेटा का उपयोग करने के इच्छुक लोगों को उन कानूनों का पालन करना होगा, लेकिन डेटा के मूल्यवान होने के लिए अर्ध-पहचानकर्ताओं की जनसांख्यिकीय सटीकता पर भी भरोसा करना होगा।
इस कारण से, IRI FieldShield उत्पाद या IRI Voracity (डेटा प्रबंधन प्लेटफ़ॉर्म) में डेटा मास्किंग कार्य डेटा को अस्पष्ट करने के लिए एक या अधिक अतिरिक्त तकनीकों को लागू कर सकते हैं, जबकि अभी भी इसे अनुसंधान या विपणन उद्देश्यों के लिए पर्याप्त रूप से सटीक रखते हैं। उदाहरण के लिए, संख्यात्मक धुंधला कार्य निर्दिष्ट आयु और दिनांक सीमाओं के लिए यादृच्छिक शोर पैदा करते हैं, जैसा कि इस आलेख में वर्णित है।
यहां लेख के आधार पर, यह उदाहरण दिखाएगा कि कैसे आईआरआई वर्कबेंच अर्ध-पहचानकर्ताओं को अज्ञात करने के लिए सेट फाइलों का निर्माण और उपयोग कर सकता है।
बकेटिंग के माध्यम से सामान्यीकरण . में प्रारंभ करें विजार्ड, डेटा सुरक्षा नियमों की सूची से उपलब्ध:

विज़ार्ड खुलने के बाद, सेट फ़ाइल के लिए मानों के स्रोत को परिभाषित करना शुरू करें, जिसमें स्रोत प्रारूप और एक सामान्यीकृत प्रतिस्थापन मान की आवश्यकता वाली फ़ील्ड शामिल है।

अगले पृष्ठ पर, दो प्रकार के सेट फ़ाइल प्रतिस्थापन हैं:सेट फ़ाइल को समूह के रूप में उपयोग करें और सेट फ़ाइल को श्रेणी के रूप में उपयोग करें विकल्प। यह उदाहरण सेट फ़ाइल को समूह के रूप में उपयोग करें . का उपयोग करता है विकल्प। डेटा धुंधलापन पर लेख सेट फ़ाइलों को एक श्रेणी के रूप में उपयोग करें . को प्रदर्शित करता है विकल्प। यहां बनाए गए लुकअप सेट का उपयोग मूल अर्ध-पहचानकर्ताओं को नए सामान्यीकरण मान के साथ छद्म नाम देने के लिए किया जाएगा।
यह पृष्ठ वह जगह है जहां प्रत्येक मूल अर्ध-पहचान वाले फ़ील्ड मानों के बीच समूह बनाए जाते हैं। बाईं ओर पहले से चयनित फ़ील्ड में अद्वितीय मान हैं। समूहों को या तो बाईं ओर समूह मानों को खींचकर और छोड़ कर, या मैन्युअल रूप से मान दर्ज करके बनाया जा सकता है। प्रत्येक समूह को एक अद्वितीय प्रतिस्थापन मूल्य की भी आवश्यकता होती है। यह वह मान है जो समूह में मूल मान को बदल देगा। इस उदाहरण में, "9वीं" के किसी भी मान को "हाई स्कूल" से बदल दिया जाएगा।

जब तक सभी स्रोत मान शामिल नहीं हो जाते तब तक समूहों को जोड़ने से शिक्षा स्थिति अर्ध-पहचानकर्ता को अज्ञात करने के लिए निम्न लुकअप सेट फ़ाइल तैयार होती है:

यदि बकेटिंग के अतिरिक्त स्तरों की आवश्यकता होती है, तो स्रोत के रूप में इस सेट फ़ाइल का उपयोग करके बकेटिंग विज़ार्ड फिर से चलाया जा सकता है।
जब डेटा अनामीकरण कार्य में सेट फ़ाइल का उपयोग किया जाता है, तो स्रोत डेटा की तुलना सेट फ़ाइल के पहले कॉलम के मानों से की जाती है। यदि कोई मिलान मिलता है, तो डेटा को दूसरे कॉलम में मान से बदल दिया जाता है। उपरोक्त सेट फ़ाइल का उपयोग नीचे की स्क्रिप्ट में लाइन 38 पर किया गया है।
पांच अलग-अलग गुमनामी तकनीकों को लागू करने के लिए कार्यक्षेत्र का उपयोग करने से निम्नलिखित स्क्रिप्ट प्राप्त होती है:

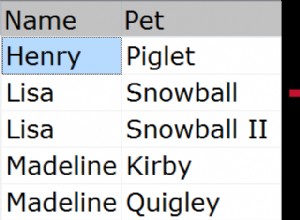
मूल डेटा की पहली दस पंक्तियां यहां दिखाई गई हैं:

कार्य चलाने के बाद अज्ञात परिणाम यहां दिखाए गए हैं:

इन सामान्यीकरणों से पहले, मूल परोक्ष रूप से पहचान करने वाले मूल्यों के आधार पर पुन:पहचान का जोखिम बहुत अधिक था। लेकिन जब अधिक सामान्यीकृत परिणाम सेट को पुन:पहचान जोखिम का एक और निर्धारण उत्पन्न करने के लिए जोखिम स्कोरिंग विज़ार्ड के माध्यम से फिर से चलाया जाता है, तो जोखिम स्वीकार्य होता है और डेटा अभी भी अनुसंधान या विपणन उद्देश्यों के लिए उपयोगी होता है।
यदि इन कार्यों या रि-आईडी जोखिम स्कोरिंग के बारे में आपके कोई प्रश्न हैं, तो संपर्क करें।